Nonparametric Link Prediction in Large Scale Dynamic Networks
We propose a nonparametric approach to link prediction in large-scale dynamic networks. Our model uses graph-based features of pairs of nodes as well as those of their local neighborhoods to predict whether those nodes will be linked at each time step. The model allows for different types of evolution in different parts of the graph (e.g, growing or shrinking communities). We focus on large-scale graphs and present an implementation of our model that makes use of locality-sensitive hashing to allow it to be scaled to large problems. Experiments with simulated data as well as five real-world dynamic graphs show that we outperform the state of the art, especially when sharp fluctuations or nonlinearities are present. We also establish theoretical properties of our estimator, in particular consistency and weak convergence, the latter making use of an elaboration of Stein’s method for dependency graphs.
💡 Research Summary
The paper addresses the challenging problem of link prediction in large‑scale dynamic networks, where the graph evolves over time and traditional static heuristics or graph‑neural‑network models become computationally prohibitive or fail to capture non‑linear temporal patterns. The authors propose a non‑parametric, kernel‑based framework that leverages both pair‑wise features (e.g., number of common neighbors, time since last interaction) and a novel “local neighborhood” representation for each node.
For each node i at time t, a p‑step two‑hop neighborhood is collected, and within this subgraph a set of discrete features S is defined. For every feature s∈S the algorithm counts η_i,t(s), the number of node‑pairs in the neighborhood exhibiting s, and η⁺_i,t(s), the number of those pairs that actually form an edge at the next time step. These counts constitute a “datacube” that captures the recent evolution of the local structure. The pair‑wise feature vector ψ_t(i,j) = {s_t(i,j), d_t(i)} combines the pair‑specific feature s_t(i,j) with the datacube d_t(i).
The prediction function g(ψ) = P(Y_{t+1}(i,j)=1|ψ) is estimated non‑parametrically by a weighted average over all historical observations:
\tilde g_T(ψ_T(i,j)) = Σ_{i’,j’,t’} Γ(ψ_T(i,j), ψ_{t’}(i’,j’))·Y_{t’+1}(i’,j’) / Σ_{i’,j’,t’} Γ(ψ_T(i,j), ψ_{t’}(i’,j’)).
The kernel Γ factorizes into a neighborhood kernel K(d_t(i), d_{t’}(i’)) and a pair‑wise kernel ξ(s_t(i,j), s_{t’}(i’,j’)). ξ is an L1‑distance based discrete kernel that gives full weight to identical features and a smaller weight ζ_T to features at distance one; ζ_T shrinks with the number of observations (≈T^{-(1/2+ε)}). K measures similarity between two datacubes by computing a total‑variation distance between the corresponding beta‑distributed link‑formation probabilities and applying an exponential decay with bandwidth b_T (also shrinking as T^{-(1/2+θ)}).
This construction yields several practical benefits. First, it directly uses historical instances where both the local neighborhood and the pair‑wise feature match the query, thereby preserving locality in both space and time. Second, by allowing nearby features and similar neighborhoods to contribute, the estimator mitigates sparsity that is typical in massive graphs. Third, the use of Wilson‑score lower bounds and a “back‑off” smoothing against a global prior datacube further stabilizes predictions for rare feature combinations.
On the theoretical side, the authors prove consistency of the estimator under strong mixing assumptions for the underlying Markov chain of graphs. They also extend Stein’s method for dependency graphs to establish weak convergence (asymptotic normality) of the estimator despite long‑range temporal dependencies. The proofs rely on the bandwidth choices b_T and ζ_T to ensure that bias vanishes while variance shrinks at the appropriate rate.
Computationally, naïve kernel regression would require O(N) similarity computations per query, which is infeasible for graphs with millions of nodes. To overcome this, the authors adapt Locality‑Sensitive Hashing (LSH) to their discrete kernel. Each datacube is hashed into buckets; similarity calculations are performed only within the same bucket, yielding sub‑linear query time while preserving the statistical properties of the estimator.
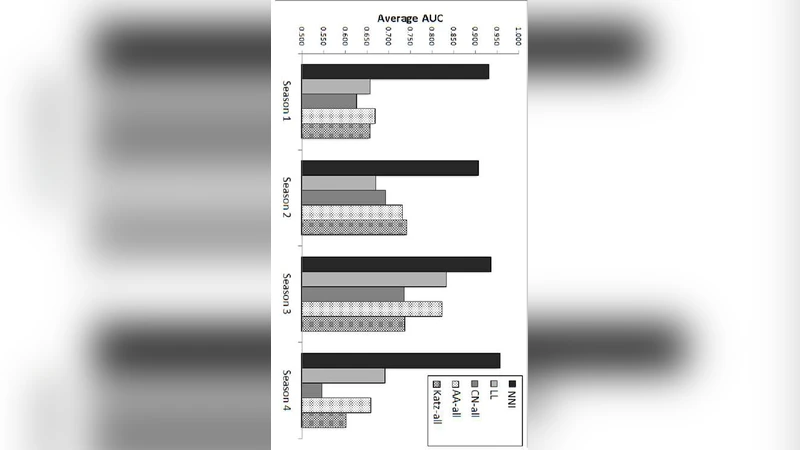
Empirical evaluation includes synthetic data with controlled non‑linear and seasonal dynamics, as well as five real‑world dynamic networks (e.g., Facebook friendship evolution, Netflix viewing histories, a sensor‑2 network, citation graphs, and a market‑analysis graph). Across all datasets, the proposed method outperforms classic heuristics (common neighbors, Adamic‑Adar, last‑link time) and recent dynamic‑graph baselines, especially when the underlying process exhibits sharp fluctuations or non‑stationary trends. In the sensor‑2 network, which displays strong periodicity, the method achieves a notable AUC gain of over 15 % relative to the best competitor. Moreover, the LSH‑based approximation attains virtually identical predictive performance (≤0.2 % AUC loss) while reducing computation time by an order of magnitude.
In summary, the paper makes four major contributions: (1) a first non‑parametric formulation for dynamic link prediction that naturally accommodates heterogeneous local dynamics; (2) rigorous statistical guarantees (consistency and weak convergence) for the estimator; (3) a scalable LSH implementation that brings kernel regression to large‑scale graphs; and (4) extensive experimental validation demonstrating superior accuracy on both synthetic and real dynamic networks. The work opens avenues for further extensions such as incorporating multi‑modal node attributes, handling heterogeneous edge types, and developing fully online updating schemes.
Comments & Academic Discussion
Loading comments...
Leave a Comment