Scalable Influence Estimation in Continuous-Time Diffusion Networks
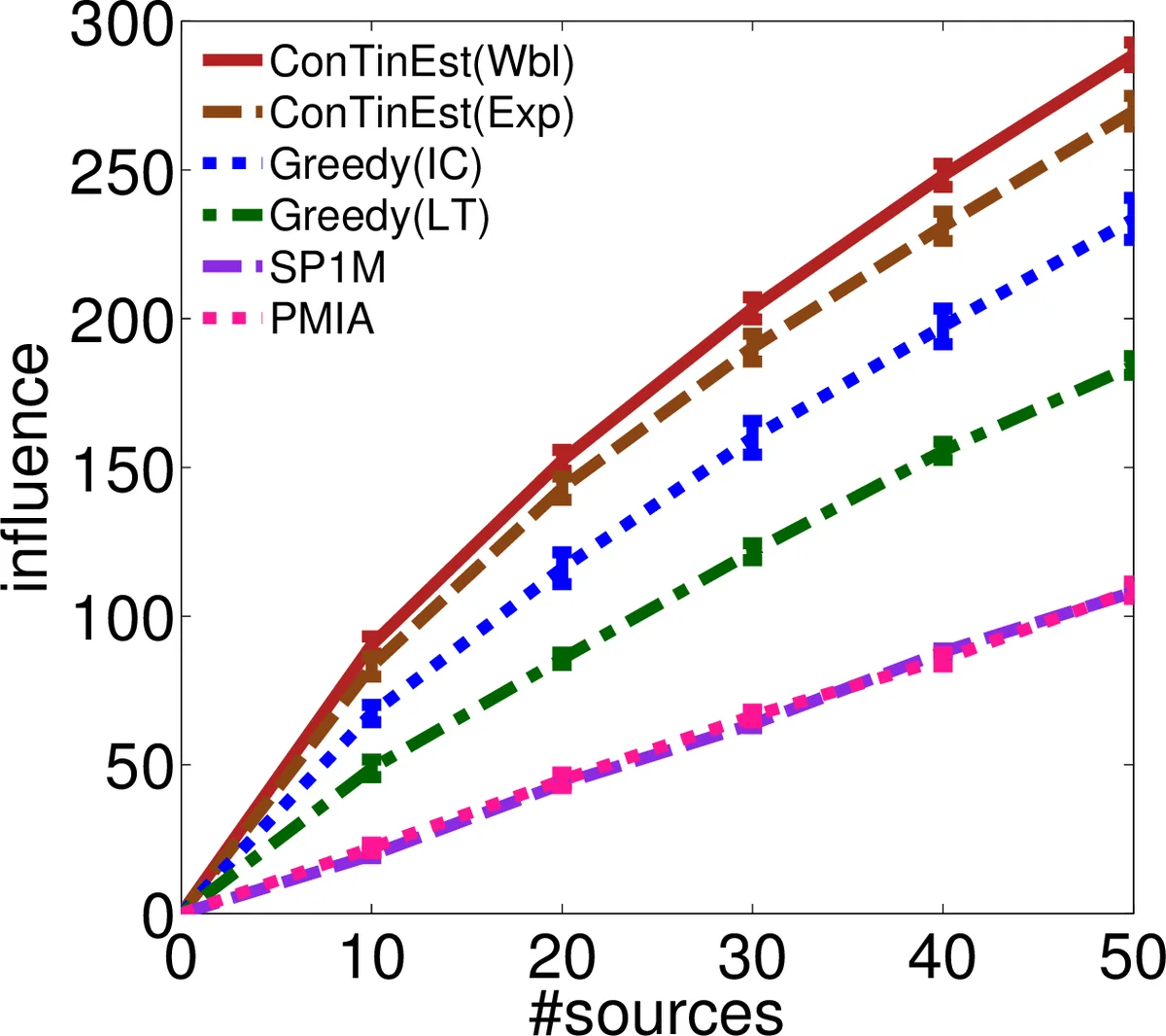
If a piece of information is released from a media site, can it spread, in 1 month, to a million web pages? This influence estimation problem is very challenging since both the time-sensitive nature of the problem and the issue of scalability need to be addressed simultaneously. In this paper, we propose a randomized algorithm for influence estimation in continuous-time diffusion networks. Our algorithm can estimate the influence of every node in a network with |V| nodes and |E| edges to an accuracy of $\varepsilon$ using $n=O(1/\varepsilon^2)$ randomizations and up to logarithmic factors O(n|E|+n|V|) computations. When used as a subroutine in a greedy influence maximization algorithm, our proposed method is guaranteed to find a set of nodes with an influence of at least (1-1/e)OPT-2$\varepsilon$, where OPT is the optimal value. Experiments on both synthetic and real-world data show that the proposed method can easily scale up to networks of millions of nodes while significantly improves over previous state-of-the-arts in terms of the accuracy of the estimated influence and the quality of the selected nodes in maximizing the influence.
💡 Research Summary
The paper tackles the problem of estimating and maximizing influence in continuous‑time diffusion networks, where the goal is to predict how many nodes will be infected within a finite time window (e.g., one month). Traditional influence‑maximization work largely assumes infinite time horizons or relies on discrete‑time models that only capture a single infection probability per edge. Such approaches are inadequate for real‑world scenarios that require fine‑grained temporal modeling and scalability to massive graphs.
The authors adopt the Continuous‑Time Independent Cascade (CTIC) model. Each directed edge (j!\to! i) is associated with a transmission function (f_{ji}(\tau)), a probability density over the random transmission delay (\tau). These functions can be heterogeneous (exponential, Rayleigh, or non‑parametric) and are assumed to be learned beforehand from cascade data. A key structural property of CTIC is the “shortest‑path property”: once a concrete set of transmission delays ({\tau_{ji}}) is sampled, the infection time of any node (i) equals the length of the shortest path from the source set to (i) when edge weights are the sampled delays. This observation converts the original inference problem—computing marginal probabilities over dependent infection times—into a problem involving only independent edge‑level random variables.
A naïve Monte‑Carlo estimator would repeatedly sample the edge delays, run a shortest‑path algorithm for each sample, and average the number of nodes reached within the time window. Although unbiased, this approach incurs (O(n|V||E|)) time (with (n) samples), which is prohibitive for graphs with millions of vertices and edges.
To overcome this bottleneck, the authors leverage a classic randomized algorithm by Cohen (1997) for estimating the size of a node’s time‑bounded neighborhood. Cohen’s method assigns each node an independent exponential label (r_i\sim\text{Exp}(1)). For a source (s) and horizon (T), the minimum label among all nodes reachable within (T) follows an exponential distribution whose rate equals the true neighborhood size (|N(s,T)|). By drawing (m) independent labelings and recording the minima (r^{}_1,\dots,r^{}m), an unbiased estimator (\hat N(s,T)=\frac{m-1}{\sum{u=1}^m r^{*}_u}) is obtained. The crucial computational step—finding the minimum reachable label for a given source—can be performed with a modified Dijkstra’s algorithm that processes nodes in order of increasing label and records “least‑label lists” for every vertex. This preprocessing costs (O(|E|\log|V|+|V|\log^2|V|)) time and yields lists of expected size (O(\log|V|)); subsequent queries are answered in (O(\log\log|V|)) via binary search.
The proposed CONTINEST algorithm integrates these ideas as follows:
- Sample edge transmission times (n = O(1/\varepsilon^2)) times (the factor ensures an additive error (\varepsilon) with high probability).
- For each sample, run Cohen’s preprocessing to obtain least‑label lists for all vertices.
- For each vertex (s) and the target horizon (T), query the list to retrieve the minimum label, then apply Cohen’s estimator to obtain (|N(s,T)|).
- Average the estimates over the (n) samples to produce (\hat\sigma(s,T)), the estimated influence of node (s).
The total computational complexity becomes \
Comments & Academic Discussion
Loading comments...
Leave a Comment