A Fractal and Scale-free Model of Complex Networks with Hub Attraction Behaviors
It is widely believed that fractality of complex networks origins from hub repulsion behaviors (anticorrelation or disassortativity), which means large degree nodes tend to connect with small degree nodes. This hypothesis was demonstrated by a dynamical growth model, which evolves as the inverse renormalization procedure proposed by Song et al. Now we find that the dynamical growth model is based on the assumption that all the cross-boxes links has the same probability e to link to the most connected nodes inside each box. Therefore, we modify the growth model by adopting the flexible probability e, which makes hubs have higher probability to connect with hubs than non-hubs. With this model, we find some fractal and scale-free networks have hub attraction behaviors (correlation or assortativity). The results are the counter-examples of former beliefs.
💡 Research Summary
The paper challenges the prevailing view that fractality in complex networks originates from hub repulsion (anticorrelation), a hypothesis supported by the dynamical growth model (DMG) introduced by Song et al. The authors argue that DMG assumes every cross‑box link has the same probability e to attach to the most connected node inside each box, which implicitly treats the locally most‑connected nodes as global hubs. Because real scale‑free networks contain a few truly high‑degree hubs while most box‑level maxima are much smaller, this assumption is unrealistic.
To address this, the authors propose a new dynamical growth framework called the Hub‑Attraction Dynamical Growth Model (HADGM). The key innovation is a flexible probability e(k₁,k₂) that depends on the degrees of the two end nodes at the previous time step. If both nodes have degrees larger than a fraction T of the current maximum degree k_max, they are considered hubs and are linked with a high probability a (typically set to 1). Otherwise the link is created with a lower probability b (0 < b < a). This piecewise definition allows hubs to preferentially connect with each other while suppressing hub‑non‑hub connections.
The growth process follows the original DMG scheme: each existing node of degree k spawns m·k new “black” nodes inside a virtual box, and the original “red” node connects to all of them. After the node‑generation step, an “inside‑box link‑growth” phase adds roughly k̃(t‑1) additional edges inside each box, thereby introducing loops and increasing clustering without altering the scaling of node count, maximum degree, or network diameter.
Analytical derivations yield recursive relations for total nodes Ñ(t), maximum intra‑box degree k̃(t), and network diameter L̃(t):
- Ñ(t) ≈ (2m + 3) Ñ(t‑1)
- k̃(t) ≈ (m + ē) k̃(t‑1)
- L̃(t) ≈ (3 − 2ē) L̃(t‑1) + 2e
where ē is the average of the flexible probability. From these, the fractal dimension is obtained as
d_B = ln(2m + 3) / ln(3 − 2ē).
When the low‑probability parameter b is small (e.g., b = 0.5), ē remains well below 1, producing a finite d_B (~2.3 for m = 2) and thus a fractal network. As b approaches 1, ē → 1, d_B diverges and the network loses its fractal character. Simulations confirm this transition: networks with b = 0.5 or 0.7 exhibit clear power‑law scaling of the box‑covering function N_B(ℓ_B) ∝ ℓ_B^{−d_B}, while b = 0.9 yields a flat curve indicating non‑fractality.
The degree distribution remains scale‑free, P(k) ∝ k^{−γ}, with the exponent γ slightly modulated by b through ē. Importantly, fractality is preserved even when hubs are strongly attracted to each other, contradicting the earlier claim that hub repulsion is necessary for self‑similarity.
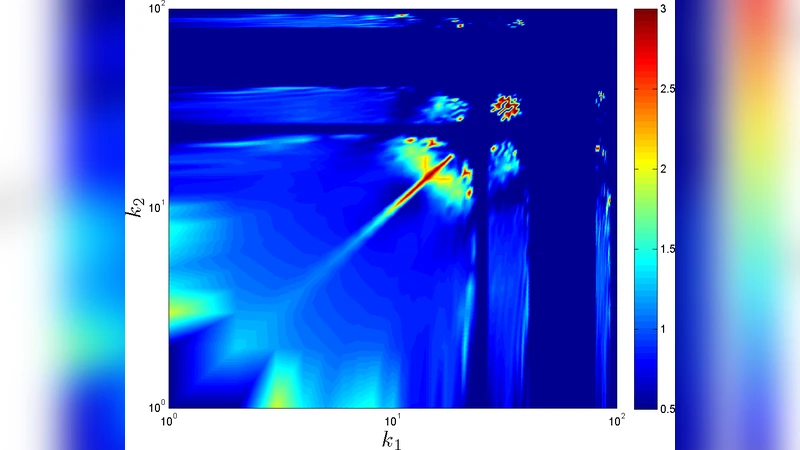
Correlation analysis uses the joint‑degree probability ratio R(k₁,k₂) = P(k₁,k₂)/P_r(k₁,k₂) and the Pearson assortativity coefficient r. Compared to the original DMG with e = 1 (non‑fractal, weakly assortative), HADGM (fractal, b = 0.5) shows a markedly higher R(k₁,k₂) for high‑degree pairs, indicating strong hub‑hub attraction. Real‑world data from the World Wide Web (WWW) and the AS‑level Internet are also examined. The WWW displays moderate hub attraction, while the Internet is disassortative and non‑fractal.
The authors further compare HADGM with an optimization‑based fractal model that minimizes the sum of node degrees while maximizing the sum of edge degrees under constraints on average shortest path length. This optimization model generates a fractal, scale‑free network with a high positive assortativity (r ≈ 0.84). Table 1 summarizes the four networks: DMG (e = 1) – non‑fractal, disassortative; HADGM (a = 1, b = 0.5) – fractal, weakly disassortative for low degrees but assortative for high degrees; Optimization model – fractal, strongly assortative; Internet – non‑fractal, disassortative.
These results collectively demonstrate that fractality and assortativity are not intrinsically linked: a network can be fractal while exhibiting strong hub attraction, or be non‑fractal and disassortative. The paper thus refutes the earlier conjecture that hub repulsion is the sole driver of fractality in scale‑free networks.
In conclusion, the HADGM provides a flexible framework where the probability of hub‑hub connections can be tuned independently of the fractal dimension. This decoupling suggests new avenues for designing synthetic networks with desired self‑similarity and mixing patterns, and prompts a re‑examination of growth mechanisms in empirical systems where hub attraction may play a significant role. Future work could involve applying HADGM to biological, social, or technological networks to validate its predictive power and exploring hybrid models that combine hub‑attraction dynamics with optimization criteria for robustness or efficiency.
Comments & Academic Discussion
Loading comments...
Leave a Comment