TOP-SPIN: TOPic discovery via Sparse Principal component INterference
We propose a novel topic discovery algorithm for unlabeled images based on the bag-of-words (BoW) framework. We first extract a dictionary of visual words and subsequently for each image compute a visual word occurrence histogram. We view these histograms as rows of a large matrix from which we extract sparse principal components (PCs). Each PC identifies a sparse combination of visual words which co-occur frequently in some images but seldom appear in others. Each sparse PC corresponds to a topic, and images whose interference with the PC is high belong to that topic, revealing the common parts possessed by the images. We propose to solve the associated sparse PCA problems using an Alternating Maximization (AM) method, which we modify for purpose of efficiently extracting multiple PCs in a deflation scheme. Our approach attacks the maximization problem in sparse PCA directly and is scalable to high-dimensional data. Experiments on automatic topic discovery and category prediction demonstrate encouraging performance of our approach.
💡 Research Summary
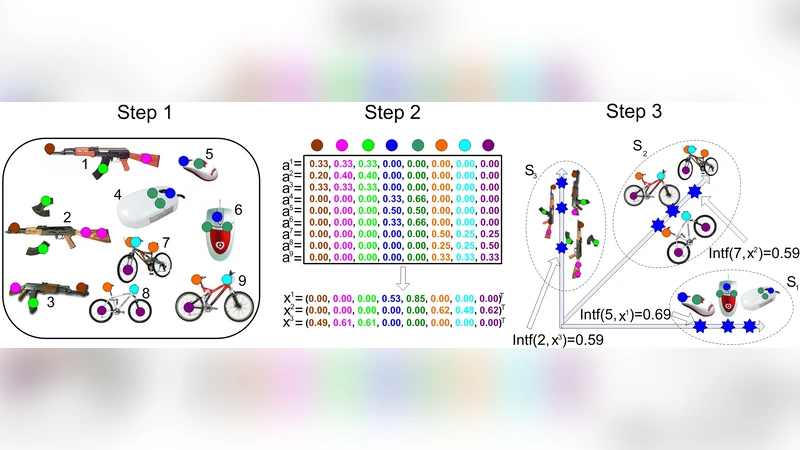
TOP‑SPIN (TOPic discovery via Sparse Principal component INterference) is a novel unsupervised method for discovering image topics from a collection of unlabeled pictures. The approach starts with the classic bag‑of‑words (BoW) pipeline: local descriptors (e.g., SIFT) are extracted from each image, clustered to form a visual vocabulary of size p, and each image is represented by a normalized histogram hᵢ∈ℝᵖ of visual‑word frequencies. To down‑weight ubiquitous words, a TF‑IDF‑style weight vector w≥0 is computed and incorporated into the data matrix A = H Diag(w), where H stacks the histograms.
The core of TOP‑SPIN is the extraction of k sparse principal components (sparse PCs) from A. Each sparse PC xₗ is obtained by solving
max ‖A xₗ‖₂² subject to ‖xₗ‖₂ ≤ 1, ‖xₗ‖₀ ≤ s,
where s is a user‑specified sparsity level. The authors solve this non‑convex problem with the Alternating Maximization (AM) framework known as 24AM. Starting from an initial x⁽⁰⁾, the algorithm iteratively updates y = A x / ‖A x‖₂ and then x = Tₛ(Aᵀy) / ‖Tₛ(Aᵀy)‖₂, where Tₛ keeps only the s largest‑magnitude entries (hard‑thresholding). This formulation directly controls sparsity, unlike the Augmented Lagrangian Method (ALM) which requires indirect penalty tuning. Empirically, 24AM converges three orders of magnitude faster than ALM, especially as the dimensionality p grows.
To obtain multiple topics, a deflation scheme is employed: after computing the first sparse PC x₁, the matrix is updated as A₂ = A₁ – x₁x₁ᵀ, and the same AM procedure is applied to A₂ to extract x₂, and so on up to x_k. Each resulting PC is orthogonal to the previous ones and typically highlights a distinct subset of visual words.
Topic assignment uses a simple interference measure:
Intf(i, xₗ) = |⟨hᵢ ⊙ w, xₗ⟩|,
the absolute dot product between the weighted histogram of image i and the sparse PC. This value equals the length of the projection of the weighted histogram onto the PC, quantifying how strongly the image contains the visual‑word pattern encoded by xₗ. For each PC, all images are scored, and a threshold δₗ is chosen automatically by clustering the scores into “high” and “low” groups (e.g., via 2‑means). Images with Intf(i, xₗ) > δₗ form the topic set Sₗ.
The paper evaluates TOP‑SPIN on several public image datasets (including Caltech‑101, Pascal VOC, and SUN). Results show that (1) sparse PCs correspond to semantically meaningful visual‑word groups (e.g., “cars”, “people”, “bicycles”), (2) the interference‑based assignment yields high‑purity topic clusters, and (3) the method outperforms or matches existing unsupervised categorization techniques while being far more computationally efficient. The authors also compare 24AM with ALM, demonstrating that 24AM achieves comparable sparsity and variance explained but with dramatically reduced runtime.
Strengths of TOP‑SPIN include its simplicity (standard BoW + sparse PCA), interpretability (each PC directly lists the most representative visual words), scalability (the AM algorithm runs efficiently on multicore CPUs and GPUs), and flexibility (different weighting schemes or vocabulary sizes can be plugged in). Limitations are acknowledged: the choice of vocabulary size p and sparsity level s can affect performance; in images with heavy background clutter or multiple co‑occurring objects, a single PC may capture mixed topics, making the binary thresholding less reliable. Future work suggested involves integrating spatial pyramids, multi‑scale vocabularies, or kernelized sparse PCA to better handle complex scenes.
In summary, TOP‑SPIN provides an effective, fast, and interpretable framework for unsupervised image topic discovery by marrying sparse principal component analysis with a straightforward interference metric, offering a practical tool for large‑scale image collections where manual labeling is infeasible.
Comments & Academic Discussion
Loading comments...
Leave a Comment