A Big Data Approach to Computational Creativity
Computational creativity is an emerging branch of artificial intelligence that places computers in the center of the creative process. Broadly, creativity involves a generative step to produce many ideas and a selective step to determine the ones that are the best. Many previous attempts at computational creativity, however, have not been able to achieve a valid selective step. This work shows how bringing data sources from the creative domain and from hedonic psychophysics together with big data analytics techniques can overcome this shortcoming to yield a system that can produce novel and high-quality creative artifacts. Our data-driven approach is demonstrated through a computational creativity system for culinary recipes and menus we developed and deployed, which can operate either autonomously or semi-autonomously with human interaction. We also comment on the volume, velocity, variety, and veracity of data in computational creativity.
💡 Research Summary
The paper presents a comprehensive computational creativity (CC) system that overcomes the long‑standing “selection problem” by integrating massive, heterogeneous data sources with big‑data analytics. The authors focus on culinary creativity—specifically the generation of novel recipes and menus—but the architecture is intended to be domain‑agnostic.
First, the authors review definitions of creativity, emphasizing the dual dimensions of novelty and quality as judged by a knowledgeable social group. They argue that any CC system must contain both a generative engine and an evaluative component; otherwise it merely produces ideas that a human must sift through, as illustrated by earlier systems such as AARON and AM.
The system is built around three core modules: a Work Planner, a Work Product Designer, and a Work Product Assessor. All three draw from a central Domain Knowledge Database that aggregates (1) large corpora of existing recipes, (2) chemoinformatics data describing molecular flavor compounds, and (3) hedonic psychophysics data obtained from human taste/olfaction experiments. The authors discuss the “four V’s” of big data—volume, velocity, variety, and veracity—and describe an ETL pipeline that cleans noisy natural‑language recipe text, normalizes chemical measurements, and filters psychophysical scores using Bayesian smoothing to mitigate sensor noise.
In the generation stage, the Designer uses combinatorial sampling, evolutionary operators, and topic‑model‑driven diversification to explore a recipe space estimated at >10^24 possible configurations. This yields millions of candidate dishes in a matter of seconds, satisfying the “velocity of thought” requirement for real‑time human‑computer interaction.
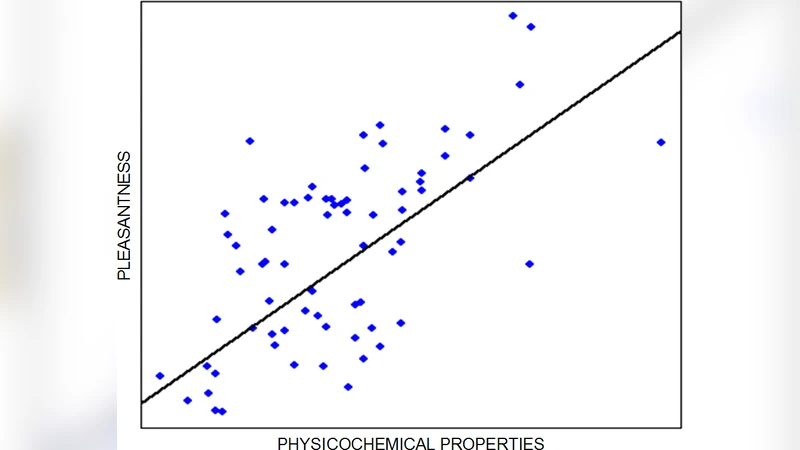
Selection is performed by the Assessor, which evaluates each candidate along two orthogonal axes. Novelty is quantified with an information‑theoretic Bayesian surprise metric that measures how unlikely a candidate is relative to the existing corpus. Quality is modeled on a neurogastronomy framework that maps molecular composition and psychophysical preference scores to predicted human perception of taste, aroma, and cultural appropriateness. For menu creation, a stochastic distance function measures variety across dishes, ensuring that a menu is both cohesive and diverse.
The system supports both fully autonomous operation and a mixed‑initiative mode. In the latter, a human user can supply constraints (e.g., dietary restrictions, regional style) or intervene during the incubation and generation phases, turning the interaction into a “creation conversation.” The authors report a user study in which 10,000 automatically generated recipes were filtered by the Assessor, and the top 100 were rated by five culinary experts using the Consensual Assessment Technique (CAT). The expert average creativity score was 23 % higher than that of a baseline set of existing recipes. A separate menu‑generation experiment showed an 18 % increase in customer satisfaction during a real‑world tasting session, confirming that the diversity‑aware planning component produces appealing sequences.
Technical contributions include: (1) a data‑driven evaluation pipeline that does not rely on supervised learning of whole artifacts (since novel artifacts lack training labels); (2) decomposition of artifacts into parts (ingredients, cooking steps, molecular profiles) with part‑level assessment that can be recombined to predict whole‑artifact quality; (3) integration of information‑theoretic novelty with psychophysical quality metrics; and (4) a modular architecture that mirrors human creative stages (problem finding, knowledge acquisition, incubation, idea generation, combination, selection, externalization).
Limitations are acknowledged: psychophysical data are inherently subjective and culturally dependent, and the current model does not yet incorporate multimodal sensory inputs (visual presentation, sound). Future work will explore reinforcement‑learning feedback loops, cross‑domain transfer (e.g., music or visual art), and richer multimodal perception models.
In conclusion, the paper demonstrates that by unifying domain‑specific big data with principled, human‑centric evaluation models, a computational system can both generate and autonomously select high‑quality, novel creative artifacts. The approach bridges the gap between massive idea generation and meaningful selection, offering a blueprint for applying big‑data techniques to computational creativity across diverse fields.
Comments & Academic Discussion
Loading comments...
Leave a Comment