A Gang of Bandits
Multi-armed bandit problems are receiving a great deal of attention because they adequately formalize the exploration-exploitation trade-offs arising in several industrially relevant applications, such as online advertisement and, more generally, rec…
Authors: Nicol`o Cesa-Bianchi, Claudio Gentile, Giovanni Zappella
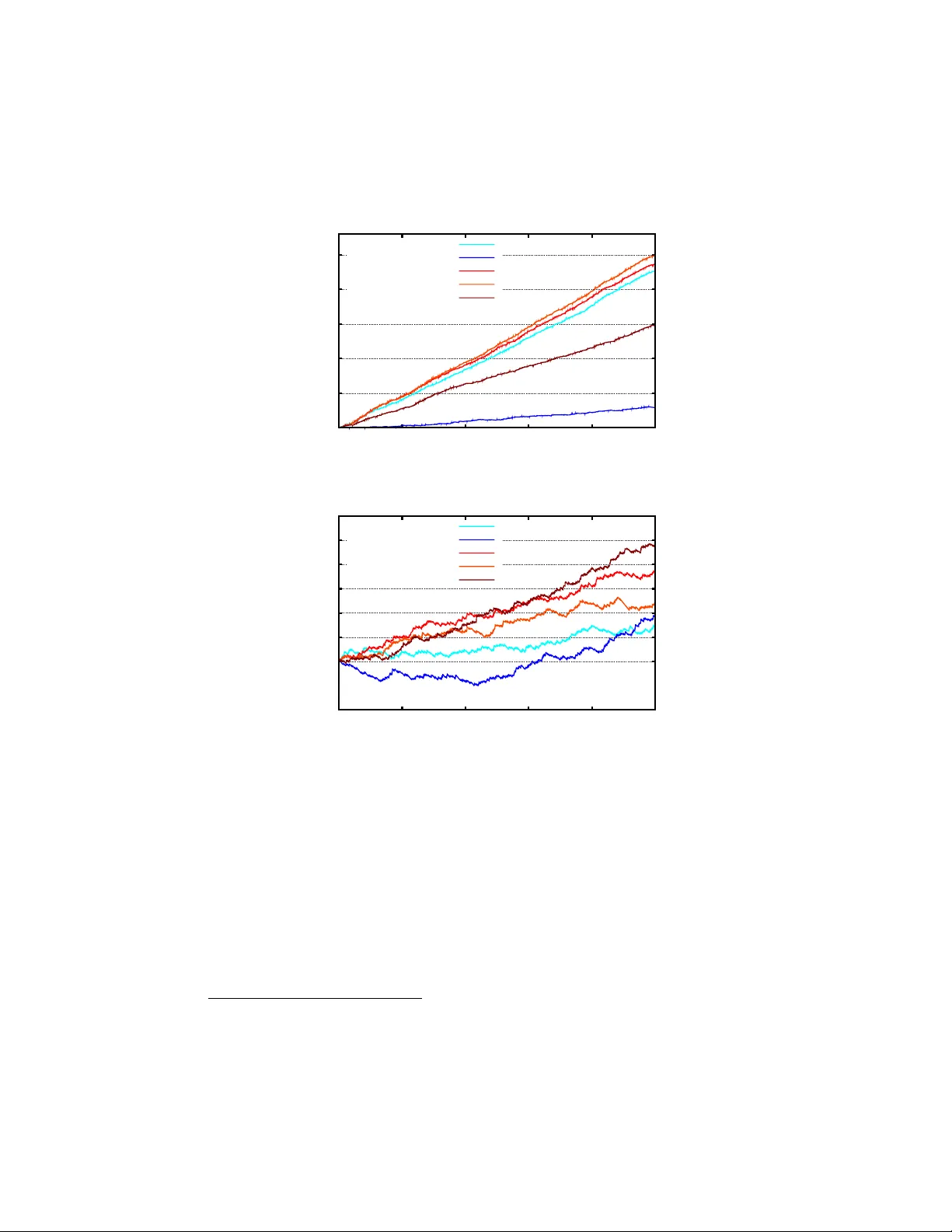
A Gang of Bandits Nicol` o Cesa-Bianc hi DI, Univ ersit y of Milan, Italy nicolo.cesa-bianchi@unimi.it Claudio Gen tile DiST A, Univ ersit y of Insubria, Italy claudio.gentile@uninsubria.it Gio v anni Zapp ella Dept. of Mathematics, Univ ersit y of Milan, Italy giovanni.zappella@unimi.it No v em b er 5, 2013 Abstract Multi-armed bandit problems are receiving a great deal of attention b ecause they adequately formalize the exploration-exploitation trade-offs arising in several industrially relev ant applications, such as online adver- tisemen t and, more generally , recommendation systems. In many cases, ho wev er, these applications ha ve a strong so cial comp onent, whose in- tegration in the bandit algorithm could lead to a dramatic p erformance increase. F or instance, w e may w ant to serv e con tent to a group of users b y taking adv antage of an underlying net work of so cial relationships among them. In this pap er, we in troduce nov el algorithmic approaches to the solution of such net w orked bandit problems. More sp ecifically , we design and analyze a global strategy which allo cates a bandit algorithm to each net work node (user) and allo ws it to “share” signals (con texts and pa y offs) with the negh b oring nodes. W e then derive t w o more scalable v ariants of this strategy based on differen t wa ys of clustering the graph no des. W e exp erimen tally compare the algorithm and its v ariants to state-of-the-art metho ds for contextual bandits that do not use the relational information. Our exp erimen ts, carried out on sy n thetic and real-world datasets, show a marked increase in prediction p erformance obtained b y exploiting the net work structure. 1 1 In tro duction The abilit y of a website to present p ersonalized conten t recommendations is pla ying an increasingly crucial role in ac hieving user satisfaction. Because of the app earance of new conten t, and due to the ever-c hanging nature of conten t p opularit y , mo dern approaches to conten t recommendation are strongly adap- tiv e, and attempt to match as closely as p ossible users’ interests by learning go od mappings b etw een av ailable conten t and users. These mappings are based on “con texts”, that is sets of features that, typically , are extracted from b oth con tents and users. The need to fo cus on con ten t that raises the user interest and, simultaneously , the need of exploring new conten t in order to globally im- pro ve the user exp erience creates an exploration-exploitation dilemma, which is commonly formalized as a multi-armed bandit problem. Indeed, contextual bandits ha ve b ecome a reference mo del for the study of adaptive techniques in recommender systems (e.g, [5, 7, 15] ). In man y cases, ho wev er, the users targeted b y a recommender system form a so cial netw ork. The netw ork struc- ture provides an important additional source of information, revealing potential affinities betw een pairs of users. The exploitation of such affinities could lead to a dramatic increase in the qualit y of the recommendations. This is b ecause the knowledge gathered ab out the in terests of a given user may b e exploited to impro ve the recommendation to the user’s friends. In this work, an algorith- mic approach to netw ork ed contextual bandits is prop osed which is pro v ably able to leverage user similarities represen ted as a graph. Our approach consists in running an instance of a con textual bandit algorithm at each netw ork no de. These instances are allo wed to in teract during the learning process, sharing con- texts and user feedbacks. Under the mo deling assumption that user similarities are prop erly reflected by the netw ork structure, interactions allow to effectively sp eed up the learning pro cess that tak es place at eac h no de. This mec hanism is implemented by running instances of a linear contextual bandit algorithm in a sp ecific repro ducing kernel Hilb ert space (RKHS). The underlying kernel, previously used for solving online multitask classification problems (e.g., [8]), is defined in terms of the Laplacian matrix of the graph. The Laplacian matrix pro vides the information we rely up on to share user feedbacks from one no de to the others, according to the net work structure. Since the Laplacian kernel is linear, the implementation in kernel space is straightforw ard. Moreov er, the existing p erformance guarantees for the sp ecific bandit algorithm we use can b e directly lifted to the RKHS, and expressed in terms of sp ectral prop erties of the user netw ork. Despite its crispness, the principled approach describ ed ab ov e has tw o drawbac ks hindering its practical usage. First, running a netw ork of linear contextual bandit algorithms with a Laplacian-based feedbac k sharing mec hanism may cause significant scaling problems, even on small to medium sized so cial netw orks. Second, the so cial information pro vided by the netw ork structure at hand need not b e fully reliable in accounting for user b ehavior sim- ilarities. Clearly enough, the more such algorithms hinge on the netw ork to impro ve learning rates, the more they are p enalized if the netw ork information is noisy and/or misleading. After collecting empirical evidence on the sensitivit y 2 of netw orked bandit methods to graph noise, we propose t w o simple mo difica- tions to our basic strategy , b oth aimed at circum ven ting the ab ov e issues by clustering the graph nodes. The first approach reduces graph noise simply by deleting edges b etw een pairs of clusters. By doing that, we end up running a scaled down indep endent instance of our original strategy on each cluster. The second approach treats each cluster as a single node of a m uch smaller cluster net work. In b oth cases, we are able to empirically impro ve prediction p erfor- mance, and sim ultaneously achiev e dramatic savings in running times. W e run exp erimen ts on t wo real-world datasets: one is extracted from the so cial bo ok- marking web service Delicious, and the other one from the music streaming platform Last.fm. 2 Related w ork The b enefit of using so cial relationships in order to impro v e the quality of rec- ommendations is a recognized fact in the literature of conten t recommender systems —see e.g., [5, 13, 18] and the survey [3]. Linear models for contextual bandits w ere introduced in [4]. Their application to personalized con ten t recom- mendation was pioneered in [15], where the LinUCB algorithm was introduced. An analysis of LinUCB w as provided in the subsequent work [9]. T o the b est of our knowledge, this is the first work that com bines con textual bandits with the so cial graph information. Ho w ever, non-contextual sto c hastic bandits in so cial net works were studied in a recent indep endent work [20]. Other works, suc h as [2, 19], consider con textual bandits assuming metric or probabilistic dep en- dencies on the pro duct space of contexts and actions. A differen t viewp oin t, where eac h action reveals information ab out other actions’ pay offs, is the one studied in [7, 16], though without the context provided by feature vectors. A non-con textual mo del of bandit algorithms running on the no des of a graph w as studied in [14]. In that w ork, only one no de rev eals its pa yoffs, and the statistical information acquired by this node ov er time is spread across the en- tire netw ork following the graphical structure. The main result sho ws that the information flow rate is sufficien t to control regret at e ac h no de of the netw ork. More recen tly , a new mo del of distributed non-con textual bandit algorithms has b een presented in [21], where the n umber of communications among the no des is limited, and all the no des in the net work hav e the same b est action. 3 Learning mo del W e assume the social relationships o ver users are encoded as a known undirected and connected graph G = ( V , E ), where V = { 1 , . . . , n } represen ts a set of n users, and the edges in E represent the so cial links ov er pairs of users. Recall that a graph G can b e equiv alently defined in terms of its Laplacian matrix L = L i,j n i,j =1 , where L i,i is the degree of no de i (i.e., the n umber of incom- ing/outgoing edges) and, for i 6 = j , L i,j equals − 1 if ( i, j ) ∈ E , and 0 otherwise. 3 Learning pro ceeds in a sequential fashion: A t each time step t = 1 , 2 , . . . , the learner receives a user index i t ∈ V together with a set of context vectors C i t = { x t, 1 , x t, 2 , . . . , x t,c t } ⊆ R d . The learner then selects some k t ∈ C i t to recommend to user i t and observes some pa yoff a t ∈ [ − 1 , 1], a function of i t and ¯ x t = x t,k t . No assumptions whatso ever are made on the wa y index i t and set C i t are generated, in that they can arbitrarily dep end on past choices made b y the algorithm. 1 A standard mo deling assumption for bandit problems with contextual infor- mation (one that is also adopted here) is to assume that rewards are generated b y noisy versions of unknown linear functions of the con text vectors. That is, w e assume each node i ∈ V hosts an unknown parameter v ector u i ∈ R d , and that the rew ard v alue a i ( x ) asso ciated with no de i and con text v ector x ∈ R d is given b y the random v ariable a i ( x ) = u > i x + i ( x ), where i ( x ) is a con- ditionally zero-mean and b ounded v ariance noise term. Sp ecifically , denoting b y E t [ · ] the conditional exp ectation E · ( i 1 , C i 1 , a 1 ) , . . . , ( i t − 1 , C i t − 1 , a t − 1 ) , w e tak e the general approach of [1], and assume that for any fixed i ∈ V and x ∈ R d , the v ariable i ( x ) is conditionally sub-Gaussian with v ariance parame- ter σ 2 > 0, namely , E t exp( γ i ( x )) ≤ exp σ 2 γ 2 / 2 for all γ ∈ R and all x , i . This implies E t [ i ( x )] = 0 and V t i ( x ) ≤ σ 2 , where V t [ · ] is a shorthand for the conditional v ariance V · ( i 1 , C i 1 , a 1 ) , . . . , ( i t − 1 , C i t − 1 , a t − 1 ) . So we clearly ha ve E t [ a i ( x )] = u > i x and V t a i ( x ) ≤ σ 2 . Therefore, u > i x is the exp ected rew ard observed at no de i for context vector x . In the sp ecial case when the noise i ( x ) is a b ounded random v ariable taking v alues in the range [ − 1 , 1], this implies V t [ a i ( x )] ≤ 4. The regret r t of the learner at time t is the amount b y which the av erage rew ard of the b est c hoice in hindsight at no de i t exceeds the av erage rew ard of the algorithm’s choice, i.e., r t = max x ∈ C i t u > i t x − u > i t ¯ x t . The goal of the algorithm is to b ound with high probability (ov er the noise v ariables i t ) the cumulativ e regret P T t =1 r t for the given sequence of no des i 1 , . . . , i T and observed context v ector sets C i 1 , . . . , C i T . W e mo del the similarity among users in V by making the assumption that nearby users hold similar underlying vectors u i , so that reward signals received at a given no de i t at time t are also, to some extent, informative to learn the b ehavior of other users j connected to i t within G . W e make this more precise by taking the p ersp ectiv e of known multitask learning settings (e.g., [8]), and assume that X ( i,j ) ∈ E k u i − u j k 2 (1) is small compared to P i ∈ V k u i k 2 , where k · k denotes the standard Euclidean norm of v ectors. That is, although (1) ma y possibly contain a quadratic n umber 1 F ormally , i t and C i t can be arbitrary (measurable) functions of past rewards a 1 , . . . , a t − 1 , indices i 1 , . . . , i t − 1 , and sets C i 1 , . . . , C i t − 1 . 4 of terms, the closeness of vectors lying on adjacen t no des in G makes this sum comparativ ely smaller than the actual length of such vectors. This will b e our w orking assumption throughout, one that motiv ates the Laplacian-regularized algorithm presented in Section 4, and empirically tested in Section 5. 4 Algorithm and regret analysis Our bandit algorithm main tains at time t an estimate w i,t for v ector u i . V ectors w i,t are up dated based on the rew ard signals as in a standard linear bandit algorithm (e.g., [9]) op erating on the context vectors contained in C i t . Every no de i of G hosts a linear bandit algorithm like the one describ ed in Figure 1. The algorithm in Figure 1 maintains at time t a prototype vector w t whic h is the result of a standard linear least-squares approximation to the unknown parameter v ector u associated with the node under consideration. In particular, w t − 1 is obtained by multiplying the inv erse correlation matrix M t − 1 and the bias vector b t − 1 . A t each time t = 1 , 2 , . . . , the algorithm receives context v ectors x t, 1 , . . . , x t,c t con tained in C t , and must select one among them. The linear bandit algorithm selects ¯ x t = x t,k t as the vector in C t that maximizes an upp er-confidence-corrected estimation of the exp ected reward achiev ed ov er con text vectors x t,k . The estimation is based on the curren t w t − 1 , while the upp er confidence lev el cb t is suggested by the standard analysis of linear bandit algorithms —see, e.g., [1, 9, 10]. Once the actual rew ard a t asso ciated with ¯ x t is observed, the algorithm uses ¯ x t for up dating M t − 1 to M t via a rank- one adjustmen t, and b t − 1 to b t via an additive up date whose learning rate is precisely a t . This algorithm can b e seen as a v ersion of LinUCB [9], a linear bandit algorithm derived from LinRel [4]. W e now turn to describing our GOB.Lin (Gang Of Bandits, Linear v ersion) algorithm. GOB.Lin lets the algorithm in Figure 1 op erate on each no de i of G (w e should then add subscript i throughout, replacing w t b y w i,t , M t b y M i,t , and so forth). The up dates M i,t − 1 → M i,t and b i,t − 1 → b i,t are p erformed at no de i through vector ¯ x t b oth when i = i t (i.e., when no de i is the one whic h the context vectors in C i t refer to) and to a lesser extent when i 6 = i t (i.e., when no de i is not the one which the vectors in C i t refer to). This is b ecause, as w e said, the pay off a t receiv ed for no de i t is someho w informative also for all other nodes i 6 = i t . In other words, bec ause we are assuming the underlying parameter v ectors u i are close to each other, we should let the corresp onding protot yp e vectors w i,t undergo similar up dates, so as to also keep the w i,t close to each other ov er time. With this in mind, w e now describe GOB.Lin in more detail. It is con v enient to in tro duce first some extra matrix notation. Let A = I n + L , where L is the Laplacian matrix asso ciated with G , and I n is the n × n identit y matrix. Set A ⊗ = A ⊗ I d , the Kroneck er pro duct 2 of matrices A and I d . Moreo v er, the 2 The Kroneck er pro duct between tw o matrices M ∈ R m × n and N ∈ R q × r is the blo ck matrix M ⊗ N of dimension mq × nr whose block on row i and column j is the q × r matrix M i,j N . 5 Init : b 0 = 0 ∈ R d and M 0 = I ∈ R d × d ; for t = 1 , 2 , . . . , T do Set w t − 1 = M − 1 t − 1 b t − 1 ; Get context C t = { x t, 1 , . . . , x t,c t } ; Set k t = argmax k =1 ,...,c t w > t − 1 x t,k + cb t ( x t,k ) where cb t ( x t,k ) = q x > t,k M − 1 t − 1 x t,k σ r ln | M t | δ + k u k ! Set ¯ x t = x t,k t ; Observ e reward a t ∈ [ − 1 , 1]; Up date • M t = M t − 1 + ¯ x t ¯ x > t , • b t = b t − 1 + a t ¯ x t . end for Figure 1: Pseudo code of the linear bandit algo- rithm sitting at eac h no de i of the giv en graph. Init : b 0 = 0 ∈ R dn and M 0 = I ∈ R dn × dn ; for t = 1 , 2 , . . . , T do Set w t − 1 = M − 1 t − 1 b t − 1 ; Get i t ∈ V , context C i t = { x t, 1 , . . . , x t,c t } ; Construct vectors φ i t ( x t, 1 ) , . . . , φ i t ( x t,c t ), and modified vectors e φ t, 1 , . . . , e φ t,c t , where e φ t,k = A − 1 / 2 ⊗ φ i t ( x t,k ) , k = 1 , . . . , c t ; Set k t = argmax k =1 ,...,c t w > t − 1 e φ t,k + cb t ( e φ t,k ) where cb t ( e φ t,k ) = q e φ > t,k M − 1 t − 1 e φ t,k σ r ln | M t | δ + k e U k ! Observ e reward a t ∈ [ − 1 , 1] at no de i t ; Up date • M t = M t − 1 + e φ t,k t e φ > t,k t , • b t = b t − 1 + a t e φ t,k . end for Figure 2: Pseudo co de of the GOB.Lin algorithm. “comp ound” descriptor for the pairing ( i, x ) is given b y the long (and sparse) 6 v ector φ i ( x ) ∈ R dn defined as φ i ( x ) > = 0 , . . . , 0 | {z } ( i − 1) d times , x > , 0 , . . . , 0 | {z } ( n − i ) d times . With the ab ov e notation handy , a compact description of GOB.Lin is presented in Figure 2, where w e delib erately tried to mimic the pseudo co de of Figure 1. Notice that in Figure 2 we ov erloaded the notation for the confidence b ound cb t , which is now defined in terms of the Laplacian L of G . In particular, k u k in Figure 1 is replaced in Figure 2 by k e U k , where e U = A 1 / 2 ⊗ U and we define U = ( u > 1 , u > 2 , . . . , u > n ) > ∈ R dn . Clearly enough, the p otentially unkno wn quan tities k u k and k e U k in the tw o expressions for cb t can b e replaced by suitable upp er b ounds. W e now explain ho w the modified long vectors e φ t,k = A − 1 / 2 ⊗ φ i t ( x t,k ) act in the up date of matrix M t and vector b t . First, observe that if A ⊗ w ere the iden tity matrix then, according to ho w the long v ectors φ i t ( x t,k ) are defined, M t w ould b e a blo ck-diagonal matrix M t = diag( D 1 , . . . , D n ), whose i -th blo ck D i is the d × d matrix D i = I d + P t : k t = i x t x > t . Similarly , b t w ould b e the dn - long v ector whose i -th d -dimensional blo ck contains P t : k t = i a t x t . This would b e equiv alent to running n indep endent linear bandit algorithms (Figure 1), one p er no de of G . Now, b ecause A ⊗ is not the identit y , but contains graph G represented through its Laplacian matrix, the selected v ector x t,k t ∈ C i t for no de i t gets spread via A − 1 / 2 ⊗ from the i t -th blo ck o ver all other blo cks, thereby making the contextual information contain ed in x t,k t a v ailable to up date the in ternal status of all other nodes. Y et, the only reward signal observed at time t is the one av ailable at no de i t . A theoretical analysis of GOB.Lin relying on the learning mo del of Section 3 is sketc hed in Section 4.1. GOB.Lin’s running time is mainly affected by the in version of the dn × dn matrix M t , which can b e p erformed in time of order ( dn ) 2 p er round b y us- ing well-kno wn formulas for incremental matrix inv ersions. The same quadratic dep endence holds for memory requirements. In our experiments, w e observed that pro jecting the con texts on the principal comp onen ts improv ed p erformance. Hence, the quadratic dep endence on the con text vector dimension d is not re- ally h urting us in practice. On the other hand, the quadratic dep endence on the n umber of no des n may b e a significant limitation to GOB.Lin’s practical de- plo yment. In the next section, we show that simple graph compression schemes (lik e no de clustering) can con v eniently be applied to b oth reduce edge noise and bring the algorithm to reasonable scaling b ehaviors. 4.1 Regret Analysis W e no w pro vide a regret analysis for GOB.Lin that relies on the high probabilit y analysis contained in [1] (Theorem 2 therein). The analysis can be seen as a com bination of the m ultitask kernel contained in, e.g., [8, 17, 12] and a version of the linear bandit algorithm describ ed and analyzed in [1]. 7 Theorem 1. L et the GOB.Lin algorithm of Figur e 2 b e run on gr aph G = ( V , E ) , V = { 1 , . . . , n } , hosting at e ach no de i ∈ V ve ctor u i ∈ R d . Define L ( u 1 , . . . , u n ) = X i ∈ V k u i k 2 + X ( i,j ) ∈ E k u i − u j k 2 . L et also the se quenc e of c ontext ve ctors x t,k b e such that k x t,k k ≤ B , for al l k = 1 , . . . , c t , and t = 1 , . . . , T . Then the cumulative r e gr et satisfies T X t =1 r t ≤ 2 s T 2 σ 2 ln | M T | δ + 2 L ( u 1 , . . . , u n ) (1 + B 2 ) ln | M T | with pr ob ability at le ast 1 − δ . Compared to running n indep endent bandit algorithms (which corresp onds to A ⊗ b eing the identit y matrix), the b ound in the ab ov e theorem has an extra term P ( i,j ) ∈ E k u i − u j k 2 , which we assume small according to our working assumption. How ev er, the b ound has also a significantly smaller log determinan t ln | M T | on the resulting matrix M T , due to the construction of e φ t,k via A − 1 / 2 ⊗ . In particular, when the graph is very dense, the log determinant in GOB.Lin is a factor n smaller than the corresp onding term for the n indep enden t bandit case (see, e.g.,[8], Section 4.2 therein). T o make things clear, consider tw o extreme situations. When G has no edges then tr ( M T ) = tr ( I ) + T = nd + T , hence ln | M T | ≤ dn ln(1 + T / ( dn )). On the other hand, When G is the complete graph then tr ( M T ) = tr ( I ) + 2 t/ ( n + 1) = nd + 2 T / ( n + 1), hence ln | M T | ≤ dn ln(1 + 2 T / ( dn ( n + 1))). The exact b ehavior of ln | M t | (one that w ould ensure a significant adv antage in practice) dep ends on the actual interpla y b et ween the data and the graph, so that the ab ov e linear dep endence on dn is really a coarse upp er b ound. 5 Exp erimen ts In this section, w e presen t an empirical comparison of GOB.Lin (and its v ari- an ts) to linear bandit algorithms whic h do not exploit the relational information pro vided b y the graph. W e run our experiments b y appro ximating the cb t func- tion in Figure 1 with the simplified expression α q x > t,k M − 1 t − 1 x t,k log( t + 1), and the cb t function in Figure 2 with the corresp onding expression in whic h x t,k is replaced by e φ t,k . In b oth cases, the factor α is used as tunable parameter. Our preliminary exp erimen ts show that this approximation do es not affect the predictiv e performances of the algorithms, while it sp eeds up computation sig- nifican tly . W e tested our algorithm and its comp etitors on a synthetic dataset and t wo freely a v ailable real-w orld datasets extracted from the so cial bo okmark- ing web service Delicious and from the music s treaming service Last.fm. These datasets are structured as follo ws. 8 4Cliques. This is an artificial dataset whose graph contains four cliques of 25 no des eac h to whic h we added graph noise. This noise consists in picking a random pair of nodes and deleting or creating an edge b etw een them. More precisely , we created a n × n symmetric noise matrix of random num b ers in [0 , 1], and w e selected a threshold v alue suc h that the expected n umber of matrix elemen ts ab ov e this v alue is exactly some chosen noise rate parameter. Then w e set to 1 all the entries whose conten t is ab ov e the threshold, and to zero the remaining ones. Finally , we X ORed the noise matrix with the graph adjacency matrix, thus obtaining a noisy version of the original graph. Last.fm. This is a so cial net work con taining 1 , 892 no des and 12 , 717 edges. There are 17 , 632 items (artists), describ ed by 11 , 946 tags. The dataset contains information ab out the listened artists, and we used this information in order to create the pa yoffs: if a user listened to an artist at least once the pay off is 1, otherwise the pay off is 0. Delicious. This is a net w ork with 1 , 861 no des and 7 , 668 edges. There are 69 , 226 items (URLs) describ ed by 53 , 388 tags. The pay offs were created using the information ab out the b o okmark ed URLs for each user: the pay off is 1 if the user b o okmarked the URL, otherwise the pay off is 0. Last.fm and Delicious were created by the Information Retriev al group at Univ ersidad Autonoma de Madrid for the HetRec 2011 W orkshop [6] with the goal of inv estigating the usage of heterogeneous information in recommendation systems. 3 These tw o net w orks are structurally different: on Delicious, pay offs dep end on users more strongly than on Last.fm. In other words, there are more p opular artists, whom everybo dy listens to, than p opular websites, which ev eryb o dy bo okmarks —see Figure ?? . This mak es a huge difference in practice, and the c hoice of these tw o datasets allo w us to mak e a more realistic comparison of recommendation techniques. Since we did not remov e any items from these datasets (neither the most frequent nor the least frequent), these differences do influence the b ehavior of all algorithms —see b elow. Some statistics ab out Last.fm and Delicious are rep orted in T able 1. In Figure ?? we plotted the distribution of the num ber of preferences p er item in order to make clear and visible the differences explained in the previous paragraphs. 4 3 Datasets and their full descriptions are av ailable at www.grouplens.org/node/462 . 4 In the context of recommender systems, these t wo datasets ma y be seen as representativ es of two “mark ets” whose products hav e significantly different market shares (the well-kno wn dichotom y of hit vs. niche products). Niche product markets giv e rise to p o wer la ws in user preference statistics (as in the blue plot of Figure ?? ). 9 Last.fm Delicious Nodes 1892 1867 Edges 12717 7668 A v g. degree 13.443 8.21 Items 17632 69226 Nonzero p a yoffs 92834 104799 T ags 11946 53388 T able 1: Main statistics for Last.fm and Delicious. Items coun ts the ov erall n umber of items, across all users, from which C t is selected. Nonzero p a yoffs is the num ber of pairs (user, item) for whic h we hav e a nonzero pay off. T a gs is the num b er of distinct tags that were used to describ e the items. W e prepro cessed datasets by breaking down the tags into smaller tags made up of single words. In fact, many users tend to create tags like “w eb de- sign tutorial css”. This tag has b een splitted in to three smaller tags corre- sp onding to the three words therein. More generally , we splitted all comp ound tags containing underscores, hyphens and ap exes. This makes sense b ecause users create tags indep endently , and we ma y hav e b oth “ro c k and roll” and “ro c k n roll”. Because of this splitting op eration, the num b er of unique tags decreased from 11 , 946 to 6 , 036 on Last.fm and from 53 , 388 to 9 , 949 on Deli- cious. On Delicious, we also remov ed all tags o ccurring less than ten times. 5 The algorithms w e tested do not use an y prior information ab out whic h user pro vided a sp ecific tag. W e used all tags asso ciated with a single item to create a TF-IDF context vector that uniquely represents that item, indep endent of whic h user the item is prop osed to. In b oth datasets, we only retained the first 25 principal comp onents of con text vectors, so that x t,k ∈ R 25 for all t and k . W e generated random context sets C i t of size 25 for Last.fm and Delicious, and of size 10 for 4Cliques. In practical scenarios, these n umbers w ould be v arying o ver time, but we k ept them fixed so as to simplify the exp erimental setting. In 4Cliques w e assigned the same unit norm random vector u i to ev ery no de in the same clique i of the original graph (before adding graph noise). P ay offs were then generated according to the following stochastic mo del: a i ( x ) = u > i x + , where (the pa yoff noise) is uniformly distributed in a bounded in terv al cen tered around zero. F or Delicious and Last.fm, we created a set of context vectors for ev ery round t as follows: w e first pick ed i t uniformly at random in { 1 , . . . , n } . Then, we generated context vectors x t, 1 , . . . , x t, 25 in C i t b y picking 24 vectors at random from the dataset and one among those vectors with nonzero pa yoff for user i t . This is necessary in order to av oid a meaningless comparison: with high probability , a purely random selection would result in pay offs equal to zero for all the con text vectors in C i t . 5 W e did not rep eat the same op eration on Last.fm because this dataset was already extremely sparse. 10 0 500 1000 1500 2000 2500 3000 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME 4Cliques graph-noise=0% payoff-noise=0 GOB.Lin LinUCB-IND LinUCB-SIN 0 500 1000 1500 2000 2500 3000 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME 4Cliques graph-noise=0% payoff-noise=0.25 GOB.Lin LinUCB-IND LinUCB-SIN 0 500 1000 1500 2000 2500 3000 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME 4Cliques graph-noise=0% payoff-noise=0.5 GOB.Lin LinUCB-IND LinUCB-SIN 0 500 1000 1500 2000 2500 3000 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME 4Cliques graph-noise=8.3% payoff-noise=0 GOB.Lin LinUCB-IND LinUCB-SIN 0 500 1000 1500 2000 2500 3000 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME 4Cliques graph-noise=8.3% payoff-noise=0.25 GOB.Lin LinUCB-IND LinUCB-SIN 0 500 1000 1500 2000 2500 3000 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME 4Cliques graph-noise=8.3% payoff-noise=0.5 GOB.Lin LinUCB-IND LinUCB-SIN 0 500 1000 1500 2000 2500 3000 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME 4Cliques graph-noise=20.8% payoff-noise=0 GOB.Lin LinUCB-IND LinUCB-SIN 0 500 1000 1500 2000 2500 3000 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME 4Cliques graph-noise=20.8% payoff-noise=0.25 GOB.Lin LinUCB-IND LinUCB-SIN 0 500 1000 1500 2000 2500 3000 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME 4Cliques graph-noise=20.8% payoff-noise=0.5 GOB.Lin LinUCB-IND LinUCB-SIN 0 500 1000 1500 2000 2500 3000 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME 4Cliques graph-noise=41.7% payoff-noise=0 GOB.Lin LinUCB-IND LinUCB-SIN 0 500 1000 1500 2000 2500 3000 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME 4Cliques graph-noise=41.7% payoff-noise=0.25 GOB.Lin LinUCB-IND LinUCB-SIN 0 500 1000 1500 2000 2500 3000 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME 4Cliques graph-noise=41.7% payoff-noise=0.5 GOB.Lin LinUCB-IND LinUCB-SIN T able 2: Normalized cumulated reward for differen t levels of graph noise (ex- p ected fraction of perturb ed edges) and pay off noise (largest absolute v alue of noise term ) on the 4Cliques dataset. Graph noise increases from top to b ot- tom, pay off noise increases from left to righ t. GOB.Lin is clearly more robust to pay off noise than its comp etitors. On the other hand, GOB.Lin is sensitive to high lev els of graph noise. In the last row, graph noise is 41 . 7%, i.e., the n umber of p erturb ed edges is 500 out of 1200 edges of the original graph. In our exp erimen tal comparison, we tested GOB.Lin and its v ariants against t wo baselines: a baseline LinUCB-IND that runs an indep enden t instance of the algorithm in Figure 1 at each no de (this is equiv alen t to running GOB.Lin in Figure 2 with A ⊗ = I dn ) and a baseline LinUCB-SIN, whic h runs a single instance of the algorithm in Figure 1 shared by all the no des. LinUCB-IND lends itself to b e a reasonable comparator when, as in the Delicious dataset, there are many mo derately p opular items. On the other hand, LinUCB-SIN is a comp etitive baseline when, as in the Last.fm dataset, there are few v ery p opular items. The tw o scalable v arian ts of GOB.Lin which we empirically 11 0 250 500 750 1000 1250 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME Last.fm LinUCB-SIN LinUCB-IND GOB.Lin GOB.Lin.MACRO GOB.Lin.BLOCK 0 25 50 75 100 125 150 0 2000 4000 6000 8000 10000 CUMULATIVE REWARD TIME Delicious LinUCB-SIN LinUCB-IND GOB.Lin GOB.Lin.MACRO GOB.Lin.BLOCK Figure 3: Cumulativ e reward for all the bandit algorithms introduced in this section. analyzed are based on no de clustering, 6 and are defined as follo ws. GOB.Lin.MA CR O: GOB.Lin is run on a weighte d graph whose no des are the clusters of the original graph. The edges are weigh ted by the num b er of in ter-cluster edges in the original graph. When all no des are clustered together, then GOB.Lin.MACR O recov ers the baseline LinUCB-SIN as a sp ecial case. In order to strik e a go o d trade-off b et ween the speed of the algorithms and the loss 6 W e used the freely a v ailable Graclus graph clustering to ol, whose interns are describ ed, e.g., in [11]. W e used Graclus with normalized cut, zero lo cal search steps, and no sp ectral clustering options. 12 of information resulting from clustering, w e tested three different cluster sizes: 50, 100, and 200. Our plots refer to the b est performing c hoice. GOB.Lin.BLOCK: GOB.Lin is run on a disconnected graph whose con- nected comp onents are the clusters. This makes A ⊗ and M t (Figure 2) blo c k-diagonal matrices. When each no de is clustered individually , then GOB.Lin.BLOCK recov ers the baseline LinUCB-IND as a sp ecial case. Similar to GOB.Lin.MA CR O, in order to trade-off running time and cluster sizes, we tested three different cluster sizes (5, 10, and 20), and rep ort only on the b est p erforming choice. As the running time of GOB.Lin scales quadratically with the num b er of no des, the computational sa vings provided by the clustering are also quadratic. More- o ver, as we will see in the exp eriments, the clustering acts as a regularizer, limiting the influence of noise. In all cases, the parameter α in Figures 1 and 2 was selected based on the scale of instance vectors ¯ x t and e φ t,k t , resp ectively , and tuned across appropriate ranges. T able 2 and Figure 3 show the cumulativ e rew ard for each algorithm, as com- pared (“normalized”) to that of the random predictor, that is P t ( a t − ¯ a t ), where a t is the pa yoff obtained by the algorithm and ¯ a t is the pa yoff obtained by the random predictor, i.e., the a v erage pay off ov er the con text vectors av ailable at time t . T able 2 (syn thetic datasets) sho ws that GOB.Lin and LinUCB-SIN are more ro- bust to pa yoff noise than LinUCB-IND. Clearly , LinUCB-SIN is also unaffected b y graph noise, but it nev er outp erforms GOB.Lin. When the pay off noise is lo w and the graph noise grows GOB.Lin’s p erformance tends to degrade. Figure 3 rep orts the results on the tw o real-w orld datasets. Notice that GOB.Lin and its v ariants alwa ys outp erform the baselines (not relying on graphical in- formation) on b oth datasets. As exp ected, GOB.Lin.MACR O w orks b est on Last.fm, where many users gav e p ositiv e pay offs to the same few items. Hence, macro no des apparently help GOB.Lin.MACR O to p erform b etter than its cor- resp onding baseline LinUCB-SIN. In fact, GOB.Lin.MACR O also outp erforms GOB.Lin, thus sho wing the regularization effect of using macro no des. On Deli- cious, where we hav e many mo derately p opular items, GOB.Lin.BLOCK tends to p erform b est, GOB.Lin b eing the runner-up. As exp ected, LinUCB-IND w orks b etter than LinUCB-SIN, since the former is clearly more prone to p er- sonalize item recommendation than the latter. In summary , w e may conclude that our system is able to exploit the information pro vided by the graphical structure. Moreo ver, regularization via graph clustering seems to b e of signifi- can t help. F uture work will consider experiments against different metho ds for sharing con textual and feedback information in a set of users, such as the feature hashing tec hnique of [22]. 13 References [1] Y. Abbasi-Y adk ori, D. P´ al, and C. Szep esv´ ari. Improv ed algorithms for linear sto c hastic bandits. A dvanc es in Neur al Information Pr o c essing Sys- tems , 2011. [2] K. Amin, M. Kearns, and U. Syed. Graphical mo dels for bandit problems. Pr o c e e dings of the Twenty-Seventh Confer enc e Unc ertainty in Artificial In- tel ligenc e , 2011. [3] D. Asanov. Algorithms and metho ds in recommender systems. Berlin Institute of T e chnolo gy, Berlin, Germany , 2011. [4] P . Auer. Using confidence b ounds for exploration-exploitation trade-offs. Journal of Machine L e arning R ese ar ch , 3:397–422, 2002. [5] T. Bogers. Movie recommendation using random w alks o ver the con textual graph. In CARS’10: Pr o c e e dings of the 2nd Workshop on Context-Awar e R e c ommender Systems , 2010. [6] I. Cantador, P . Brusilovsky , and T. Kuflik. 2nd Workshop on Information Heterogeneit y and Fusion in Recommender Systems (HetRec 2011). In Pr o c e e dings of the 5th ACM Confer enc e on R e c ommender Systems , RecSys 2011. ACM, 2011. [7] S. Caron, B. Kveton, M. Lelarge, and S. Bhagat. Lev eraging side obser- v ations in sto chastic bandits. In Pr o c e e dings of the 28th Confer enc e on Unc ertainty in Artificial Intel ligenc e , pages 142–151, 2012. [8] G. Ca v allanti, N. Cesa-Bianc hi, and C. Gen tile. Linear algorithms for online m ultitask classification. Journal of Machine L e arning R ese ar ch , 11:2597– 2630, 2010. [9] W. Ch u, L. Li, L. Reyzin, and R. E. Schapire. Contextual bandits with linear pa yoff functions. In Pr o c e e dings of the International Confer enc e on A rtificial Intel ligenc e and Statistics , pages 208–214, 2011. [10] K. Crammer and C. Gentile. Multiclass classification with bandit feedback using adaptive regularization. Machine L e arning , 90(3):347–383, 2013. [11] I. S. Dhillon, Y. Guan, and B. Kulis. W eighted graph cuts without eigen- v ectors a multilev el approach. Pattern A nalysis and Machine Intel ligenc e, IEEE T r ansactions on , 29(11):1944–1957, 2007. [12] T. Evgeniou and M. Pon til. Regularized m ulti–task learning. In Pr o c e e d- ings of the tenth ACM SIGKDD international c onfer enc e on Know le dge disc overy and data mining , KDD ’04, pages 109–117, New Y ork, NY, USA, 2004. ACM. 14 [13] I. Guy , N. Zw erdling, D. Carmel, I. Ronen, E. Uziel, S. Y ogev, and S. Ofek- Koifman. Personalized recommendation of so cial softw are items based on so cial relations. In Pr o c e e dings of the Thir d A CM Confer enc e on R e c om- mender Sarxiv ystems , pages 53–60. A CM, 2009. [14] S. Kar, H. V. Poor, and S. Cui. Bandit problems in net works: Asymp- totically efficient distributed allo cation rules. In De cision and Contr ol and Eur op e an Contr ol Confer enc e (CDC-ECC), 2011 50th IEEE Confer enc e on , pages 1771–1778. IEEE, 2011. [15] L. Li, W. Chu, J. Langford, and R. E. Schapire. A con textual-bandit approac h to personalized news article recommendation. In Pr o c e e dings of the 19th International Confer enc e on World Wide Web , pages 661–670. A CM, 2010. [16] S. Mannor and O. Shamir. F rom bandits to experts: On the v alue of side- observ ations. In A dvanc es in Neur al Information Pr o c essing Systems , pages 684–692, 2011. [17] C. A. Micchelli and M. P on til. Kernels for m ulti–task learning. In A dvanc es in Neur al Information Pr o c essing Systems , pages 921–928, 2004. [18] A. Said, E. W. De Luca, and S. Alba yrak. Ho w so cial relationships affect user similarities. In Pr o c e e dings of the 2010 Workshop on So cial R e c om- mender Systems , pages 1–4, 2010. [19] A. Slivkins. Contextual bandits with similarity information. Journal of Machine L e arning R ese ar ch – Pr o c e e dings T r ack , 19:679–702, 2011. [20] B. Swapna, A. Eryilmaz, and N. B. Shroff. Multi-armed bandits in the presence of side observ ations in so cial netw orks. In Pr o c e e dings of 52nd IEEE Confer enc e on De cision and Contr ol (CDC) , 2013. [21] B. Sz¨ or´ enyi, R. Busa-F ekete, I. Hegedus, R. Orm´ andi, M. Jelasity , and B. K´ egl. Gossip-based distributed sto c hastic bandit algorithms. Pr o c e e dings of the 30th International Confer enc e on Machine L e arning , 2013. [22] K. W einberger, A. Dasgupta, J. Langford, A. Smola, and J. Atten berg. F ea- ture hashing for large scale multitask learning. In Pr o c e e dings of the 26th International Confer enc e on Machine L e arning , pages 1113–1120. Omni- press, 2009. A App endix This app endix contains the proof of Theorem 1. Pr o of. Recall that e U = A 1 / 2 ⊗ U where U = ( u > 1 , u > 2 , . . . , u > n ) > ∈ R dn . 15 Let then t b e a fixed time step, and introduce the following shorthand notation: x ∗ t = argmax k =1 ,...,c t u > i t x t,k and e φ ∗ t = argmax k =1 ,...,c t e U > e φ t,k . Notice that, for an y k we hav e e U > e φ t,k = U > A 1 / 2 ⊗ A − 1 / 2 ⊗ φ i t ( x t,k ) = U > φ i t ( x t,k ) = u > i t x t,k . Hence we decomp ose the time- t regret r t as follows: r t = u > i t x ∗ t − u > i t x t,k t = e U > e φ ∗ t − e U > e φ t,k t = e U > e φ ∗ t − w > t − 1 e φ ∗ t + w > t − 1 e φ ∗ t + cb t ( e φ ∗ t ) − cb t ( e φ ∗ t ) − e U > e φ t,k t ≤ e U > e φ ∗ t − w > t − 1 e φ ∗ t + w > t − 1 e φ t,k t + cb t ( e φ t,k t ) − cb t ( e φ ∗ t ) − e U > e φ t,k t , the inequality deriving from w > t − 1 e φ t,k t + cb t ( e φ t,k t ) ≥ w > t − 1 e φ t,k + cb t ( e φ t,k ) , k = 1 , . . . , c t . A t this p oint, we rely on [1] (Theorem 2 therein with λ = 1) to show that e U > e φ ∗ t − w > t − 1 e φ ∗ t ≤ cb t ( e φ ∗ t ) and w > t − 1 e φ t,k t − e U > e φ t,k t ≤ cb t ( e φ t,k t ) b oth hold simultaneously for all t with probability at least 1 − δ ov er the noise sequence. Hence, with the same probability , r t ≤ 2 cb t ( e φ t,k t ) holds uniformly ov er t . Thus the cumulativ e regret P T t =1 r t satisfies T X t =1 r t ≤ v u u t T T X t =1 r 2 t ≤ 2 v u u t T T X t =1 cb t ( e φ t,k t ) 2 ≤ 2 v u u t T σ r ln | M T | δ + k e U k ! 2 T X t =1 e φ > t,k t M − 1 t − 1 e φ t,k t . No w, using (see, e.g., [ ? ]) T X t =1 e φ > t,k t M − 1 t − 1 e φ t,k t ≤ (1 + max k =1 ,...,c t k e φ t,k k 2 ) ln | M T | , 16 with max k =1 ,...,c t k e φ t,k k 2 = max k =1 ,...,c t φ i t ( x t,k ) A − 1 ⊗ φ i t ( x t,k ) ≤ max k =1 ,...,c t k φ i t ( x t,k ) k 2 = max k =1 ,...,c t k x t,k k 2 ≤ B 2 , along with ( a + b ) 2 ≤ 2 a 2 + 2 b 2 applied with a = σ q ln | M T | δ and b = k e U k yields T X t =1 r t ≤ 2 s T 2 σ 2 ln | M T | δ + 2 k e U k 2 (1 + B 2 ) ln | M T | . Finally , observing that k e U k 2 = U > A ⊗ U = L ( u 1 , . . . , u n ) giv es the desired b ound. 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment