Outlier detection in default logics: the tractability/intractability frontier
In default theories, outliers denote sets of literals featuring unexpected properties. In previous papers, we have defined outliers in default logics and investigated their formal properties. Specifically, we have looked into the computational complexity of outlier detection problems and proved that while they are generally intractable, interesting tractable cases can be singled out. Following those results, we study here the tractability frontier in outlier detection problems, by analyzing it with respect to (i) the considered outlier detection problem, (ii) the reference default logic fragment, and (iii) the adopted notion of outlier. As for point (i), we shall consider three problems of increasing complexity, called Outlier-Witness Recognition, Outlier Recognition and Outlier Existence, respectively. As for point (ii), as we look for conditions under which outlier detection can be done efficiently, attention will be limited to subsets of Disjunction-free propositional default theories. As for point (iii), we shall refer to both the notion of outlier of [ABP08] and a new and more restrictive one, called strong outlier. After complexity results, we present a polynomial time algorithm for enumerating all strong outliers of bounded size in an quasi-acyclic normal unary default theory. Some of our tractability results rely on the Incremental Lemma that provides conditions for a deafult logic fragment to have a monotonic behavior. Finally, in order to show that the simple fragments of DL we deal with are still rich enough to solve interesting problems and, therefore, the tractability results that we prove are interesting not only on the mere theoretical side, insights into the expressive capabilities of these fragments are provided, by showing that normal unary theories express all NL queries, hereby indirectly answering a question raised by Kautz and Selman.
💡 Research Summary
The paper investigates the computational complexity of outlier detection within Reiter’s propositional default logic, focusing on three increasingly difficult decision problems: Outlier‑Witness Recognition, Outlier Recognition, and Outlier Existence. An outlier is a set of literals whose presence cannot be justified by the underlying default theory, while a witness is a set of literals that explains why a given set is considered an outlier. The authors consider two notions of outlier: the original definition from Angiulli et al. (2008) and a stricter “strong outlier” concept that requires a tighter relationship between the outlier and its witness.
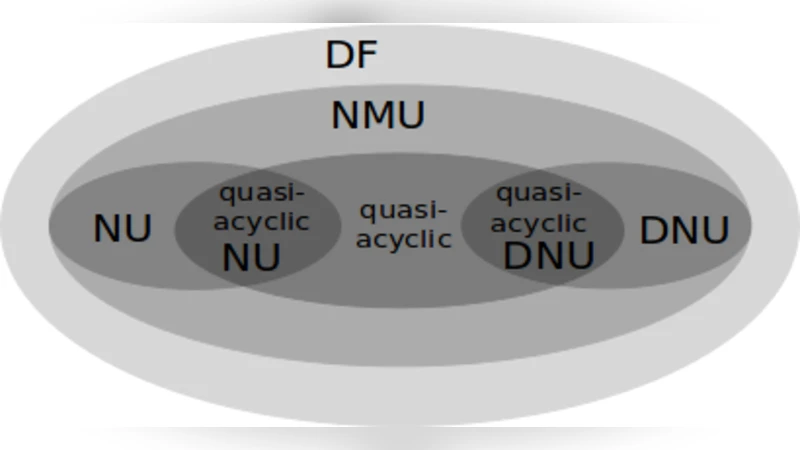
The analysis is carried out over several well‑studied fragments of default logic that are disjunction‑free (DF). The fragments examined include Normal Unary (NU) theories, Dual Normal Unary (DNU) theories, Mixed Normal Unary (NMU) theories, and quasi‑acyclic variants of NMU where the size of the largest strongly connected component (tightness) is bounded by a constant. These fragments are chosen because they retain enough expressive power to model interesting problems while allowing for tractable algorithmic treatment.
Key technical contributions are:
-
Complexity Classification
- Outlier‑Witness Recognition is shown to be solvable in polynomial time for NU theories. The problem reduces to checking consistency of the given outlier‑witness pair, which can be done efficiently.
- Outlier Recognition is NP‑hard for NMU theories under the original outlier definition. However, when the stronger outlier notion is used and the theory is quasi‑acyclic, the problem becomes tractable.
- Outlier Existence, the most general problem, remains NP‑hard even for NU theories. The authors identify structural restrictions that make the problem easier, but in the unrestricted setting it inherits the hardness of the underlying reasoning tasks.
-
Incremental Lemma
The paper introduces an “Incremental Lemma” that characterizes a monotonicity property of NMU fragments. It states that adding defaults to an NMU theory cannot invalidate extensions already present in a smaller theory. This lemma is crucial for proving tractability results in the quasi‑acyclic setting. -
Strong Outlier Enumeration Algorithm
Leveraging the Incremental Lemma and the bounded tightness of quasi‑acyclic NMU theories, the authors devise a polynomial‑time algorithm that enumerates all strong outliers of size at most k. The algorithm builds the atomic dependency graph of the theory, computes its strongly connected components, and performs a bounded search guided by the graph structure, thereby avoiding exponential blow‑up. -
Expressiveness Result
The paper proves that normal unary theories can express all NL (nondeterministic log‑space) queries. This answers a question raised by Kautz and Selman about the computational power of simple default‑logic fragments, showing that despite their syntactic restrictions they are computationally rich enough to capture log‑space computations.
The paper is organized as follows: after an introductory motivation (e.g., credit‑card fraud detection) and a review of related work, Section 2 presents necessary preliminaries on complexity classes, default logic syntax and semantics, and the formal definitions of outliers and the three decision problems. Section 3 discusses the expressive capabilities of the considered fragments and proves the Incremental Lemma. Section 4 contains a technical lemma linking CNF evaluation to outlier definitions. Sections 5‑7 deliver the main complexity results for the three problems, distinguishing between the original and strong outlier notions and between NU, NMU, and quasi‑acyclic NMU fragments. Section 8 describes the strong outlier enumeration algorithm in detail and proves its polynomial‑time bound. Section 9 discusses the transition between tractable and intractable regimes, emphasizing the role of structural parameters such as tightness and the presence of cycles in the dependency graph. Finally, Section 10 concludes with a summary of contributions and suggestions for future research, including extensions to richer default‑logic fragments and applications to real‑world anomaly detection systems.
Overall, the work maps the tractability frontier for outlier detection in default logic, showing that while the general problems are computationally hard, meaningful restrictions on the logic fragment and a stricter outlier definition yield efficient algorithms. The results have implications for knowledge‑base maintenance, non‑monotonic reasoning systems, and practical anomaly‑detection scenarios where default reasoning is employed.
Comments & Academic Discussion
Loading comments...
Leave a Comment