GRE: A Graph Runtime Engine for Large-Scale Distributed Graph-Parallel Applications
Large-scale distributed graph-parallel computing is challenging. On one hand, due to the irregular computation pattern and lack of locality, it is hard to express parallelism efficiently. On the other hand, due to the scale-free nature, real-world graphs are hard to partition in balance with low cut. To address these challenges, several graph-parallel frameworks including Pregel and GraphLab (PowerGraph) have been developed recently. In this paper, we present an alternative framework, Graph Runtime Engine (GRE). While retaining the vertex-centric programming model, GRE proposes two new abstractions: 1) a Scatter-Combine computation model based on active message to exploit massive fined-grained edge-level parallelism, and 2) a Agent-Graph data model based on vertex factorization to partition and represent directed graphs. GRE is implemented on commercial off-the-shelf multi-core cluster. We experimentally evaluate GRE with three benchmark programs (PageRank, Single Source Shortest Path and Connected Components) on real-world and synthetic graphs of millions billion of vertices. Compared to PowerGraph, GRE shows 2.517 times better performance on 816 machines (192 cores). Specifically, the PageRank in GRE is the fastest when comparing to counterparts of other frameworks (PowerGraph, Spark,Twister) reported in public literatures. Besides, GRE significantly optimizes memory usage so that it can process a large graph of 1 billion vertices and 17 billion edges on our cluster with totally 768GB memory, while PowerGraph can only process less than half of this graph scale.
💡 Research Summary
The paper introduces the Graph Runtime Engine (GRE), a new framework for large‑scale distributed graph‑parallel computation that builds on the vertex‑centric programming model but adds two novel abstractions: the Scatter‑Combine computation model and the Agent‑Graph data model. The authors first identify two fundamental challenges in distributed graph processing: (1) irregular computation patterns that make parallelism hard to express efficiently, and (2) the scale‑free nature of real‑world graphs that leads to highly imbalanced partitions with large edge cuts. Existing systems such as Pregel, GraphLab, and PowerGraph address these issues to varying degrees, but each still suffers from either excessive intermediate storage (GAS model) or costly consistency maintenance (vertex‑cut).
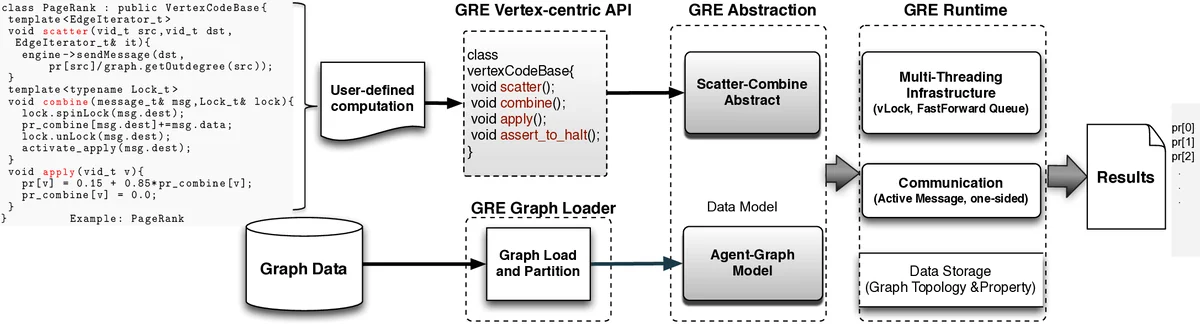
The Scatter‑Combine model replaces the traditional Gather‑Apply‑Scatter (GAS) abstraction with an active‑message‑based approach. In this model, a source vertex generates a message during the scatter phase that already contains the operation to be applied at the destination. When the message arrives, the destination vertex immediately combines the payload using a user‑defined combine function, eliminating the need for a separate gather phase and intermediate message buffers. This one‑sided communication reduces both memory footprint and network traffic. To handle concurrent combines on the same vertex, GRE employs fine‑grained vertex‑level spin locks, enabling massive edge‑level parallelism on multi‑core machines without sacrificing correctness.
The Agent‑Graph model tackles the partitioning problem. While PowerGraph introduced vertex‑cut to reduce edge cuts, it requires a master‑mirror scheme that incurs synchronization overhead. GRE instead splits each logical vertex into a “real” vertex that holds the state locally and one or more temporary “agent” vertices that act as lightweight carriers for messages crossing partition boundaries. Agents exist only for the duration of a message transfer, so there is no persistent replica state to keep consistent. This design dramatically lowers the communication volume and simplifies partitioning, especially for high‑degree hubs that dominate scale‑free graphs.
Implementation details are provided: GRE is written in C++ using template metaprogramming. The system consists of a graph loader that converts input graphs into the Agent‑Graph representation, an abstraction layer exposing only three user‑implemented methods (scatter, combine, apply), and a runtime layer that leverages RDMA‑based one‑sided communication together with the lock mechanism.
The authors evaluate GRE on three classic graph algorithms—PageRank, Single‑Source Shortest Path (SSSP), and Connected Components (CC)—using both real‑world and synthetic datasets ranging from millions to billions of vertices. On a cluster of 8 to 16 machines (192 cores total), GRE outperforms PowerGraph by a factor of 2.5 to 17, depending on the algorithm and dataset. Notably, GRE’s PageRank implementation completes an iteration in 2.19 seconds on 192 cores, whereas the best reported PowerGraph result (on 64 machines, 512 cores) requires 3.6 seconds per iteration. Memory usage is also substantially reduced: GRE can process a graph with 1 billion vertices and 17 billion edges on a machine equipped with 768 GB of RAM, while PowerGraph fails to handle even half that size.
In summary, GRE demonstrates that by integrating active‑message‑driven edge‑level parallelism (Scatter‑Combine) with a temporally‑scoped agent‑based graph representation (Agent‑Graph), it is possible to overcome the dominant bottlenecks of existing distributed graph frameworks. The result is a system that delivers superior performance, scalability, and memory efficiency, making it a compelling platform for next‑generation large‑scale graph analytics.
Comments & Academic Discussion
Loading comments...
Leave a Comment