Scalable Locality-Sensitive Hashing for Similarity Search in High-Dimensional, Large-Scale Multimedia Datasets
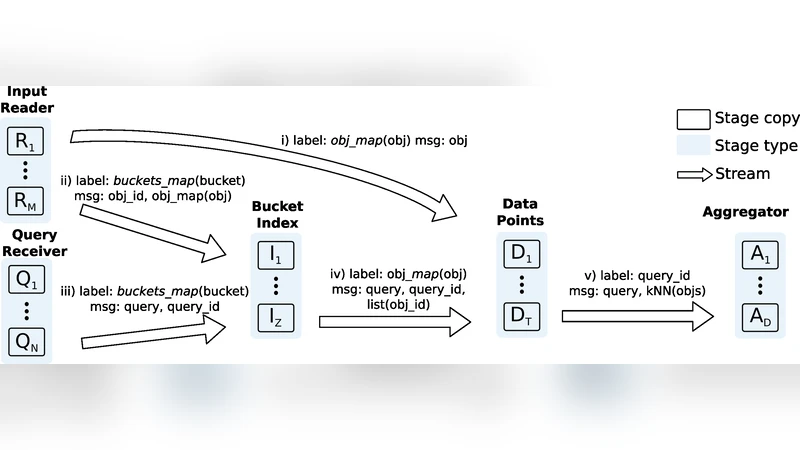
Similarity search is critical for many database applications, including the increasingly popular online services for Content-Based Multimedia Retrieval (CBMR). These services, which include image search engines, must handle an overwhelming volume of data, while keeping low response times. Thus, scalability is imperative for similarity search in Web-scale applications, but most existing methods are sequential and target shared-memory machines. Here we address these issues with a distributed, efficient, and scalable index based on Locality-Sensitive Hashing (LSH). LSH is one of the most efficient and popular techniques for similarity search, but its poor referential locality properties has made its implementation a challenging problem. Our solution is based on a widely asynchronous dataflow parallelization with a number of optimizations that include a hierarchical parallelization to decouple indexing and data storage, locality-aware data partition strategies to reduce message passing, and multi-probing to limit memory usage. The proposed parallelization attained an efficiency of 90% in a distributed system with about 800 CPU cores. In particular, the original locality-aware data partition reduced the number of messages exchanged in 30%. Our parallel LSH was evaluated using the largest public dataset for similarity search (to the best of our knowledge) with $10^9$ 128-d SIFT descriptors extracted from Web images. This is two orders of magnitude larger than datasets that previous LSH parallelizations could handle.
💡 Research Summary
This paper addresses the scalability challenges of similarity search for high‑dimensional multimedia data in web‑scale applications. While Locality‑Sensitive Hashing (LSH) is a well‑known technique for approximate nearest‑neighbor (ANN) search, its poor referential locality makes distributed implementations difficult: hash buckets and the actual vectors often reside on different machines, leading to excessive network traffic. The authors propose a comprehensive distributed LSH framework that combines several innovations. First, they decompose LSH into a data‑flow pipeline consisting of distinct stages for bucket generation, bucket‑to‑data mapping, and candidate ranking, each implemented as a multithreaded process. This enables fine‑grained asynchronous overlap of computation and communication. Second, a hierarchical parallelization groups data partitions at the node level rather than per CPU core, dramatically reducing the number of partitions and inter‑node messages. Third, a locality‑aware partitioning strategy analyses the distribution of hash values and co‑locates buckets with similar keys on the same or neighboring nodes, achieving a reported 30 % reduction in message volume. Fourth, the framework incorporates multi‑probe LSH: instead of building many independent hash tables (large L), each table is probed at multiple nearby buckets, selected in order of increasing hash‑value distance. This reduces the required number of tables, cuts memory consumption by more than 40 % compared with classic LSH, and preserves search quality. The system was evaluated on the largest publicly available similarity‑search dataset—a billion 128‑dimensional SIFT descriptors extracted from web images—approximately two orders of magnitude larger than datasets used in prior distributed LSH work. Experiments on a 51‑node cluster (≈800 CPU cores) achieved about 90 % parallel efficiency, average query latencies of 1–3 seconds, and sublinear growth of communication as the number of probes increased. The authors also contrast their approach with earlier MapReduce‑based LSH implementations, which suffered from massive data replication and high latency due to HDFS file access. By avoiding data replication, using asynchronous pipelines, and limiting the number of hash tables through multi‑probing, the proposed design is suitable for real‑time content‑based multimedia retrieval services such as image search engines, video frame matching, and audio identification. The paper concludes with suggestions for future extensions, including GPU acceleration and hybrid cloud deployments, indicating that the presented techniques provide a solid foundation for scalable, low‑latency ANN search on massive high‑dimensional datasets.
Comments & Academic Discussion
Loading comments...
Leave a Comment