Solving OSCAR regularization problems by proximal splitting algorithms
The OSCAR (octagonal selection and clustering algorithm for regression) regularizer consists of a L_1 norm plus a pair-wise L_inf norm (responsible for its grouping behavior) and was proposed to encourage group sparsity in scenarios where the groups …
Authors: Xiangrong Zeng, Mario A. T. Figueiredo
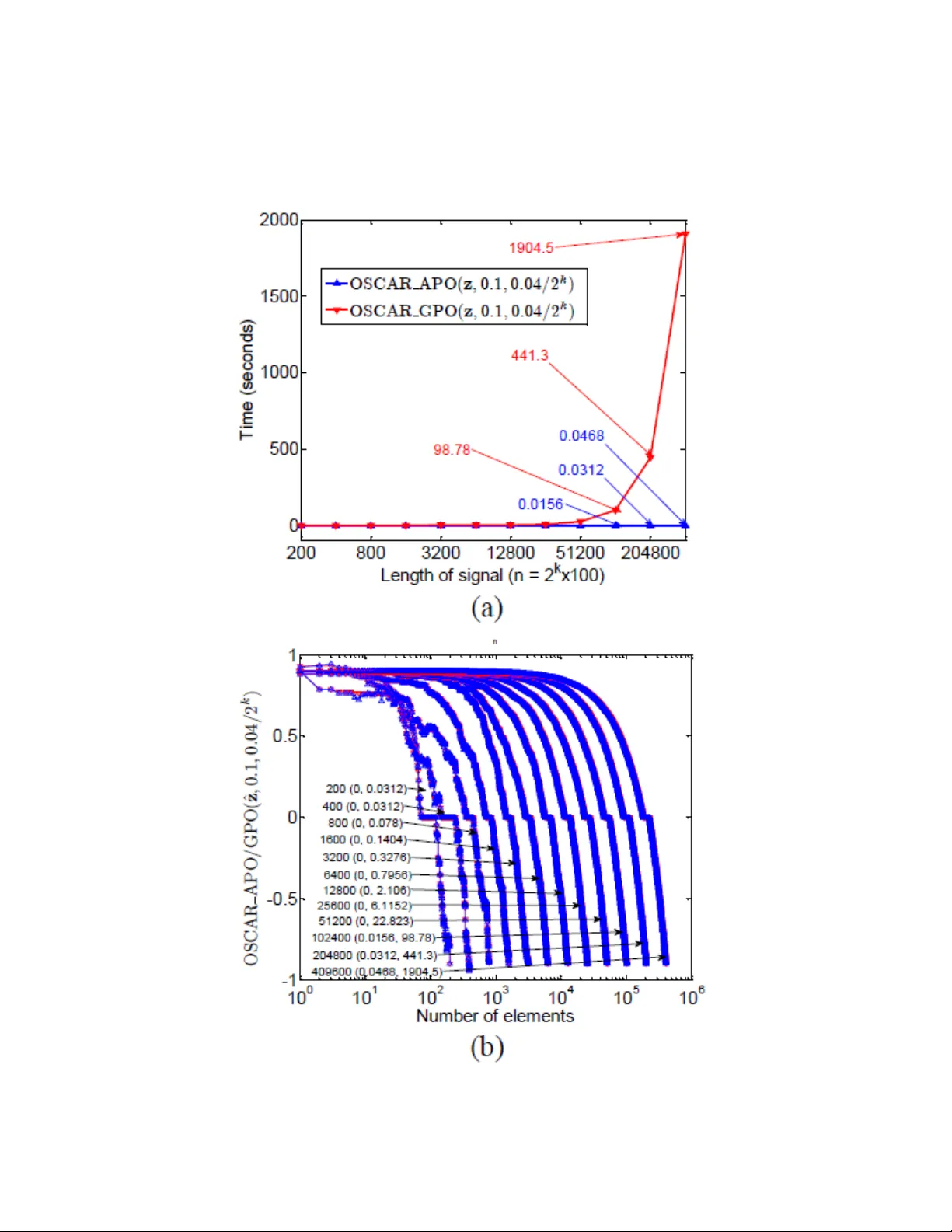
Solving OSCAR regularization problems b y pro ximal splitting algorithms Xiangrong Zeng a, ∗ , M´ ario A. T. Figueiredo a, ∗∗ a Instituto de T ele c omunic a¸ c˜ oes, Instituto Sup erior T ´ ecnic o, 1049-001, Lisb o a, Portugal. Abstract The OSCAR ( o ctagonal sele ction and clustering algorithm for r e gr ession ) regularizer consists of a ` 1 norm plus a pair-wise ` ∞ norm (resp onsible for its grouping b eha vior) and w as prop osed to encourage group sparsity in scenarios where the groups are a priori unknown. The OSCAR regularizer has a non- trivial proximit y op erator, which limits its applicability . W e reformulate this regularizer as a weigh ted sorted ` 1 norm, and prop ose its gr ouping pr oximity op er ator (GPO) and appr oximate pr oximity op er ator (APO), th us making state-of-the-art pro ximal splitting algorithms (PSAs) a v ailable to solv e in- v erse problems with O SCAR regularization. The GPO is in fact the APO follo wed b y additional grouping and av eraging op erations, which are costly in time and storage, explaining the reason why algorithms with APO are m uch faster than that with GPO. The con vergences of PSAs with GPO are guaran teed since GPO is an exact pro ximity op erator. Although con v ergence of PSAs with APO is may not b e guaran teed, w e hav e exp erimen tally found that APO b eha ves similarly to GPO when the regularization parameter of the pair-wise ` ∞ norm is set to an appropriately small v alue. Exp erimen ts on reco very of group-sparse signals (with unknown groups) sho w that PSAs with APO are v ery fast and accurate. Keywor ds: Pro ximal splitting algorithms, alternating direction metho d of m ultipliers, iterative thresholding, group sparsity, proximit y op erator, signal reco very, split Bregman ∗ Corresp onding author ∗∗ Principal corresponding author Email addr esses: Xiangrong.Zeng@lx.it.pt (Xiangrong Zeng ), mario.figueiredo@lx.it.pt (M´ ario A. T. Figueiredo ) Pr eprint submitte d to Elsevier Septemb er 30, 2013 1 INTR ODUCTION 2 1. In tro duction In the past few decades, linear inv erse problems hav e attracted a lot of atten tion in a wide range of areas, suc h as statistics, mac hine learning, signal pro cessing, and compressive sensing, to name a few. The t ypical forw ard mo del is y = Ax + n , (1) where y ∈ R m is the measuremen t v ector, x ∈ R n the original signal to b e reco vered, A ∈ R m × n is a known sensing matrix, and n ∈ R m is noise (usually assumed to b e white and Gaussian). In most cases of interest, A is not in vertible ( e.g. , b ecause m < n ), making (1) an ill-posed problem (ev en in the absence of noise), whic h can only b e addressed by using some form of regularization or prior kno wledge ab out the unkno wn x . Classical regularization form ulations seek solutions of problems of the form min x f ( x ) + λ r ( x ) (2) or one of the equiv alent (under mild conditions) forms min x r ( x ) s.t. f ( x ) ≤ ε or min x f ( x ) s.t. r ( x ) ≤ , (3) where, t ypically , f ( x ) = 1 2 k y − Ax k 2 2 is the data-fidelit y term (under a white Gaussian noise assumption), r ( x ) is the regularizer that enforces certain prop- erties on the target solution, and λ , ε , and are non-negativ e parameters. A t yp e of prior knowledge that has been the fo cus of muc h recen t attention (namely with the adv ent of compressive sensing – CS – [10], [22]) is sparsit y , i.e. , that a large fraction of the comp onents of x are zero [26]. The ideal regularizer encouraging solutions with the smallest p ossible num b er of non- zero en tries is r ` 0 ( x ) = k x k 0 (whic h corresp onds to th e num b er of non-zero elemen ts of x ), but the resulting problem is of combinatorial nature and kno wn to b e NP-hard [12], [40]. The LASSO ( le ast absolute shrinkage and sele ction op er ator ) [52] uses the ` 1 norm, r LASSO ( x ) = k x k 1 = P i | x i | , is arguably the most popular sparsity-encouraging regularizer. The ` 1 norm can b e seen as the tightest con v ex appro ximation of the ` 0 “norm” (it’s not a norm) and, under conditions that are ob ject of study in CS [11], yields the same solution. Man y v ariants of these regularizers ha ve b een prop osed, such as ` p (for p ∈ [0 , 1]) “norms” [15, 17], and rew eigh ted ` 1 [13, 56, 61] and ` 2 norms [20, 56, 16]. 1 INTR ODUCTION 3 1.1. Gr oup-sp arsity-inducing R e gularizers In recen t y ears, muc h attention has been paid not only to the sparsity of solutions but also to the structure of this sparsity , which may b e rele- v ant in some problems and whic h pro vides another av en ue for inserting prior kno wledge in to the problem. In particular, considerable in terest has b een attracted b y group sparsity [60], blo c k sparsity [27], or more general struc- tured sparsit y [3], [33], [38]. A classic mo del for group sparsit y is the gr oup LASSO (gLASSO) [60], where the regularizer is the so-called ` 1 , 2 norm [47], [36] or the ` 1 , ∞ norm [47], [37], defined as r gLASSO ( x ) = P s i =1 k x g i k 2 and P s i =1 k x g i k ∞ , resp ectiv ely 1 , where x g i represen ts the subv ector of x indexed b y g i , and g i ⊆ { 1 , ..., n } denotes the index set of the i -th group. Different w ays to define the groups lead to o verlapping or non-o v erlapping gLASSO. Notice that if each group ab o ve is a singleton, then r gLASSO reduces to r LASSO , whereas if s = 1 and g 1 = { 1 , ..., n } , then r gLASSO ( x ) = k x k 2 . Recen tly , the sp arse gLASSO (sgLASSO) regularizer was prop osed as r sgLASSO ( x ) = λ 1 r LASSO ( x ) + λ 2 r gLASSO ( x ), where λ 1 and λ 2 are non-negative parameters [51]. In comparison with gLASSO, sgLASSO not only selects groups, but also individual v ariables within each group. Note that one of the costs of the p ossible adv an tages of gLASSO and sgLASSO o ver standard LASSO is the need to define a priori the structure of the groups. In some problems, the comp onents of x are known to b e similar in v alue to its neigh b ors (assuming that there is some natural neigh b orho od relation defined among the comp onents of x ). T o encourage this type of solution (usually in conjunction with sparsity), sev eral prop osals hav e app eared, such as the elastic net [64], the fused LASSO (fLASSO) [53], gr ouping pursuit (GS) [50], and the o ctagonal shrinkage and clustering algorithm for r e gr ession (OSCAR) [7]. The elastic net regularizer is r elast-net ( x ) = λ 1 k x k 1 + λ 2 k x k 2 2 , encouraging b oth sparsity and grouping [64]. The fLASSO regularizer is giv en by r fLASSO ( x ) = λ 1 k x k 1 + λ 2 P i | x i − x i +1 | , where the total variation (TV) term (sum of the absolute v alues of differences) encourages consecutiv e v ariables to be similar; fLASSO is thus able to promote b oth sparsit y and smo othness. The GS regularizer is defined as r GS ( x ) = P i λ [50]; how ever, r GS is neither sparsit y-promoting nor conv ex. Finally , r OSCAR [7] has the form r OSCAR ( x ) = λ 1 k x k 1 + λ 2 P i t j X i = c +1 | ˜ v i | − t j X i = c +1 w i . Such a gr oup is c al le d coheren t , sinc e it c annot b e split into two gr oups with differ ent values that r esp e ct (i). The proof of Theorem 1 (except the second equality (21), whic h can be deriv ed from (10)) is giv en in [62], where an algorithm w as also proposed to obtain the optimal b . That algorithm equiv alently divides the indeces of | ˜ v | into groups and p erforms a veraging within eac h group (according to (20)), obtaining a vector that we denote as ¯ v ; this op eration of grouping and a veraging is denoted in this pap er as ¯ ¯ v , ¯ ¯ w = GroupAndAv erage ( | ˜ v | , w ) , (22) where ¯ ¯ v = [ ¯ v 1 , . . . , ¯ v 1 | {z } ϑ 1 comp onen ts . . . ¯ v j . . . ¯ v j | {z } ϑ j comp onen ts . . . ¯ v l . . . ¯ v l | {z } ϑ l comp onen ts ] T , (23) 2 OSCAR AND ITS PR OXIMITY OPERA TOR 14 and ¯ ¯ w = [ ¯ w 1 , . . . , ¯ w 1 | {z } ϑ 1 comp onen ts . . . ¯ w j . . . ¯ w j | {z } ϑ j comp onen ts . . . ¯ w l . . . ¯ w l | {z } ϑ l comp onen ts ] T , (24) with the ¯ v j as giv en in (20) and the ¯ w j as giv en in (21). Finally , b is obtained as b = max( ¯ ¯ v − ¯ ¯ w , 0 ) . (25) The follo wing lemma, whic h is a simple corollary of Theorem 1, indicates that condition (12) is satisfied with π = ¯ ¯ w . Lemma 2. V e ctors ¯ ¯ v and ¯ ¯ w satisfy ¯ ¯ v i − ¯ ¯ w i ≥ ¯ ¯ v i +1 − ¯ ¯ w i +1 , for i = 1 , . . . , n − 1 . (26) No w, we are ready to give the following theorem for the GPO: Theorem 2. Consider v ∈ R n and a p ermutation matrix P ( v ) such that the elements of ˜ v = P ( v ) v satisfy | ˜ v i | ≥ | ˜ v i +1 | , for i = 1 , 2 , ..., n − 1 . L et a b e given by (18) , wher e b is given by (25) ; then a sign( v ) = pro x r OSCAR ( v ) . Pr o of. According to Theorem 1, b as giv en b y (25) is the optimal solution of (17), then a sign( v ) is equal pro x r OSCAR ( v ), according to (15) and (17). The previous theorem sho ws that the GPO can b e computed b y the fol- lo wing algorithm (termed OSCAR GPO ( v , λ 1 , λ 2 ) where v is the input vec- tor and λ 1 , λ 2 are the parameters of r OSCAR ( x )), and illustrated in Figure 3. Algorithm OSCAR GPO ( v , λ 1 , λ 2 ) 1. input v ∈ R n , λ 1 , λ 2 ∈ R + 2. compute 3. w = λ 1 + λ 2 n − [1 : 1 : n ] T 4. ˜ v , P ( v ) = sort | v | 5. ( ¯ ¯ v , ¯ ¯ w ) = GroupAndAverage ( | ˜ v | , w ) 6. u = sign( ˜ v ) max( ¯ ¯ v − ¯ ¯ w , 0 ) 2 OSCAR AND ITS PR OXIMITY OPERA TOR 15 7. x ∗ = P ( v ) T u 8. return x ∗ Figure 3: Pro cedure of computing GPO. GPO is the exact pro ximity op erator of the OSCAR regularizer. Belo w, w e prop ose a faster appro ximate proximit y op erator. 2.3. Appr oximate Pr oximity Op er ator (APO) of r OSCAR ( x ) The GPO describ ed in the previous subsection is the exact proximit y op- erator of r OSCAR ( x ). In this subsection, w e propose an appro ximate v ersion of GPO (named APO – appr oximate pr oximity op er ator ), obtained by skipping the function GroupAndAverage (). In the same v ein as the GPO, the APO of r OSCAR ( x ) is illustrated as Figure 5, and the pseudo co de of computing the APO, termed OSCAR APO ( v , λ 1 , λ 2 ), is as follo ws. Algorithm OSCAR APO ( v , λ 1 , λ 2 ) 1. input v ∈ R n , λ 1 , λ 2 ∈ R + 2. compute 3. w = λ 1 + λ 2 n − [1 : 1 : n ] T 4. ˜ v , P ( v ) = sort | v | 5. u = sign( ˜ v ) max( ˜ v − w , 0) 6. x ∗ = P ( v ) T u 7. return x ∗ 2 OSCAR AND ITS PR OXIMITY OPERA TOR 16 Figure 4: Pro cedure of computing APO. APO can also b e view ed as a group-sparsit y-promoting v ariant of soft thresholding, obtained b y removing (22) from the exact computation of the pro ximity op erator of the OSCAR regularizer. With this alteration, (12) is no longer guaran teed to be satisfied, this b eing the reason wh y APO may not yield the same result as the GPO. Ho wev er, w e next sho w that the APO is able to obtain results that are often as go od as those pro duced by the GPO, although it is simpler and faster. 2.4. Comp arisons b etwe en APO and GPO In this section, w e illustrate the difference betw een APO and GPO on simple examples: let z ∈ R 100 con tain random samples uniformly distributed in [ − 5 , 5], and ˜ z = P ( z ) z b e a magnitude-sorted version, i.e. , suc h that | ˜ z i | > | ˜ z i +1 | for i = 1 , · · · , n − 1. In Figure 5, we plot | ˜ z | , w (recall (9)), and | ˜ z | − w , for different v alues of λ 2 ; these plots show that, naturally , condition (12) may not b e satisfied and that its probabilit y of violation increases for larger v alues of λ 2 . T o obtain further insight into the difference b et ween APO and GPO, w e let ˆ z = ˆ P ( z ) z b e a v alue-sorted v ersion, i.e. , such that ˆ z i > ˆ z i +1 for i = 1 , · · · , n − 1 (note that ˆ z is a v alue-sorted v ector, while ˜ z abov e is a magnitude-sorted vector). W e also compare the results of applying APO and GPO to z and ˆ z , for λ 1 = 0 . 1 and λ 2 ∈ { 0 . 03 , 0 . 047 } ; the results are sho wn in Figure 6. W e see that, for a smaller v alue of λ 2 , the result obtained b y APO is more similar to those obtained by GPO, and the fewer zeros are obtained b y shrink age. F rom Figure 6 (b) and (d), we conclude that the output of GPO on ˆ z resp ects its decreasing v alue, and exhibits the grouping 3 SOL VING OSCAR PROBLEMS USING PSAS 17 Figure 5: Relationships among | ˜ z | , w and | ˜ z | − w for different v alues of λ 2 : (a) λ 1 = 0 . 1 and λ 2 = 0 . 03; (b) λ 1 = 0 . 1 and λ 2 = 0 . 047. effect via the a veraging operation on the corresp onding comp onen ts, whic h coincides with the analysis ab o v e. W e next compare APO and GPO in terms of CPU time. Signal z is randomly generated as ab o ve, but no w with length n = 2 k × 100, for k ∈ { 1 , · · · , 12 } . W e set λ 1 = 0 . 1 and λ 2 = 0 . 04 / 2 k , for which w i ∈ [0 . 1 , 4], for all v alues of k . The results obtained by APO and GPO, with input signals z and ˆ z , are sho wn in Figure 7. The results in this figure sho w that, as n increases, APO b ecomes clearly faster than GPO. Figure 7 (b) shows that as n increases, the results obtained b y APO approach those of GPO. 3. Solving OSCAR problems using PSAs W e consider the following general problem min x h ( x ) := f ( x ) + g ( x ) (27) where f , g : R n → R ∪ {−∞ , + ∞} are con vex functions (th us h is a conv ex function), where f is smo oth with a Lipschitz contin uous gradien t of constant L , while g is p ossibly nonsmo oth. OSCAR (see (7)) is a special case of (27) with f ( x ) = 1 2 k y − Ax k 2 , and g ( x ) = r OSCAR ( x ). In this paper, we assume that (27) is solv able, i.e. , the set of minimizers is not emply: arg min x h ( x ) 6 = ∅ . 3 SOL VING OSCAR PROBLEMS USING PSAS 18 Figure 6: Comparisons on the results obtained b y APO and GPO: (a) APO and GPO with z , λ 1 = 0 . 1 and λ 2 = 0 . 03; (b) with ˆ z , λ 1 = 0 . 1 and λ 2 = 0 . 03; (c) with z , λ 1 = 0 . 1 and λ 2 = 0 . 047; (d) with ˆ z , λ 1 = 0 . 1 and λ 2 = 0 . 047. 3 SOL VING OSCAR PROBLEMS USING PSAS 19 Figure 7: Sp eed comparisons of APO and GPO: (a) APO and GPO, with λ 1 = 0 . 1 and λ 2 = 0 . 04 / 2 k , k ∈ 1 , · · · , 12; (b) APO and GPO op erating on ˆ z (v alue-sorted vector), for the same v alues of λ 1 and λ 2 . The notation “ α ( β , γ )” represents “ length of signal (Time of APO, Time of GPO) ”. The horizontal axis corresp onds to the signal length n = 2 k × 100 , k ∈ 1 , · · · , 12 (differen t v alues of α ), while the vertical axis represen ts the APO and GPO of ˆ z with different v alues of α . 3 SOL VING OSCAR PROBLEMS USING PSAS 20 T o solv e (27), w e in vestigate six state-of-the-art PSAs: FIST A [5], TwIST [6], Sp aRSA [57], ADMM [8], SBM [31] and P ADMM [14]. In eac h of these algorithms, we apply APO and GPO. It is worth recalling that GPO can giv e the exact solution, while APO cannot, so that the algorithms with GPO are exact ones, while those with APO are inexact ones. Due to space limita- tion, w e next only detail FIST A, SpaRSA, and P ADMM applied to OSCAR; the detailes of the other algorithms can b e obtained from the corresp onding publications. In our exp erimen ts, w e conclude that SpaRSA is the fastest algorithm and P ADMM yields the b est solutions. 3.1. FIST A FIST A is a fast v ersion of the iterativ e shrink age-thresholding (IST) al- gorithm, based on Nesterov’s acceleration scheme [42], [41]. The FIST A algorithmic framew ork for OSCAR is as follows. Algorithm FIST A 1. Set k = 0, t 1 = 1, u 0 and compute L . 2. repeat 3. v k = u k − A T ( Au k − y ) /L 4. x k = Pro xStep ( v k , λ 1 /L, λ 2 /L ) 5. t k +1 = 1 + p 1 + 4 t 2 k / 2 6. u k +1 = x k + t k − 1 t k +1 ( x k +1 − x k ) 7. k ← k + 1 8. un til some stopping criterion is satisfied. In the algorithm, the function ProxStep is either the GPO or the APO defined ab o v e; this notation will also b e adopted in the algorithms describ ed b elo w. The FIST A with OSCAR APO is termed FIST A-APO, and with OSCAR GPO is termed FIST A-GPO (whic h is equiv alen t to the algorithm prop osed in [62]). 3.2. Sp aRSA SpaRSA [57] is another fast v ariant of IST whic h gets its speed from using the step-length selection metho d of Barzilai and Borw ein [4]. Its application to OSCAR leads to the follo wing algorithm . 3 SOL VING OSCAR PROBLEMS USING PSAS 21 Algorithm Sp aRSA 1. Set k = 1, η > 1, α min , 0 < α min < α max , and x 0 . 2. α 0 = α min 3. v 0 = x 0 − A T ( Ax 0 − y ) /α 0 4. x 1 = Pro xStep ( v 0 , λ 1 /α 0 , λ 2 /α 0 ) 5. Set k = 1 6. repeat 7. s k = x k − x k − 1 8. ˆ α k = ( s k ) T A T As k ( s k ) T s k 9. α k = max { α min , min { ˆ α k , α max }} 10. rep eat 11. v k = x k − A T ( Ax k − y ) /α k 12. x k +1 = Pro xStep ( v k , λ 1 /α k , λ 2 /α k ) 13. α k ← η α k 14. un til x k +1 satisfies an acceptance criterion. 15. k ← k + 1 16. un til some stopping criterion is satisfied. The t ypical acceptance criterion (in line 14) is to guaran tee that the ob jective function decreases; see [57] for details. SpaRSA with OSCAR APO is termed SpaRSA-APO, and with OSCAR GPO is termed SpaRSA-GPO. 3.3. P ADMM P ADMM [14] is a preconditioned v ersion of ADMM, also an efficien t first- order primal-dual algorithm for con vex optimization problems with kno wn saddle-p oin t structure. As for OSCAR using P ADMM, the algorithm is sho wn as the following: Algorithm P ADMM 1. Set k = 0, choose µ , v 0 and d 0 . 2. repeat 3. v k +1 = pro x f ∗ /µ ( v k + Ad k /µ ) 4. x k +1 = Pro xStep x k − A T v k +1 /µ, λ 1 /µ, λ 2 /µ 5. d k +1 = 2 x k +1 − x k 6. k ← k + 1 7. un til some stopping criterion is satisfied. 4 NUMERICAL EXPERIMENTS 22 In P ADMM, f ∗ is the conjugate of f , and pro x f ∗ /µ can b e obtained from Moreau’s iden tity (6)). P ADMM with OSCAR APO is termed P ADMM- APO, and with OSCAR GPO is termed P ADMM-GPO. 3.4. Conver genc e W e no w turn to the conv ergence of ab o v e algorithms with GPO and APO. Since GPO is an exact pro ximity op erator, the conv ergences of the algorithms with GPO are guaranteed b y their own con v ergence results. How ev er, APO is an appro ximate one, thus the con vergence of the algorithms with APO is not mathematically clear, and we lea ve it as an op en problem here, in spite of that we ha ve practically found that APO b eha ves similarly as GPO when the regularization parameter λ 2 is set to a small enough v alue. 4. Numerical Exp erimen ts W e report results of experiments on group-sparse signal reco very aiming at showing the differences among the six aforementioned PSAs, with GPO or APO.. All the exp erimen ts w ere p erformed using MA TLAB on a 64-bit Windo ws 7 PC with an In tel Core i7 3.07 GHz pro cessor and 6.0 GB of RAM. In order to measure the performance of differen t algorithms, w e employ the follo wing four metrics defined on an estimate e of an original vector x : • Elapsed time (termed Time ); • Number of iterations (termed Iterations ); • Mean absolute error ( MAE = k x − e k 1 /n ); • Mean squared error ( MSE = k x − e k 2 2 /n ). The observed v ector y is sim ulated b y y = Ax + n , where n ∼ N (0 , σ 2 I ) and with σ = 0 . 4, and the original signal x is a 1000-dimensional v ector with the follo wing structure: x = [ α 1 , · · · , α 100 | {z } 100 , 0 , · · · , 0 | {z } 200 , β 1 , · · · , β 100 | {z } 100 , 0 , · · · , 0 | {z } 200 , γ 1 , · · · , γ 100 | {z } 100 , 0 , · · · , 0 | {z } 300 ] T (28) 4 NUMERICAL EXPERIMENTS 23 T able 1: RESUL TS OF GROUP-SP ARSE SIGNAL RECOVER Y Time (seconds) Iterations MAE MSE FIST A-APO 0.562 4 0.337 0.423 FIST A-GPO 1.92 4 0.337 0.423 TwIST-APO 0.515 7 0.342 0.423 TwIST-GPO 4.45 7 0.342 0.423 SpaRSA-APO 0.343 6 0.346 0.445 SpaRSA-GPO 2.08 6 0.375 0.512 ADMM-APO 2.23 37 0.702 1.49 ADMM-GPO 16.2 37 0.702 1.49 SBM-APO 2.26 37 0.702 1.49 SBM-GPO 14.9 37 0.702 1.49 P ADMM-APO 0.352 9 0.313 0.411 P ADMM-GPO 2.98 9 0.313 0.411 where α k = 7 + k , β k = 9 + k , γ k = − 8 + k and k ∼ N (0 , 1), the disturbance k in each group can someho w reflect the real applications, and x possesses b oth p ositiv e and negative groups. The sensing matrix A is a 500 × 1000 matrix whose comp onents are sampled from the standard normal distribution. 4.1. R e c overy of Gr oup-Sp arse Signals W e ran the aforementioned tw elve algorithms: FIST A-GPO, FIST A- APO, TwIST-GPO, TwIST-APO, SpaRSA-GPO, SpaRSA- APO, SBM-GPO, SBM-APO, ADMM-GPO, ADMM-APO, P ADMM-GPO and P ADMM-APO. The stopping condition is k x k +1 − x k k / k x k +1 k ≤ tol , where tol = 0 . 01 and x k represen ts the estimate at the k -th iteration. In the OSCAR mo del, we set λ 1 = 0 . 1 and λ 2 = 0 . 001. The original and reco v ered signals are shown in Figure 8, and the results of Time, Iterations, MAE, and MSE are sho wn in T able 1. Figure 9, 10 and 11 sho w the evolution of the ob jectiv e function, MAE, and MSE o ver time, resp ectiv ely . W e can conclude from Figures 9, 10, and 11, and T able 1, that PSAs with APO are muc h faster than that with GPO. Among the PSAs with GPO and APO, SpaRSA-APO is the fastest one in time, while FIST A-APO uses few er iterations. The results obtained b y P ADMM are the most accurate ones. 4 NUMERICAL EXPERIMENTS 24 Figure 8: Recov ered group-sparse signals. 4 NUMERICAL EXPERIMENTS 25 Figure 9: Ob jectiv e function ev olution ov er time. 4 NUMERICAL EXPERIMENTS 26 Figure 10: MAE evolution ov er time. 4 NUMERICAL EXPERIMENTS 27 Figure 11: MSE evolution ov er time. 5 CONCLUSIONS 28 Figure 12: Consumed time of different algorithms o ver signal length. 4.2. Imp act of Signal L ength Finally , w e study the influence of the signal length on the p erformance of the algorithms. F or signal length n , we use a matrix A of size n 2 × n , and k eep other setup of ab ov e subsection unchanged. The results are shown in Figure 12, where the horizontal axis represen ts the signal size. F rom Figure 12, we can conclude that, along with increasing signal size, the sp eed of the PSAs with APO is m uch faster than that with GPO such that the former are more suitable for solving large-scale problems. 5. Conclusions W e ha v e proposed approac hes to efficien tly solve problems inv olving the OSCAR regularizer, whic h outperforms other group-sparsit y-inducing ones. The exact and approximate versions of the pro ximity op erator of the OS- CAR regularizer w ere considered, and their differences w ere analyzed b oth mathematically and numerically . Naturally , the approximate is faster than the exact one, but for certain range of the parameters of the regularizer, the 6 A CKNOWLEDGEMENTS 29 results are very similar. These t wo proximit y op erators pro vide a v ery use- ful building b o c k for the applications of proximal spitting algorithms. W e ha ve considered six state-of-the-art algorithms: FIST A, TwIST, SpaRSA, SBM, ADMM and P ADMM. Exp erimen ts on group-sparse signal reco very ha ve sho wn that these algorithms, working with the appro ximate proximit y op erator, are able to obtain accurate results v ery fast. Ho wev er, their mathe- matical con vergence proof is left as an op en problem, whereas the algorithms op erating with the exact pro ximity op erator inherit the corresp onding con- v ergence results. 6. Ac kno wledgements W e thank James T. Kwok for kindly providing us the C++ co de of their pap er [62]. References [1] M. Afonso, J. Bioucas-Dias, and M. Figueiredo, “F ast image recov ery using v ariable splitting and constrained optimization,” IEEE T r ansac- tions on Image Pr o c essing , v ol. 19, pp. 2345–2356, 2010. [2] ——, “An augmen ted lagrangian approac h to the constrained optimiza- tion form ulation of imaging inv erse problems,” IEEE T r ansactions on Image Pr o c essing , v ol. 20, pp. 681–695, 2011. [3] F. Bach, R. Jenatton, J. Mairal, and G. Ob ozinski, “Structured sparsity through con vex optimization,” Statistic al Scienc e , vol. 27, pp. 450–468, 2012. [4] J. Barzilai and J. Borwein, “Tw o-p oin t step size gradient metho ds,” IMA Journal of Numeric al A nalysis , v ol. 8, pp. 141–148, 1988. [5] A. Beck and M. T eb oulle, “A fast iterativ e shrink age-thresholding algo- rithm for linear inv erse problems,” SIAM Journal on Imaging Scienc es , v ol. 2, pp. 183–202, 2009. [6] J. Bioucas-Dias and M. Figueiredo, “A new twist: t wo-step iterativ e shrink age/thresholding algorithms for image restoration,” IEEE T r ans- actions on Image Pr o c essing , v ol. 16, pp. 2992–3004, 2007. REFERENCES 30 [7] H. Bondell and B. Reich, “Simultaneous regression shrink age, v ariable selection, and supervised clustering of predictors with OSCAR,” Bio- metrics , v ol. 64, pp. 115–123, 2007. [8] S. Boyd, N. P arikh, E. Chu, B. P eleato, and J. Ec kstein, “Distributed op- timization and statistical learning via the alternating direction method of multipliers,” F oundations and T r ends R in Machine L e arning , v ol. 3, pp. 1–122, 2011. [9] J. Cai, S. Osher, and Z. Shen, “Split Bregman methods and frame based image restoration,” Multisc ale Mo deling & Simulation , vol. 8, pp. 337– 369, 2009. [10] E. Cand ` es, “Compressiv e sampling,” in Pr o c e e dings oh the International Congr ess of Mathematicians: Madrid, A ugust 22-30, 2006: invite d le c- tur es , 2006, pp. 1433–1452. [11] E. Candes, J. Romberg, and T. T ao, “Stable signal reco v ery from in- complete and inaccurate measuremen ts,” Communic ations on Pur e and Applie d Mathematics , v ol. 59, pp. 1207–1223, 2006. [12] E. Candes and T. T ao, “Deco ding by linear programming,” IEEE T r ans- actions on Information The ory , v ol. 51, pp. 4203–4215, 2005. [13] E. Candes, M. W akin, and S. Boyd, “Enhancing sparsity by rew eigh ted ` 1 minimization,” Journal of F ourier Analysis and Applic ations , v ol. 14, pp. 877–905, 2008. [14] A. Cham b olle and T. P o c k, “A first-order primal-dual algorithm for con vex problems with applications to imaging,” Journal of Mathematic al Imaging and Vision , vol. 40, pp. 120–145, 2011. [15] R. Chartrand, “Exact reconstructions of sparse signals via noncon v ex minimization,” IEEE Signal Pr o c essing L etters , vol. 14, pp. 707–710, 2007. [16] R. Chartrand and W. Yin, “Iterativ ely rew eigh ted algorithms for com- pressiv e sensing,” in IEEE International Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing (ICASSP) , 2008, pp. 3869–3872. REFERENCES 31 [17] X. Chen and W. Zhou, “Conv ergence of rew eighted l1 minimization algorithms and unique solution of truncated lp minimization,” Pr eprint , 2010. [18] P . Com b ettes and V. W a js, “Signal reco very b y proximal forw ard- bac kward splitting,” Multisc ale Mo deling & Simulation , v ol. 4, pp. 1168– 1200, 2005. [19] R. Couran t, “V ariational metho ds for the solution of problems of equi- librium and vibrations,” Bul l. A mer. Math. So c , v ol. 49, p. 23, 1943. [20] I. Daub echies, M. Defrise, and C. De Mol, “An iterative thresholding algorithm for linear inv erse problems with a sparsity constrain t,” Com- munic ations on pur e and applie d mathematics , v ol. 57, pp. 1413–1457, 2004. [21] Z. Day e and X. Jeng, “Shrink age and mo del selection with correlated v ariables via weigh ted fusion,” Computational Statistics & Data A naly- sis , v ol. 53, pp. 1284–1298, 2009. [22] D. L. Donoho, “Compressed sensing,” IEEE T r ansactions on Informa- tion The ory , v ol. 52, pp. 1289–1306, 2006. [23] D. Donoho, I. Drori, Y. Tsaig, and J. Starck, Sp arse solution of under- determine d line ar e quations by stagewise ortho gonal matching pursuit , 2006. [24] J. Eckstein and D. Bertsek as, “On the Douglas-Rac hford splitting metho d and the pro ximal point algorithm for maximal monotone op- erators,” Mathematic al Pr o gr amming , vol. 5, pp. 293–318, 1992. [25] B. Efron, T. Hastie, I. Johnstone, and R. Tibshirani, “Least angle re- gression,” The A nnals of statistics , v ol. 32, pp. 407–499, 2004. [26] M. Elad, Sp arse and R e dundant R epr esentations: F r om The ory to Ap- plic ations in Signal and Image Pr o c essing . Springer, 2010. [27] Y. Eldar and H. Bolcskei, “Blo c k-sparsity: Coherence and efficien t re- co very ,” in IEEE International Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing (ICASSP) , 2009, pp. 2885–2888. REFERENCES 32 [28] M. Figueiredo and R. No wak, “An EM algorithm for wa v elet-based im- age restoration,” IEEE T r ansactions on Image Pr o c essing , vol. 12, pp. 906–916, 2003. [29] ——, “A b ound optimization approac h to w av elet-based image decon v o- lution,” in IEEE International Confer enc e on Image Pr o c essing , 2005, pp. I I.782–II.785. [30] M. Figueiredo, R. Now ak, and S. W right, “Gradien t pro jection for sparse reconstruction: Application to compressed sensing and other in verse problems,” IEEE Journal of Sele cte d T opics in Signal Pr o c essing , vol. 1, pp. 586–597, 2007. [31] T. Goldstein and S. Osher, “The split Bregman metho d for l1- regularized problems,” SIAM Journal on Imaging Scienc es , v ol. 2, pp. 323–343, 2009. [32] E. Hale, W. Yin, and Y. Zhang, “A fixed-p oin t con tinuation metho d for l1-regularized minimization with applications to compressed sensing,” CAAM TR07-07, Ric e University , 2007. [33] J. Huang, T. Zhang, and D. Metaxas, “Learning with structured spar- sit y ,” The Journal of Machine L e arning R ese ar ch , v ol. 999888, pp. 3371– 3412, 2011. [34] S. Kim, K. Sohn, and E. Xing, “A multiv ariate regression approach to asso ciation analysis of a quan titative trait net work,” Bioinformatics , v ol. 25, pp. i204–i212, 2009. [35] A. Langer and M. F ornasier, “Analysis of the adaptiv e iterativ e bregman algorithm,” pr eprint , vol. 3, 2010. [36] J. Liu and J. Y e, “F ast ov erlapping group lasso,” arXiv pr eprint arXiv:1009.0306 , 2010. [37] J. Mairal, R. Jenatton, G. Ob ozinski, and F. Bach, “Netw ork flo w algo- rithms for structured sparsit y ,” arXiv pr eprint arXiv:1008.5209 , 2010. [38] C. Micc helli, J. Morales, and M. Pon til, “Regularizers for structured sparsit y ,” A dvanc es in Computational Mathematics , pp. 1–35, 2010. REFERENCES 33 [39] J. Moreau, “F onctions con vexes duales et p oin ts proximaux dans un espace hilb ertien,” CR A c ad. Sci. Paris S´ er. A Math , v ol. 255, pp. 2897– 2899, 1962. [40] B. Natara jan, “Sparse appro ximate solutions to linear systems,” SIAM journal on c omputing , vol. 24, pp. 227–234, 1995. [41] Y. Nesterov, “Introductory lectures on conv ex optimization, 2004.” [42] ——, “A metho d of solving a con vex programming problem with con- v ergence rate O (1 /k 2 ),” in Soviet Mathematics Doklady , v ol. 27, 1983, pp. 372–376. [43] M. Osb orne, B. Presnell, and B. T urlac h, “On the lasso and its dual,” Journal of Computational and Gr aphic al statistics , v ol. 9, pp. 319–337, 2000. [44] S. Osher, Y. Mao, B. Dong, and W. Yin, “F ast linearized bregman it- eration for compressiv e sensing and sparse denoising,” , 2011. [45] S. P etry , C. Flexeder, and G. T utz, “Pairwise fused lasso,” T e chnic al R ep ort 102, Dep artment of Statistics LMU Munich , 2010. [46] S. P etry and G. T utz, “The oscar for generalized linear mo dels,” T e ch- nic al R ep ort 112, Dep artment of Statistics LMU Munich , 2011. [47] Z. Qin and D. Goldfarb, “Structured sparsit y via alternating direction metho ds,” The Journal of Machine L e arning R ese ar ch , vol. 98888, pp. 1435–1468, 2012. [48] S. Setzer, “Split Bregman algorithm, Douglas-Rac hford splitting and frame shrink age,” Sc ale sp ac e and variational metho ds in c omputer vi- sion , pp. 464–476, 2009. [49] S. Setzer, G. Steidl, and T. T eub er, “Deblurring p oissonian images by split Bregman techniques,” Journal of Visual Communic ation and Image R epr esentation , v ol. 21, pp. 193–199, 2010. [50] X. Shen and H. Huang, “Grouping pursuit through a regularization solution surface,” Journal of the Americ an Statistic al Asso ciation , v ol. 105, pp. 727–739, 2010. REFERENCES 34 [51] N. Simon, J. F riedman, T. Hastie, and R. Tibshirani, “The sparse-group lasso,” Journal of Computational and Gr aphic al Statistics , 2012, to ap- p ear. [52] R. Tibshirani, “Regression shrink age and selection via the lasso,” Jour- nal of the R oyal Statistic al So ciety (B) , pp. 267–288, 1996. [53] R. Tibshirani, M. Saunders, S. Rosset, J. Zhu, and K. Knight, “Sparsit y and smo othness via the fused lasso,” Journal of the R oyal Statistic al So ciety (B) , v ol. 67, pp. 91–108, 2004. [54] Y. Tsaig, “Sparse solution of underdetermined linear systems: algo- rithms and applications,” Ph.D. dissertation, Stanford Univ ersity , 2007. [55] Y. W ang, J. Y ang, W. Yin, and Y. Zhang, “A new alternating minimiza- tion algorithm for total v ariation image reconstruction,” SIAM Journal on Imaging Scienc es , vol. 1, pp. 248–272, 2008. [56] D. Wipf and S. Nagara jan, “Iterative rew eighted l1 and l2 metho ds for finding sparse solutions,” IEEE Journal of Sele cte d T opics in Signal Pr o c essing , vol. 4, pp. 317–329, 2010. [57] S. W righ t, R. No w ak, and M. Figueiredo, “Sparse reconstruction b y sep- arable appro ximation,” IEEE T r ansactions on Signal Pr o c essing , v ol. 57, pp. 2479–2493, 2009. [58] S. Y ang, L. Y uan, Y.-C. Lai, X. Shen, P . W onk a, and J. Y e, “F eature grouping and selection o ver an undirected graph,” in Pr o c e e dings of the 18th A CM SIGKDD international c onfer enc e on Know le dge disc overy and data mining . ACM, 2012, pp. 922–930. [59] W. Yin, S. Osher, D. Goldfarb, and J. Darbon, “Bregman iterativ e al- gorithms for ` 1 -minimization with applications to compressed sensing,” SIAM Journal on Imaging Scienc es , v ol. 1, pp. 143–168, 2008. [60] M. Y uan and Y. Lin, “Mo del selection and estimation in regression with group ed v ariables,” Journal of the R oyal Statistic al So ciety (B) , vol. 68, pp. 49–67, 2005. [61] H. Zhang, L. Cheng, and J. Li, “Reweigh ted minimization mo del for mr image reconstruction with split Bregman metho d,” Scienc e China Information scienc es , pp. 1–10, 2012. REFERENCES 35 [62] L. Zhong and J. Kwok, “Efficien t sparse mo deling with automatic fea- ture grouping,” IEEE T r ansactions on Neur al Networks and L e arning Systems , v ol. 23, pp. 1436–1447, 2012. [63] H. Zou, “The adaptiv e lasso and its oracle prop erties,” Journal of the A meric an Statistic al Asso ciation , vol. 101, pp. 1418–1429, 2006. [64] H. Zou and T. Hastie, “Regularization and v ariable selection via the elastic net,” Journal of the R oyal Statistic al So ciety (B) , vol. 67, pp. 301–320, 2005.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment