Integrating Document Clustering and Topic Modeling
Document clustering and topic modeling are two closely related tasks which can mutually benefit each other. Topic modeling can project documents into a topic space which facilitates effective document clustering. Cluster labels discovered by document…
Authors: Pengtao Xie, Eric P. Xing
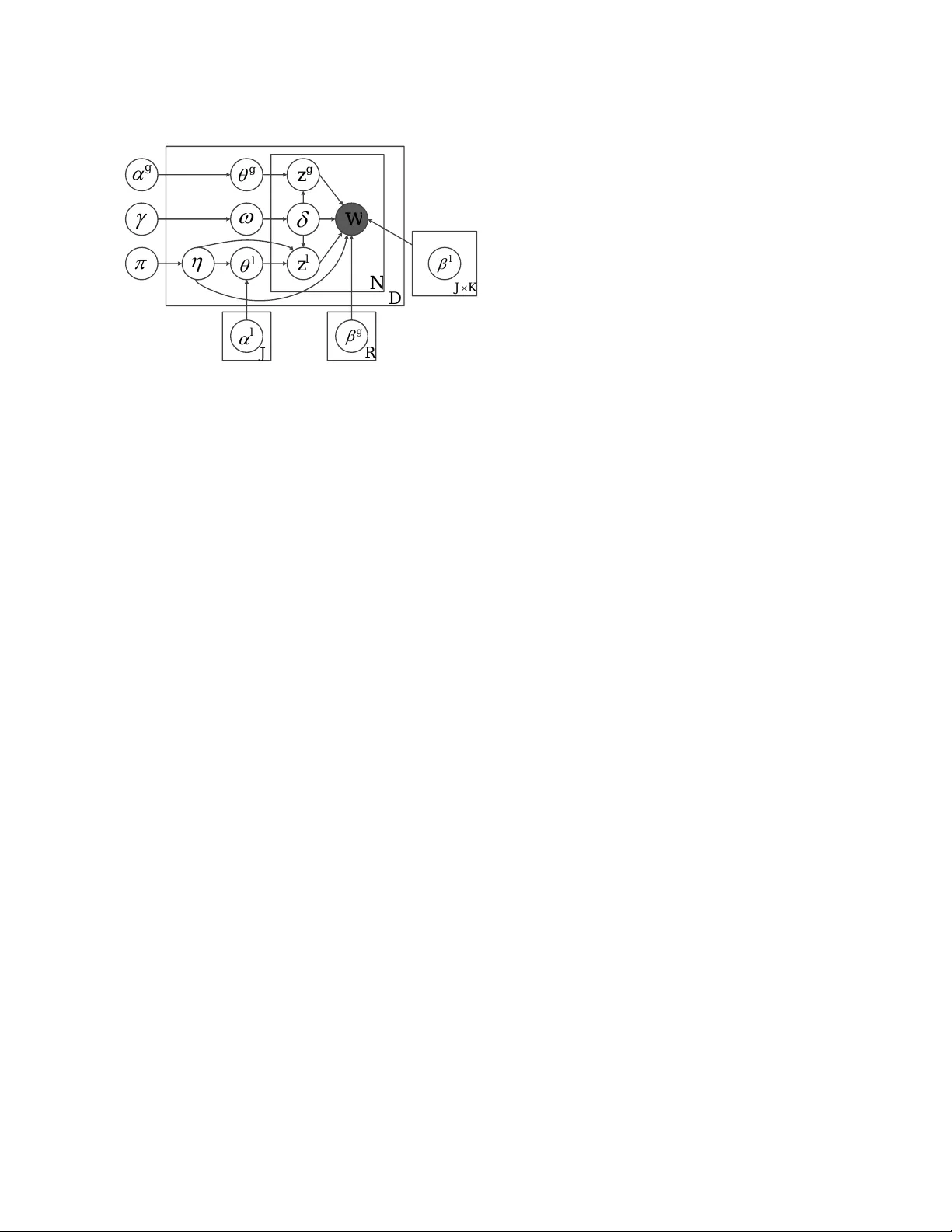
In tegrating Do cumen t Clustering and T opic Mo deling P engtao Xie ∗ State Key Lab oratory on In telligen t T ec hnology and Systems Tsingh ua National Lab for Information Science and T ec hnology Departmen t of Computer Science and T ec hnology Tsingh ua Universit y , Beijing 100084, China Eric P .Xing Mac hine Learning Department Carnegie Mellon Univ ersity Pittsburgh, P A 15213, USA Abstract Do cumen t clustering and topic mo deling are t wo closely related tasks which can mutu- ally b enefit eac h other. T opic mo deling can pro ject do cumen ts into a topic space whic h facilitates effectiv e document cluster- ing. Cluster labels disco v ered b y document clustering can b e incorp orated in to topic mo dels to extract local topics sp ecific to eac h cluster and global topics shared by all clus- ters. In this paper, we propose a multi-grain clustering topic mo del (MGCTM) whic h in te- grates document clustering and topic mo del- ing in to a unified framew ork and jointly p er- forms the tw o tasks to achiev e the ov erall b est p erformance. Our mo del tightly couples tw o comp onen ts: a mixture comp onen t used for disco vering laten t groups in do cument col- lection and a topic model component used for mining m ulti-grain topics including lo cal topics sp ecific to each cluster and global top- ics shared across clusters. W e employ v aria- tional inference to approximate the p osterior of hidden v ariables and learn mo del param- eters. Experiments on t wo datasets demon- strate the effectiv eness of our mo del. 1 INTR ODUCTION In the text domain, do cument clustering (Aggarwal and Zhai, 2012; Cai et al., 2011; Lu et al., 2011; Ng et al., 2002; Xu and Gong, 2004; Xu et al., 2003) and topic mo deling (Blei et al., 2003; Hofmann, 2001) are t wo widely studied problems which ha ve many appli- cations. Do cumen t clustering aims to organize similar do cumen ts into groups, which is crucial for do cumen t organization, bro wsing, summarization, classification ∗ The w ork is done while P engtao Xie was visiting Carnegie Mellon Universit y . and retriev al. T opic mo deling dev elops probabilistic generativ e mo dels to disco v er the latent seman tics em- b edded in do cument collection and has demonstrated v ast success in mo deling and analyzing texts. Do cumen t clustering and topic mo deling are highly correlated and can mutually b enefit eac h other. On one hand, topic mo dels can disco ver the laten t seman- tics embedded in do cumen t corpus and the semantic information can be muc h more useful to identify do c- umen t groups than raw term features. In classic doc- umen t clustering approac hes, do cuments are usually represen ted with a bag-of-words (BOW) mo del which is purely based on raw terms and is insufficien t to cap- ture all semantics. T opic mo dels are able to put words with similar seman tics in to the same group called topic where synon ymous w ords are treated as the same. Un- der topic mo dels, do cumen t corpus is pro jected into a topic space which reduces the noise of similarity mea- sure and the grouping structure of the corpus can b e iden tified more effectively . On the other hand, do cumen t clustering can facilitate topic mo deling. Sp ecifically , do cumen t clustering en- ables us to extract lo cal topics sp ecific to eac h do cu- men t cluster and global topics shared across clusters. In a collection, do cumen ts usually b elong to several groups. F or instance, in scien tific pap er archiv e such as Go ogle Scholar, pap ers are from multiple disciplines, suc h as math, biology , computer science, economics. Eac h group has its o wn set of topics. F or instance, computer science pap ers co ver topics like op erating system, net w ork, mac hine learning while economics pap ers contain topics lik e entrepreneurial economics, financial economics, mathematical economics. Besides group-sp ecific topics, a common set of global topics are shared b y all groups. In pap er arc hive, papers from all groups share topics like reviewing related w ork, rep ort- ing exp erimental results and ackno wledging financial supp orts. Clustering can help us to identify the la- ten t groups in a do cumen t collection and subsequen tly w e can identify lo cal topics sp ecific to each group and global topics shared by all groups b y exploiting the grouping structure of do cuments. These fine-grained topics can facilitate a lot of utilities. F or instance, w e can use the group-sp ecific lo cal topics to summa- rize and browser a group of do cumen ts. Global topics can b e used to remov e background w ords and describ e the general con tents of the whole collection. Standard topic mo dels (Blei et al., 2003; Hofmann, 2001) lack the mec hanism to model the grouping b eha vior among do cumen ts, thereby they can only extract a single set of flat topics where lo cal topics and global topics are mixed and can not b e distinguished. Naiv ely , w e can p erform these tw o tasks separately . T o mak e topic mo deling facilitates clustering, we can first use topic mo dels to pro ject do cuments into a topic space, then p erform clustering algorithms such as K-means in the topic space to obtain clusters. T o mak e clustering promotes topic mo deling, w e can first obtain clusters using standard clustering algorithms, then build topic mo dels to extract cluster-sp ecific lo- cal topics and cluster-indep endent global topics b y in- corp orating cluster labels into mo del design. How ever, this naive strategy ignores the fact that do cumen t clus- tering and topic mo deling are highly correlated and fol- lo w a chic ken-and-egg relationship. Better clustering results pro duce b etter topic mo dels and b etter topic mo dels in turn contribute to b etter clustering results. P erforming them separately fails to mak e them mu- tually promote eac h other to achiev e the o verall b est p erformance. In this pap er, we prop ose a generative mo del which in tegrates do cumen t clustering and topic modeling to- gether. Given a corpus, w e assume there exist several laten t groups and each do cumen t b elongs to one la- ten t group. Each group p ossesses a set of lo cal topics that capture the sp ecific semantics of do cumen ts in this group and a Diric hlet prior expressing preferences o ver lo cal topics. Besides, w e assume there exist a set of global topics shared by all groups to capture the common semantics of the whole collection and a common Diric hlet prior go verning the sampling of pro- p ortion vectors ov er global topics for all do cumen ts. Eac h do cumen t is a mixture of lo cal topics and global topics. W ords in a do cument can b e either generated from a global topic or a lo cal topic of the group to whic h the do cument b elongs. In our mo del, the la- ten t v ariables of cluster membership, do cument-topic distribution and topics are jointly inferred. Cluster- ing and modeling are seamlessly coupled and m utually promoted. The ma jor contribution of this pap er can b e summa- rized as follo ws • W e prop ose a unified mo del to in tegrate do cumen t clustering and topic mo deling together. • W e deriv e v ariational inference for posterior infer- ence and parameter learning. • Through exp erimen ts on t wo datasets, we demon- strate the capability of our mo del in simultane- ously clustering do cumen t and extracting lo cal and global topics. The rest of this pap er is organized as follows. Sec- tion 2 reviews related w ork. In Section 3, we prop ose the MGCTM mo del and presen t a v ariational inference metho d. Section 4 gives exp erimen tal results. Section 5 concludes the pap er and p oints out future research directions. 2 RELA TED WORK 2.1 DOCUMENT CLUSTERING Do cumen t clustering (Aggarwal and Zhai, 2012; Cai et al., 2011; Lu et al., 2011; Ng et al., 2002; Xu and Gong, 2004; Xu et al., 2003) is a widely studied prob- lem with man y applications such as do cument orga- nization, bro wsing, summarization, classification. See (Aggarw al and Zhai, 2012) for a broad ov erview. Pop- ular clustering methods such as K-means and sp ectral clustering (Ng et al., 2002; Shi and Malik, 2000) in general clustering literature are extensively used for do cumen t grouping. Sp ecific to text domain, one popular paradigm of clustering metho ds is based on matrix factoriza- tion, including Latent Seman tic Indexing (LSI) (Deer- w ester et al., 1990), Non-negativ e Matrix F actorization (NMF) (Xu et al., 2003) and Concept F actorization (Cai et al., 2011; Xu and Gong, 2004). The basic idea of factorization based metho ds is to transform do cu- men ts from the original term space to a latent space. The transformation can reduce data dimensionality , reduce the noise of similarity measure and magnify the seman tic effects in the underlying data (Aggarwal and Zhai, 2012), whic h are b eneficial for clustering. Researc hers ha ve applied topic mo dels to cluster docu- men ts. (Lu et al., 2011) inv estigated clustering p erfor- mance of PLSA and LD A. They use LDA and PLSA to mo del the corpus and each topic is treated as a cluster. Do cumen ts are clustered by examining topic prop or- tion vector θ . A do cumen t is assigned to cluster x if x = argmax j θ j . 2.2 TOPIC MODELING T opic mo dels (Blei et al., 2003; Hofmann, 2001) are probabilistic generative models initially created to mo del texts and identify latent semantics underly- ing do cument collection. T opic mo dels p osit do cu- men t collection exhibits multiple latent semantic top- ics where each topic is represented as a multinomial distribution ov er a given vocabulary and each do c- umen t is a mixture of hidden topics. In the vision domain, topic mo dels (F ei-F ei and Perona, 2005; Zhu et al., 2010) are also widely used for image mo deling. Sev eral mo dels ha ve been devised to join tly mo del data and their category lab els or cluster lab els. F ei-F ei (F ei- F ei and Perona, 2005) proposed a Ba yesian hierarchi- cal model to join tly model images and their categories. Eac h category p ossesses a LDA mo del with category- sp ecific Diric hlet prior and topics. In their problem, category lab els are observed. In this pap er, we are in terested in unsup ervised clustering where cluster la- b el is unkno wn. W allach (W allac h, 2008) prop osed a cluster based topic mo del (CTM) which introduces laten t v ariables into LDA to mo del groups and each group owns a group-sp ecific Diric hlet prior go verning the sampling of do cumen t-topic distribution. Eac h do cumen t is asso ciated with a group indicator and its topic proportion vector is generated from the Diric hlet prior sp ecific to that group. (Zhu et al., 2010) pro- p osed a similar mo del used for scene classification in computer vision. They asso ciate each group a logistic- normal prior rather than a Diric hlet prior. Ho wev er, in the tw o mo dels, all groups share a single set of topics. They lack the mechanism to identify lo cal topics sp e- cific to each cluster and global topics shared b y all clus- ters. Another issue is topics inherently b elonging to group A may b e used to generate do cumen ts in group B, which is problematic. F or instance, when mo deling scien tific pap ers, it is unreasonable to use a “computer arc hitecture” topic in computer science group to gener- ate an economics paper. Mo dels prop osed in (W allach, 2008; Zhu et al., 2010) can not prohibit this problem since topics are shared across groups. Ev entually , the inferred topics will b e less coherent and are not dis- criminativ e enough to differentiate clusters. The idea of using fine-grained topics b elonging to sev- eral sets rather than flat topics from a single set to mo del do cumen ts is exploited in (Ahmed and Xing, 2010; Chemudugun ta and Steyvers, 2007; Titov and McDonald, 2008). (Chemudugun ta and Steyvers, 2007) represen ts each do cument as a combination of a background distribution ov er common w ords, a mix- ture distribution o v er general topics and a distribution o ver words that are treated as b eing sp ecific to that do cumen t. (Tito v and McDonald, 2008) prop osed a m ulti-grain topic mo del for online review mo deling. They use lo cal topics to capture ratable asp ects and utilize global topics to capture prop erties of reviewed items. (Ahmed and Xing, 2010) prop osed a multi- view topic mo del for ideological p ersp ectiv e analysis. Eac h ideology has a set of ideology-sp ecific topics and an ideology-sp ecific distribution ov er words. All do c- umen ts share a set of ideology-indep enden t topics. In their problem, the ideology lab el for each document is observ ed. 3 MUL TI-GRAIN CLUSTERING TOPIC MODEL In this section, w e prop ose the multi-grain clustering topic mo del (MGCTM) and deriv e the v ariational in- ference metho d. 3.1 THE MODEL The MGCTM mo del is shown in Figure 1. Given a corpus containing N do cuments d ∈ { 1 , 2 , · · · , N } , we assume these do cumen ts inheren tly belong to J groups j ∈ { 1 , 2 , · · · , J } . Each group j p ossesses K group- sp ecific lo cal topics { β ( l ) j k } K k =1 . Lo cal topics are used to capture the semantics specific to each group. Besides, eac h group j has a group-sp ecific lo cal Dirichlet prior α ( l ) j . Local topic prop ortion vectors of documents in group j are sampled from α ( l ) j . Except local topics for eac h group, we also assume there exist a single set of R global topics { β ( g ) k } R k =1 shared b y all groups. Global topics are used to mo del the univ ersal seman tics of the whole collection. A global Diric hlet prior α ( g ) is used to generate prop ortion vectors ov er global topics and is shared by all documents. A global multinomial prior π is used to c ho ose group membership for a do cumen t. π j denotes the prior probability that a do cument b e- longs to group j . Eac h do cumen t is asso ciated with a group indicator and has a multinomial distribution o ver lo cal top- ics and a m ultinomial distribution ov er global topics. W ords in a do cumen t can b e either generated from lo- cal topics or global topics. W e in tro duce a Bernoulli v ariable for each word to indicate whether this word is sampled from a global topic or a lo cal topic. The Bernoulli distribution for eac h document is sampled from a corpus level Beta prior γ . T o generate a do c- umen t d containing N d w ords w d = { w i } N d i =1 , we first c ho ose a group η d from the multinomial distribution parametrized by π . Then from the lo cal Diric hlet prior α ( l ) η d corresp onding to group η d , w e sample a local topic prop ortion v ector θ ( l ) η d . F rom the global Dirichlet prior α ( g ) , a m ultinomial distribution θ ( g ) d o ver global topics is sampled. F rom Beta distribution parameterized by γ , we sample a Bernoulli distribution ω d from which a binary decision is made at each w ord p osition to make c hoice b et ween lo cal topics and global topics. T o gen- D N l w K J l J R g l g g l z g z w Figure 1: Multi-Grain Clustering T opic Mo del (MGCTM) erate a word w di , we first pick a binary v ariable δ di from the Bernoulli distribution parameterized by ω d . If δ di = 1, we assume w di is generated from a lo cal topic. A local topic z ( l ) η d ,i is pic ked up from the lo- cal topic prop ortion v ector θ ( l ) η d and w di is generated from the topic-word distribution corresp onding to lo- cal topic z ( l ) di and group η d . If δ di = 0, we assume w di is generated from a global topic. In this case, a global topic z ( g ) di is first pick ed up from the global topic prop ortion vector θ ( g ) d and w di is generated from the topic-w ord distribution corresp onding to global topic z ( g ) di . The generativ e pro cess of a document in MGCTM can b e summarized as follows • Sample a group η ∼ M ul ti ( π ) • Sample lo cal topic proportion θ ( l ) η ∼ D ir ( α ( l ) η ) • Sample global topic prop ortion θ ( g ) ∼ D ir ( α ( g ) ) • Sample Bernoulli parameter ω ∼ B eta ( γ ) • F or each word w – Sample a binary indicator δ ∼ B er noull i ( ω ) – If δ = 1 ∗ sample a lo cal topic z ( l ) η ∼ M ulti ( θ ( l ) η ) ∗ sample w ∼ M ul ti ( β z ( l ) η ) – If δ = 0 ∗ sample a global topic z ( g ) ∼ M ulti ( θ ( g ) ) ∗ sample w ∼ M ul ti ( β z ( g ) ) W e claim that p erforming do cumen t clustering and mo deling jointly is superior to doing them separately . MGCTM consists of a mixture mo del comp onen t and a topic mo del comp onen t. Do cumen t clustering is accomplished by estimating ζ and π of the mixture comp onen t. T opic mo deling inv olv es inferring ω , Θ ( l ) , θ ( g ) , δ , Z ( l ) , z ( g ) , γ , A ( l ) , α ( g ) , B ( l ) , B ( g ) of the topic mo del comp onen t. As describ ed in Section 3.2, latent v ariables are inferred by maximizing the log likelihoo d of observed data { w d } D d =1 or its lo wer b ound. Per- forming clustering and mo deling separately is equiv- alen t to inferring laten t v ariables of one comp onen t while fixing those of the other comp onen t. In the case where we first fit do cumen ts using topic mo del and then p erform clustering, we are actually clamp- ing the latent v ariables of topic mo del comp onen t in MGCTM to some predefined v alues and then estimat- ing the mixture mo del comp onent by maximizing the log likelihoo d (or its low er b ound) of observ ations. In the other case where topic mo deling follows cluster- ing, latent v ariables of mixture mo del comp onen t are predefined and we maximize the log likelihoo d (or its lo wer bound) only with resp ect to those of the topic mo del comp onen t. In contrast, p erforming the t wo tasks jointly is equiv alent to maximizing the log like- liho od (or its low er b ound) w.r.t laten t v ariables of t wo comp onents simultaneously . Suppose we aim to maximize a function f ( x ) defined ov er x . x can b e partitioned in to tw o subsets x A and x B . Let f ( x ∗ ) denote the optimal v alue that can b e achiev ed ov er x . Let f ( x ∗ A , x B = c ) denote the optimal v alue obtained b y optimizing x A while fixing x B to some preset v alue c . Let f ( x ∗ B , x A = d ) denote the optimal v alue ob- tained by optimizing x B while fixing x A to some pre- set v alue d . Clearly , the following inequalities hold: f ( x ∗ ) ≥ f ( x ∗ A , x B = c ), f ( x ∗ ) ≥ f ( x ∗ B , x A = d ). F rom this property , we can conclude that jointly p er- forming clustering and mo deling gran ts us b etter re- sults than doing them separately . It would b e interesting to make a comparison of our mo del with Gaussian mixture mo del (GMM) and clus- ter based topic models (CTM) (W allach, 2008; Zhu et al., 2010) in the context of document clustering and mo deling. In GMM, eac h do cumen t is conv erted into a term vector. GMM asso ciates eac h cluster a mul- tiv ariate Gaussian distribution. T o generate a do cu- men t, GMM first samples a cluster, then generate the do cumen t from the Gaussian distribution corresp ond- ing to this cluster. In contrast, our mo del is a mix- ture of LDAs. Each cluster is characterized by a LDA mo del with a set of topics sp ecific to this cluster and a unique Dirichlet prior from which do cumen t-topic distributions are sampled. T o generate a do cumen t, our mo del first samples a cluster, then use the corre- sp onding LD A to generate the do cument. In GMM, do cumen ts are represented with raw terms, whic h are insufficien t to capture underlying seman tics. In our mo del, do cumen ts are mo deled using LDA, whic h is w ell-known for its capability to discov er latent seman- tics. Differen t from CTM (W allac h, 2008; Zhu et al., 2010) where all LDAs share a common set of topics, w e allo cate eac h LD A a set of topics in our mo del. This sp ecific design o wns tw o adv an tages. First, it can explicitly infer group-sp ecific topics for eac h clus- ter. Second, it can av oid the problem of using topics of one group to generate do cuments in another group. 3.2 V ARIA TIONAL INFERENCE AND P ARAMETER LEARNING The key inference problem inv olved in our mo del is to estimate the p osterior distribution p ( η , ω , Θ ( l ) , θ ( g ) , δ , Z ( l ) , z ( g ) | w , Θ ) of laten t v ariables H = { η , ω , Θ ( l ) , θ ( g ) , δ , Z ( l ) , z ( g ) } given observed v ariables w and mo del parameters Π = { π , γ , A ( l ) , α ( g ) , B ( l ) , B ( g ) } . Since extract inference is in tractable, we use v ariational inference (W ain wright and Jordan, 2008) to appro ximate the p osterior. The basic idea is to employ another distribution q ( H | Ω ) whic h is parametrized by Ω and appro ximate the true p osterior by minimizing the Kullback-Leibler (KL) divergence b et ween p ( H | w , Π ) and q ( H | Ω ), whic h is equiv alent to maximizing a lo wer b ound E q [log p ( H , w | Π )] − E q [log q ( H | Ω )] of data lik eliho o d. The maximization is achiev ed via an iterative fixed- p oin t metho d. In E-step, the mo del parameters Π is fixed and w e update the v ariational parameters Ω by maximizing the low er b ound. In M-step, w e fix the v ariational parameters and up date the mo del parameters. This pro cess contin ues until conv ergence. The v ariational distribution q is defined as follows q ( η , ω , Θ ( l ) , θ ( g ) , δ , Z ( l ) , z ( g ) ) = q ( η | ζ ) q ( ω | λ ) J Q j =1 q ( θ ( l ) j | µ ( l ) j ) q ( θ ( g ) | µ ( g ) ) N Q i =1 q ( δ i | τ i ) J Q j =1 q ( z ( l ) i,j | φ ( l ) i,j ) q ( z ( g ) i | φ ( g ) i ) (1) where ζ , { φ ( l ) i,j } i = N ,j = J i =1 ,j =1 and { φ ( g ) i } N i =1 are multinomial parameters, λ is Beta parameter, µ ( l ) and µ ( g ) are Diric hlet parameters, { τ i } N i =1 are Bernoulli parame- ters. In E-step, we compute the v ariational parameters while k eeping mo del parameters fixed ζ j ∝ π j exp { log Γ( K P i =1 α ( l ) j i ) − K P i =1 log Γ( α ( l ) j i ) + K P k =1 ( α ( l ) j k − 1)(Ψ( µ ( l ) j k ) − Ψ( K P i =1 µ ( l ) j i )) + N P i =1 τ i { K P k =1 φ ( l ) i,j,k (Ψ( µ ( l ) j k ) − Ψ( K P n =1 µ ( l ) j,n )) + K P k =1 V P v =1 φ ( l ) i,j,k w iv log β ( l ) j,k,v }} (2) λ 1 = γ 1 + N P i =1 τ i , λ 2 = γ 2 + N P i =1 (1 − τ i ) (3) µ ( l ) j k = ζ j α ( l ) j k + N P i =1 τ i ζ j φ ( l ) i,j,k + 1 − ζ j (4) µ ( g ) k = α ( g ) k + N X i =1 (1 − τ i ) φ ( g ) ik (5) τ i = { 1 + exp {− Ψ( γ 1 ) + Ψ( γ 2 ) − J P j =1 K P k =1 ζ j φ ( l ) i,j,k (Ψ( µ ( l ) j k ) − Ψ( K P n =1 µ ( l ) j n )) − J P j =1 K P k =1 V P v =1 ζ j φ ( l ) i,j,k w iv log β ( l ) j,k,v + K P k =1 φ ( g ) ik (Ψ( µ ( g ) k ) − Ψ( K P j =1 µ ( g ) j )) + K P k =1 V P v =1 φ ( g ) ik w iv log β ( g ) k,v }} − 1 (6) φ ( l ) i,j,k ∝ exp { τ i ζ j (Ψ( µ ( l ) j k ) − Ψ( K P n =1 µ ( l ) j,n ) + V P v =1 w iv log β ( l ) j,k,v ) } (7) φ ( g ) ik ∝ exp { (1 − τ i )(Ψ( µ ( g ) k ) − Ψ( K P j =1 µ ( g ) j ) + V P v =1 w iv log β ( g ) k,v ) } (8) In M-step, we optimize the mo del parameters by max- imizing the lo wer b ound π j = D P d =1 ζ d j D (9) β ( l ) j,k,v ∼ D X d =1 N d X i =1 ζ j τ di φ ( l ) d,i,j,k w d,i,v (10) β ( g ) k,v ∼ D X d =1 N d X i =1 (1 − τ di ) φ ( g ) d,i,k w d,i,v (11) W e optimize Dirichlet priors A ( l ) , α ( g ) and Beta pri- ors γ using the Newton-Raphson metho d describ ed in (Blei et al., 2003). 4 EXPERIMENTS W e ev aluate the do cumen t clustering p erformance of our mo del and corrob orate its abilit y to mine group- sp ecific lo cal topics and group-independent global top- ics on t wo datasets. 4.1 DOCUMENT CLUSTERING W e ev aluate the do cumen t clustering p erformance of our metho d in this section. 4.1.1 Datasets The exp erimen ts are conducted on Reuters-21578 and 20-Newsgroups datasets. These tw o datasets are the most widely used b enc hmark in document cluster- ing. F or Reuters-21578, w e only retain the largest 10 categories and discard do cumen ts with more than one lab els, which left us with 7,285 do cumen ts. 20- Newsgroups dataset contains 18,370 do cumen ts from 20 groups. In all corpus, the stop words are remov ed and eac h do cumen t is represented as a tf-idf vector. 4.1.2 Exp erimen tal Settings F ollowing (Cai et al., 2011), w e use t wo metrics to mea- sure the clustering p erformance: accuracy (AC) and normalized m utual information (NMI). Please refer to (Cai et al., 2011) for definitions of these tw o metrics. W e compare our metho d with the following baseline metho ds: K-means (KM) and Normalized Cut (NC) whic h are probably the most widely used clustering al- gorithms; Non-negative Matrix F actorization (NMF), Laten t Semantic Indexing (LSI), Lo cally Consistent Concept F actorization (LCCF) whic h are factorization based approac hes showing great effectiveness for clus- tering do cumen ts. T o study how topic mo deling can affects do cumen t clustering, we compare with three topic mo del based metho ds. The first one is a naive approac h whic h first uses LD A to learn a topic propor- tion v ector for eac h do cumen t, then p erforms K-means on topic prop ortion vectors to obtain clusters. W e use LD A+Kmeans to denote this approach. The second one is prop osed in (Lu et al., 2011), which treats each topic as a cluster. Do cumen t-topic distribution θ can b e deemed as a mixture prop ortion v ector ov er clus- ters and can b e utilized for clustering. A do cument is assigned to cluster x if x = argmax j θ j . Note that this approac h is a naive solution for in tegrating do cumen t clustering and modeling together. W e use LD A+Naive to denote this approach. The third one is cluster based topic mo del (CTM) (W allach, 2008) which integrates do cumen t clustering and mo deling as a whole. In our exp erimen ts, the input cluster num b er required b y clustering algorithms is set to the ground truth n umber of categories in corpus. Hyp erparameters are tuned to achiev e the b est clustering p erformance. In NC, we use Gaussian kernel as similarity measure b e- t ween do cumen ts. The bandwidth parameter is set to 10. In LSI, we retain top 300 eigenv ectors to form the new subspace. The parameters of LCCF are set as those suggested in (Cai et al., 2011). In LD A+Kmeans and LDA+Naiv e, we use symm etric Dirichlet prior α and β to draw do cumen t-topic distribution and topic- w ord distribution. α and β are set to 0.1 and 0.01 resp ectiv ely . In LDA+Kmeans, the num b er of topics T able 1: Clustering Accuracy (%) Reuters-21578 20-Newsgroups KM 35.02 33.65 NC 26.22 22.03 NMF 49.58 31.85 LSI 42.00 32.33 LCCF 33.07 11.71 LD A+Kmeans 29.73 37.19 LD A+Naive 54.88 55.38 CTM 56.58 45.63 MGCTM 56.01 58.69 T able 2: Normalized Mutual Information (%) Reuters-21578 20-Newsgroups KM 35.76 31.54 NC 27.40 20.31 NMF 35.89 27.82 LSI 37.14 29.78 LCCF 30.45 11.40 LD A+Kmeans 36.00 38.15 LD A+Naive 48.00 57.21 CTM 46.52 51.63 MGCTM 50.10 61.59 is set to 60. In CTM, we set the num b er of topics to 60 for Reuters-21578 and 120 for 20-Newsgroups. F or MGCTM, w e set 5 lo cal topics for each cluster and 10 global topics in Reuters-21578 dataset and 10 lo cal topics for each cluster and 20 global topics for 20-Newsgroups dataset. In MGCTM, we initialize ζ with clustering results obtained from LDA+Naiv e. The other parameters are initialized randomly . 4.1.3 Results T able 1 and T able 2 summarize the accuracy and normalized m utual information of different cluster- ing metho ds, resp ectiv ely . It can b e seen that topic mo deling based clustering metho ds including LD A+Kmeans, LDA+Naiv e, CTM and MGCTM are generally b etter than K-means, normalized cut and factorization based metho ds. This corrob orates our as- sumption that topic mo deling can promote do cumen t clustering. The seman tics discov ered by topic mo dels can effectively facilitate accurate similarity measure, whic h is helpful to obtain coherent clusters. Compared with LD A+Kmeans whic h performing clus- tering and mo deling separately , three metho ds includ- ing LDA+Naiv e, CTM and MGCTM which jointly p erforming tw o tasks achiev e muc h b etter results. This corrob orates our assumption that clustering and mo d- eling can mutually promote each other and couple them into a unified framework pro duces sup erior p er- formance than separating them in to tw o pro cedures. Among LDA+Naiv e, CTM and MGCTM which unify clustering and mo deling, our approach is generally b et- ter than or comparable with the other tw o. This is b e- cause MGCTM p ossesses more sophistication in terms of mo del design, whic h in turn contributes to b etter clustering results. LDA+Naiv e assigns eac h cluster only one topic, whic h ma y not be sufficient to cap- ture the div erse seman tics within each cluster. CTM fails to differen tiate cluster-sp ecific topics and cluster- indep enden t topics, thereby , the learned topics are not discriminativ e in distinguishing clusters. Since topics are shared by all clusters, CTM may try to use a topic inheren tly belonging to cluster A to model a do cument in cluster B, which is unreasonable and can cause se- man tic confusion. Our mo del assigns eac h cluster a set of topics and can av oid to use topics from one cluster to mo del do cumen ts in another cluster, which is more suitable to pro duce coherent clusters. 4.2 TOPIC MODELING In this section, we study the topic mo deling capability of our mo del. W e compare with tw o metho ds. The first one is a naive approach which first uses K-means to obtain document clusters, then clamps the v alues of do cumen t membership v ariables ζ in MGCTM to the obtained clusters labels and learns the latent v ariables corresp onding to topic m odel comp onent. W e use Kmeans+MGCTM to denote this approac h. Again, the purp ose of comparing with this naiv e approach is to in vestigate whether integrating clustering and mo d- eling together is sup erior to doing them separately . The other approach is CTM (W allach, 2008). W e use three mo dels to fit the 20-Newsgroups dataset. The reason to choose 20-Newsgroups rather than Reuters- 21578 for topic mo deling ev aluation is that the cat- egories in 20-Newsgroups are more seman tically clear than those in Reuters-21578. In CTM, we set the topic n umber to 120. In MGCTM and Kmeans+MGCTM, w e set 5 lo cal topics for each of the 20 groups and set 20 global topics. W e ev aluate the inferred topics b oth qualitativ ely and quantitativ ely . Sp ecifically , w e are in terested in tw o things. First, how coherent a topic (either lo cal topic or global topic) is. Second, ho w is a lo cal topic related to a cluster. 4.2.1 Qualitativ e Ev aluation T able 3 shows three global topics inferred from 20- Newsgroups b y MGCTM. Each topic is represen ted b y the ten most probable words for that topic. It can T able 3: Three Global T opics Inferred from 20- Newsgroups b y MGCTM T opic 9 T opic 10 T opic 19 section time in tro duction set y ear information situations p erio d arc hive v olume full address sets lo cal articles field future press situation note time select meet b ody hand case text designed setting list b e seen that these global topics capture the common seman tics in the whole corpus and is not sp ecifically asso ciated with a certain news group. Global topic 9 is ab out news archiv e organization. T opic 10 is ab out time. T opic 19 is ab out article writing. These topics can b e used to generate do cumen ts in all groups. T able 4 sho ws lo cal topics for 4 obtained clusters 1 . As can be seen, local topics effectiv ely capture the specific seman tics of each cluster. F or instance, in Cluster 1, all the four lo cal topics are highly related with com- puter, including serv er, program, Windows, display . In Cluster 2, all topics are ab out middle east p olitics, including race, war, religion, diplomacy . In Cluster 3, all topics are ab out space technology , including space, planets, spacecraft, NASA. In Cluster 4, all topics are closely related with health, including disease, patien ts, do ctors, fo od. These lo cal topics enable us to under- stand each cluster easily and clearly , without the bur- den of browsing a num b er of do cuments in a cluster. In our mo del, do cumen ts in a cluster can only b e gen- erated from lo cal topics of that cluster and we prohibit to use lo cal topics of cluster A to generate do cuments in cluster B. Thereby , each lo cal topic is highly re- lated with its own cluster and has almost no correla- tion with other clusters. In other words, the leaned lo- cal topics are very discriminative to differentiate clus- ters. On the contrary , topics in CTM are shared by all groups. Consequen tly , the seman tic meaning of a topic is v ery ambiguous and the topic can b e related with multiple clusters sim ultaneously . These topics are sub optimal to summarize clusters b ecause of their v agueness. In Kmeans+MGCTM, the clusters are pre- defined using K-means, whose clustering p erformance is m uch worse than MGCTM as rep orted in Section 4.1.3. As a result, the quality of learned topics by Kmeans+MGCTM is also w orse than MGCTM. Their 1 Due to space limit, we only show four lo cal topics for eac h cluster. T able 4: Lobal T opics of 4 Clusters Inferred from 20-Newsgroups by MGCTM Cluster 1 Cluster 2 T opic 1 T opic 2 T opic 3 T opic 4 T opic 1 T opic 2 T opic 3 T opic 4 sun window serv er motif muslims armenian turkish armenian file manager lib file serbs azerbaijan turkey armenians op en windo ws displa y file v ersion bosnian p eople univ ersity turkish xview even t xfree mit bosnia armenia history armenia ec ho motif xterm color henrik armenians ku wait p eople usr application running fon t war turkish jews geno cide xterm program mit serv er armenians azeri p eople turks displa y widget usr sun m uslim so viet professor soviet ftp win windo w fon ts turkey dead go v ernment w ar run screen clients tar world russian turks russian Cluster 3 Cluster 4 T opic 1 T opic 2 T opic 3 T opic 4 T opic 1 T opic 2 T opic 3 T opic 4 space space nasa space candida people vitamin msg nasa launc h gov nasa yeast pitt cancer fo od hst cost space apr weigh t c hronic medical people larson sh uttle energy alask a patien ts evidence information time mission dc apr earth doctor b ody disease fo ods orbit station earth satellite lyme time treatment c hinese theory n uclear ca gov disease disease patien ts eat univ erse p o wer jpl p eople kidney medicine retinol go od ligh t program higgins high go od y ears goo d pain mass system gary sh uttle p eople water pms effects quan titative comparison is rep orted in Section 4.2.2. 4.2.2 Quan titative Ev aluation Ho w to quantitativ ely ev aluate topic mo dels is a op en problem (Boyd-Graber et al., 2009). Some researchers resort to p erplexit y or held-out lik eliho od. Such mea- sures are useful for ev aluating the predictive mo del (Bo yd-Grab er et al., 2009). How ev er, they are not capable to ev aluate how coherent and meaningful the inferred topics are. Through large-scale user studies, (Bo yd-Grab er et al., 2009) shows that topic mo dels whic h p erform b etter on held-out likelihoo d may infer less semantically meaningful topics. Thereb y , we do not use p erplexit y or held-out likelihoo d as ev aluation metric. T o ev aluate how coherent a topic is, we pick up top 20 candidate words for each topic and ask 5 student v olunteers to lab el them. First, the volun teers need to judge whether a topic is interpretable or not. If not, the 20 candidate words in this topic are automat- ically lab eled as “irrelev ant”. Otherwise, volun teers are asked to identify words that are relev ant to this topic. Coherence measure (CM) is defined as the ra- tio b et ween the num b er of relev an t words and total n umber of candidate words. T able 5 summarizes the coherence measure collected from 5 students. As can b e seen, the av erage coher- ence of topics inferred by our mo del surpasses those learned from Kmeans+MGCTM and CTM. In our T able 5: Coherence Measure (CM) (%) of Learned T opics Kmeans+MGCTM CTM MGCTM annotator 1 30.17 28.88 36.08 annotator 2 36.50 43.54 45.79 annotator 3 29.38 35.42 30.83 annotator 4 18.33 25.96 29.46 annotator 5 24.75 24.54 25.17 a verage 27.83 31.60 33.47 mo del, background words in the corpus are organized in to global topics and words sp ecific to clusters are mapp ed into lo cal topics. Kmeans+MGCTM learns lo cal topics based on the cluster lab els obtained by K- means. Due to the sub optimal clustering p erformance of K-means, some documents similar in semantics are put in to different clusters while some dissimilar do cu- men ts are put in to the same cluster. Consequen tly , the learned lo cal topics are less reasonable since they are resulted from po or cluster lab els. CTM lac k the mec h- anism to differentiate corpus-level background words and cluster-sp ecific words and these tw o types of words are mixed in many topics, making topics hard to in- terpret and less coheren t. T o measure the relev ance b et ween lo cal topics and clusters in our metho d, from the 5 learned lo cal top- ics for eac h cluster, w e ask the 5 students to pick up the relev ant ones. The relev ance measure (RM) is de- fined as the ratio b et ween num b er of relev an t topics T able 6: Relev ance Measure (RM) (%) b et ween T opics and Clusters Kmeans+MGCTM CTM MGCTM annotator 1 64 66 72 annotator 2 47 61 57 annotator 3 51 54 63 annotator 4 76 74 81 annotator 5 45 51 58 a verage 56.6 61.2 66.2 and total num b er of topics to b e lab eled. In CTM, w e choose 5 most related topics for each cluster us- ing the metho d describ ed in (W allach, 2008) and ask annotators to lab el. T able 6 presents the relev ance measure b etw een lo cal topics and clusters. The relev ance mea- sure in our metho d is significantly b etter than Kmeans+MGCTM and CTM. The sub optimal perfor- mance of Kmeans+MGCTM still results from the po or clustering p erformance of K-means. The comparison of Kmeans+MGCTM and MGCTM in T able 5 and T able 6 demonstrates that jointly p erforming cluster- ing and mo deling can produce better local and global topics than p erforming them separately . In CTM, top- ics are shared across groups. A certain topic T can b e used to mo del do cumen ts b elonging to several groups. Consequen tly T will b e a comp osition of words from m ultiple groups, making it hard to asso ciate T to a certain group clearly . On the contrary , our mo del al- lo cates eac h cluster a set of cluster-sp ecific topics and prohibit to use lo cal topics from one cluster to mo del do cumen ts in another cluster. Thereby the relev ance b et w een learned local topics and their clusters can be impro ved greatly . 5 CONCLUSIONS AND FUTURE W ORK W e prop ose a m ulti-grain clustering topic mo del to si- m ultaneously p erform document clustering and mo del- ing. Exp erimen ts on t wo datasets demonstrate the fact that these tw o tasks are closely related and can mutu- ally promote each other. In exp erimen ts on do cumen t clustering, we sho w that through topic mo deling, clus- tering p erformance can b e improv ed. In exp erimen ts on topic modeling, we demonstrate that clustering can help infer more coherent topics and can differentiate topics into group-sp ecific ones and group-indep endent ones. In future, we will extend our model to semi-sup ervised clustering settings. In reality , we ma y hav e incomplete external knowledge whic h rev eals that some do cumen t pairs are likely to b e put in to the same cluster. Ho w to incorp orate these semi-sup ervised information in to our mo del would b e an interesting question. Ac knowledgemen ts W e would like to thank the anonymous reviewers for their v aluable comments and thank Chong W ang, Bin Zhao, Gunhee Kim for their helpful suggestions. References Charu C Aggarwal and ChengXiang Zhai. A survey of text clustering algorithms. Mining T ext Data , pages 77–128, 2012. Amr Ahmed and Eric P Xing. Sta ying informed: sup ervised and semi-sup ervised multi-view topical analysis of ideological p ersp ectiv e. In Pr o c e e dings of the 2010 Confer enc e on Empiric al Metho ds in Nat- ur al L anguage Pr o c essing , pages 1140–1150. As soci- ation for Computational Linguistics, 2010. Da vid M Blei, Andrew Y Ng, and Mic hael I Jordan. Laten t dirichlet allo cation. the Journal of Machine L e arning R ese ar ch , 3:993–1022, 2003. Jonathan Boyd-Graber, Jordan Chang, Sean Gerrish, Chong W ang, and David Blei. Reading tea leav es: ho w h umans interpret topic mo dels. In Pr o c e e dings of the 23r d Annual Confer enc e on Neur al Informa- tion Pr o c essing Systems , 2009. Deng Cai, Xiaofei He, and Jiaw ei Han. Lo cally consis- ten t concept factorization for do cument clustering. Know le dge and Data Engine ering, IEEE T r ansac- tions on , 23(6):902–913, 2011. Chaitan ya Chemudugun ta and Padhraic Smyth Mark Steyv ers. Mo deling general and sp ecific asp ects of do cumen ts with a probabilistic topic mo del. In A d- vanc es in Neur al Information Pr o c essing Systems 19: Pr o c e e dings of the 2006 Confer enc e , volume 19, page 241. MIT Press, 2007. Scott Deerwester, Susan T. Dumais, George W F ur- nas, Thomas K Landauer, and Ric hard Harshman. Indexing by latent seman tic analysis. Journal of the Americ an so ciety for Information Scienc e , 41(6): 391–407, 1990. Li F ei-F ei and Pietro Perona. A ba yesian hierarc hical mo del for learning natural scene categories. In Com- puter Vision and Pattern R e c o gnition, 2005. CVPR 2005. IEEE Computer So ciety Confer enc e on , vol- ume 2, pages 524–531. IEEE, 2005. Thomas Hofmann. Unsup ervised learning by proba- bilistic latent semantic analysis. Machine L e arning , 42(1):177–196, 2001. Y ue Lu, Qiaozhu Mei, and ChengXiang Zhai. Inv esti- gating task p erformance of probabilistic topic mo d- els: an empirical study of plsa and lda. Information R etrieval , 14(2):178–203, 2011. Andrew Y Ng, Mic hael I Jordan, Y air W eiss, et al. On sp ectral clustering: analysis and an algorithm. A d- vanc es in Neur al Information Pr o c essing Systems , 2: 849–856, 2002. Jian b o Shi and Jitendra Malik. Normalized cuts and image segmentation. Pattern Analysis and Machine Intel ligenc e, IEEE T r ansactions on , 22(8):888–905, 2000. Iv an Titov and Ryan McDonald. Mo deling online re- views with m ulti-grain topic mo dels. In Pr o c e e dings of the 17th international c onfer enc e on World Wide Web , pages 111–120. A CM, 2008. Martin J W ainwrigh t and Michael I Jordan. Graphical mo dels, exponential families, and v ariational infer- ence. F oundations and T r ends R in Machine L e arn- ing , 1(1-2):1–305, 2008. Hanna M W allach. Structured topic mo dels for lan- guage. Unpublishe d do ctor al dissertation, Univ. of Cambridge , 2008. W ei Xu and Yihong Gong. Do cumen t clustering by concept factorization. In Pr o c e e dings of the 27th an- nual international ACM SIGIR c onfer enc e on R e- se ar ch and Development in Information R etrieval , pages 202–209. A CM, 2004. W ei Xu, Xin Liu, and Yihong Gong. Document clustering based on non-negative matrix factoriza- tion. In Pr o c e e dings of the 26th annual international A CM SIGIR c onfer enc e on R ese ar ch and Develop- ment in Informaion R etrieval , pages 267–273. A CM, 2003. Jun Zh u, Li-Jia Li, Li F ei-F ei, and Eric P Xing. Large margin learning of upstream scene understanding mo dels. A dvanc es in Neur al Information Pr o c ess- ing Systems , 24, 2010.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment