Modeling Documents with Deep Boltzmann Machines
We introduce a Deep Boltzmann Machine model suitable for modeling and extracting latent semantic representations from a large unstructured collection of documents. We overcome the apparent difficulty of training a DBM with judicious parameter tying. …
Authors: Nitish Srivastava, Ruslan R Salakhutdinov, Geoffrey E. Hinton
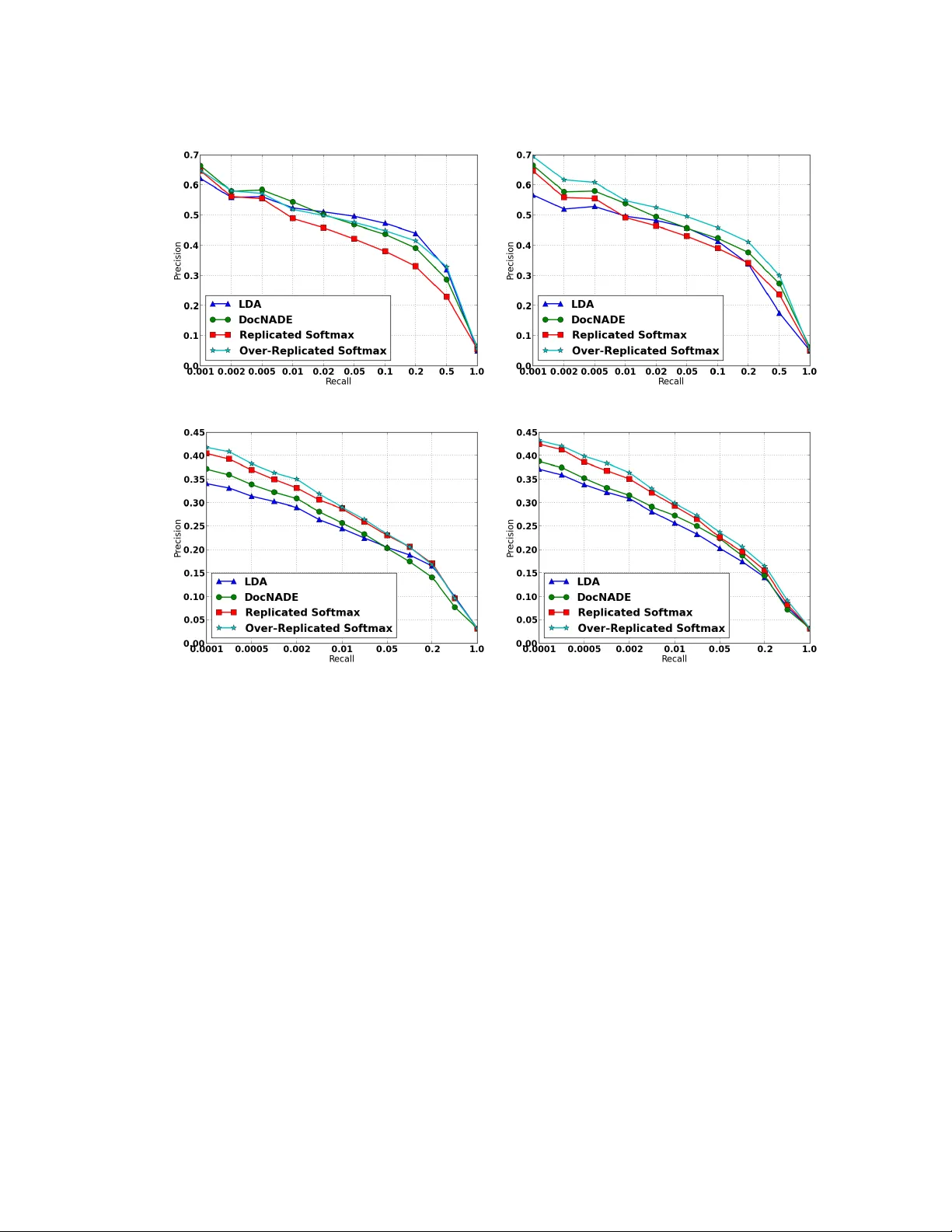
Mo deling Do cumen ts with a Deep Boltzmann Mac hine Nitish Sriv asta v a Ruslan Salakh utdinov { nitish, rsalakh u, hinton } @cs.toron to.edu Departmen t of Computer Science, Universit y of T oron to T oron to, Ontario, M5S 3G4 Canada. Geoffrey Hin ton Abstract W e introduce a t ype of Deep Boltzmann Ma- c hine (DBM) that is suitable for extracting distributed seman tic representations from a large unstructured collection of do cumen ts. W e o vercome the apparent difficult y of train- ing a DBM with judicious parameter tying. This enables an efficien t pretraining algo- rithm and a state initialization sc heme for fast inference. The mo del can b e trained just as efficiently as a standard Restricted Boltzmann Mac hine. Our experiments sho w that the mo del assigns b etter log probability to unseen data than the Replicated Softmax mo del. F eatures extracted from our mo del outp erform LDA, Replicated Softmax, and Do cNADE mo dels on do cumen t retriev al and do cumen t classification tasks. 1 In tro duction T ext do cumen ts are a ubiquitous source of informa- tion. Represen ting the information con tent of a do cu- men t in a form that is suitable for solving real-w orld problems is an important task. The aim of topic mo deling is to create suc h representations b y discov er- ing latent topic structure in collections of do cumen ts. These representations are useful for do cument classi- fication and retriev al tasks, making topic mo deling an imp ortan t mac hine learning problem. The most common approach to topic mo deling is to build a generative probabilistic mo del of the bag of w ords in a do cumen t. Directed graphical mo dels, suc h as Laten t Dirichlet Allo cation (LD A), CTM, H- LD A, ha ve b een extensiv ely used for this [3, 2, 8]. Non-parametric extensions of these mo dels hav e also b een quite successful [13, 1, 5]. Ev en though exact inference in these mo dels is hard, efficien t inference sc hemes, including sto c hastic v ariational inference, on- line inference, and collapsed Gibbs hav e b een devel- op ed that mak e it feasible to train and use these meth- o ds [14, 16, 4]. Another approach is to use undi- rected graphical mo dels such as the Replicated Soft- max mo del [12]. In this mo del, inferring laten t topic represen tations is exact and efficien t. How ever, train- ing is still hard and often requires careful h yp erparam- eter selection. These mo dels typically perform better than LDA in terms of b oth the log probability they assign to unseen data and their do cumen t retriev al and do cumen t classification accuracy . Recently , neural net work based approac hes, such as Neural Autoregres- siv e Density Estimators (Do cNADE) [7], hav e b een to sho wn to outp erform the Replicated Softmax mo del. The Replicated Softmax mo del is a family of Re- stricted Boltzmann Mac hines (RBMs) with shared pa- rameters. An imp ortan t feature of RBMs is that they solv e the “explaining-w ay” problem of directed graph- ical models by ha ving a complemen tary prior ov er hid- den units. Ho wev er, this implicit prior ma y not b e the b est prior to use and having some degree of flexibility in defining the prior ma y be adv antageous. One w ay of adding this additional degree of flexibility , while still a voiding the explaining-a wa y problem, is to learn a t wo hidden lay er Deep Boltzmann Machine (DBM). This mo del adds another la yer of hidden units on top of the first hidden lay er with bi-partite, undirected connec- tions. The new connections come with a new set of w eights. How ever, this additional implicit prior comes at the cost of more exp ensiv e training and inference. Therefore, w e hav e the following tw o extremes: On one hand, RBMs can b e efficien tly trained (e.g. us- ing Contrastiv e Divergence), inferring the state of the hidden units is exact, but the model defines a rigid, implicit prior. On the other hand, a t wo hidden lay er DBM defines a more flexible prior o ver the hidden rep- resen tations, but training and p erforming inference in a DBM mo del is considerably harder. In this pap er, we try to find middle ground b etw een these extremes and build a mo del that combines the b est of b oth. W e in tro duce a t w o hidden lay er DBM mo del, which w e call the Over-Replicated Softmax mo del. This model is easy to train, has fast approxi- mate inference and still retains some degree of flexibil- it y to wards manipulating the prior. Our experiments sho w that this flexibilit y is enough to impro v e signifi- can tly on the p erformance of the standard Replicated Softmax mo del, b oth as generative mo dels and as fea- ture extractors ev en though the new mo del only has one more parameter than the RBM model. The mo del also outperforms LD A and Do cNADE in terms of clas- sification and retriev al tasks. Before w e describ e our mo del, we briefly review the Replicated Softmax mo del [12] whic h is a stepping stone to w ards the prop osed Ov er-Replicated Softmax mo del. 2 Replicated Softmax Mo del This mo del comprises of a family of Restricted Boltz- mann Machines. Eac h RBM has “softmax” visible v ariables that can hav e one of a n umber of different states. Specifically , let K be the dictionary size, N b e the num ber of words app earing in a do cument, and h ∈ { 0 , 1 } F b e binary sto c hastic hidden topic features. Let V b e a N × K observed binary matrix with v ik = 1 if visible unit i takes on the k th v alue. W e define the energy of the state { V , h } as : E ( V , h ; θ ) = − N X i =1 F X j =1 K X k =1 W ij k h j v ik (1) − N X i =1 K X k =1 v ik b ik − N F X j =1 h j a j , where θ = { W , a , b } are the mo del parameters; W ij k is a symmetric interaction term b et w een visible unit i that takes on v alue k , and hidden feature j , b ik is the bias of unit i that takes on v alue k , and a j is the bias of hidden feature j . The probability that the mo del assigns to a visible binary matrix V is: P ( V ; θ ) = 1 Z ( θ , N ) X h exp ( − E ( V , h ; θ )) (2) Z ( θ , N ) = X V 0 X h 0 exp ( − E ( V 0 , h 0 ; θ )) , where Z ( θ , N ) is known as the partition function, or normalizing constan t. The key assumption of the Replicated Softmax mo del is that for each document we create a separate RBM with as many softmax units as there are w ords in the do cumen t, as shown in Fig. 1. Assuming that the order h ( 1 ) V W 1 W 1 W 1 W 2 W 2 W 2 W 1 W 2 Laten t T opics Laten t T opics Softmax Visibles Multinomial Visible Figure 1: The Replicated Softmax mo del. The top lay er represen ts a vector h of sto chastic, binary topic features and the b ottom la yer represents softmax visible units V . All visible units share the same set of weigh ts, connect- ing them to binary hidden units. Left: The mo del for a do cumen t containing three words. Righ t: A different in terpretation of the Replicated Softmax model, in which N softmax units with iden tical w eights are replaced by a single multinomial unit which is sampled N times. of the words can b e ignored, all of these softmax units can share the same set of w eights, connecting them to binary hidden units. In this case, the energy of the state { V , h } for a do cumen t that contains N words is defined as: E ( V , h ) = − F X j =1 K X k =1 W j k h j ˆ v k − K X k =1 ˆ v k b k − N F X j =1 h j a j , where ˆ v k = P N i =1 v k i denotes the count for the k th w ord. The bias terms of the hidden v ariables are scaled up b y the length of the do cumen t. This scaling is im- p ortan t as it allows hidden units to b eha v e sensibly when dealing with documents of differen t lengths. The conditional distributions are given by softmax and lo- gistic functions: P ( h (1) j = 1) = σ K X k =1 W j k ˆ v k + N a j , (3) P ( v ik = 1) = exp P F j =1 W j k h (1) j + b k P K k 0 =1 exp P F j =1 W j k 0 h (1) j + b k 0 . (4) The Replicated Softmax mo del can also b e in terpreted as an RBM mo del that uses a single visible m ultino- mial unit with supp ort { 1 , ..., K } which is sampled N times (see Fig. 1, righ t panel). F or this mo del, exact maxim um lik eliho od learning is in tractable, b ecause computing the deriv atives of the partition function, needed for learning, takes time that is exp onen tial in min { D , F } , i.e the num b er of visible or hidden units. In practice, approximate learning is p erformed using Contrastiv e Div ergence (CD) [6]. 3 Ov er-Replicated Softmax Mo del The Ov er-Replicated Softmax mo del is a family of tw o hidden lay er Deep Boltzmann Mac hines (DBM). Let us consider constructing a Boltzmann Machine with t wo hidden lay ers for a do cumen t containing N words, as shown in Fig. 2. The visible lay er V consists of N softmax units. These units are connected to a binary hidden la yer h (1) with shared w eigh ts, exactly like in the Replicated Softmax mo del in Fig. 1. The second hidden la yer consists of M softmax units represen ted b y H ( 2 ) . Similar to V , H ( 2 ) is an M × K binary matrix with h (2) mk = 1 if the m -th hidden softmax unit takes on the k -th v alue. The energy of the joint configuration { V , h (1) , H ( 2 ) } is defined as: E ( V , h (1) , H ( 2 ) ; θ ) = − N X i =1 F X j =1 K X k =1 W (1) ij k h (1) j v ik (5) − M X i 0 =1 F X j =1 K X k =1 W (2) i 0 j k h (1) j h (2) i 0 k − N X i =1 K X k =1 v ik b (1) ik − ( M + N ) F X j =1 h (1) j a j − M X i =1 K X k =1 h (2) ik b (2) ik where θ = { W (1) , W (2) , a , b (1) , b (2) } are the mo del parameters. Similar to the Replicated Softmax mo del, we create a separate do cument-specific DBM with as man y vis- ible softmax units as there are words in the do cu- men t. W e also fix the num ber M of the second- la yer softmax units across all do cumen ts. Ignoring the order of the words, all of the first lay er softmax units share the same set of weigh ts. Moreo v er, the first and second lay er w eights are tied. Th us w e hav e W (1) ij k = W (2) i 0 j k = W j k and b (1) ik = b (2) i 0 k = b k . Compared to the standard Replicated Softmax mo del, this mo del has more replicated softmaxes (hence the name “Ov er- Replicated”). Unlike the visible softmaxes, these addi- tional softmaxes are unobserv ed and constitute a sec- ond hidden la yer 1 . The energy can b e simplified to: E ( V , h (1) , H ( 2 ) ; θ ) = − F X j =1 K X k =1 W j k h (1) j ˆ v k + ˆ h (2) k (6) − K X k =1 ˆ v k + ˆ h (2) k b k − ( M + N ) F X j =1 h (1) j a j where ˆ v k = P N i =1 v ik denotes the coun t for the k th w ord in the input and ˆ h (2) k = P M i =1 h (2) ik denotes the coun t for the k th “laten t” word in the second hidden la yer. The joint probability distribution is defined as: P ( V , h (1) , H ( 2 ) ; θ ) = exp ( − E ( V , h (1) , H ( 2 ) ; θ )) Z ( θ , N ) , 1 This mo del can also be seen as a Dual-Wing Harmo- nium [17] in which one wing is unclamp ed. H ( 2 ) h ( 1 ) V W 1 W 1 W 1 W 1 W 1 W 2 W 2 W 2 W 2 W 2 W 1 W 2 W 1 W 2 Laten t T opics Softmax Visibles Softmax Hiddens Multinomial Visible Multinomial Hidden Figure 2: The Ov er-Replicated Softmax mo del. The b ot- tom lay er represents softmax visible units V . The middle la yer represents binary latent topics h (1) . The top la yer represen ts softmax hidden units H ( 2 ) . All visible and hid- den softmax units share the same set of weigh ts, connecting them to binary hidden units. Left: The mo del for a do cu- men t con taining N = 3 words with M = 2 softmax hidden units. Right: A differen t in terpretation of the mo del, in whic h N softmax units with iden tical weigh ts are replaced b y a single multinomial unit whic h is sampled N times and the M softmax hidden units are replaced by a multinomial unit sampled M times. Note that the normalizing constant dep ends on the n umber of words N in the corresp onding do cumen t, since the mo del con tains as many visible softmax units as there are words in the do cumen t. So the mo del can b e view ed as a family of different-sized DBMs that are created for do cumen ts of different lengths, but with a fixed-sized second-la yer. A pleasing prop ert y of the Over-Replicated Softmax mo del is that it has exactly the same num b er of train- able parameters as the Replicated Softmax mo del. Ho wev er, the mo del’s marginal distribution ov er V is differen t, as the second hidden la yer provides an addi- tional implicit prior. The mo del’s prior ov er the latent topics h (1) can be viewed as the geometric mean of the t wo probability distributions: one defined by an RBM comp osed of V and h (1) , and the other defined b y an RBM comp osed of h (1) and H ( 2 ) : 2 P ( h (1) ; θ ) = 1 Z ( θ , N ) X v exp F X j =1 K X k =1 W j k ˆ v k h (1) j ! | {z } RBM with h (1) and v X H ( 2 ) exp F X j =1 K X k =1 W j k ˆ h (2) k h (1) j | {z } RBM with h (1) and H ( 2 ) . (7) Observ e that P K k =1 ˆ v k = N and P K k =1 ˆ h (2) k = M , so the strength of this prior can b e v aried b y changing the n umber M of second-lay er softmax units. F or example, 2 W e omit the bias terms for clarity of presentation. if M = N , then the mo del’s marginal distribution o ver h (1) , defined in Eq. 7, is given by the pro duct of t w o iden tical distributions. In this DBM, the second-lay er p erforms 1 / 2 of the mo deling work compared to the first lay er [11]. Hence, for do cumen ts containing few w ords ( N M ) the prior ov er hidden topics h (1) will b e dominated by the second-lay er, whereas for long do cumen ts ( N M ) the effect of having a second- la yer will diminish. As we show in our exp erimen tal results, ha ving this additional flexibility in terms of defining an implicit prior o ver h (1) significan tly im- pro ves model performance, particularly for small and medium-sized do cumen ts. 3.1 Learning Let h = { h (1) , H ( 2 ) } b e the set of hidden units in the t wo-la yer DBM. Given a collection of L documents { V } L l =1 , the deriv ative of the log-likelihoo d with re- sp ect to mo del parameters W tak es the form: 1 L L X l =1 ∂ log P ( V l ; θ ) ∂ W j k = E P data h ( ˆ v k + ˆ h (2) k ) h (1) j i − E P Model h ( ˆ v k + ˆ h (2) k ) h (1) j i , where E P data [ · ] denotes an exp ectation with re- sp ect to the data distribution P data ( h , V ) = P ( h | V ; θ ) P data ( V ), with P data ( V ) = 1 L P l δ ( V − V l ) represen ting the empirical distribution, and E P Model [ · ] is an exp ectation with resp ect to the distribution de- fined by the mo del. Similar to the Replicated Soft- max mo del, exact maximum likelihoo d learning is in- tractable, but approximate learning can b e p erformed using a v ariational approach [10]. W e use mean-field inference to estimate data-dependent exp ectations and an MCMC based sto c hastic appro ximation pro cedure to approximate the mo dels expected sufficient statis- tics. Consider any approximating distribution Q ( h | V ; µ ), parameterized by a vector of parameters µ , for the p osterior P ( h | V ; θ ). Then the log-lik eliho o d of the DBM model has the follo wing v ariational lo wer b ound: log P ( V ; θ ) ≥ X h Q ( h | V ; µ ) log P ( V , h ; θ ) + H ( Q ) , where H ( · ) is the entrop y functional. The b ound be- comes tigh t if and only if Q ( h | V ; µ ) = P ( h | V ; θ ). F or simplicit y and sp eed, we appro ximate the true p os- terior P ( h | V ; θ ) with a fully factorized appro ximating distribution ov er the tw o sets of hidden units, whic h corresp onds to the so-called mean-field appro ximation: Q M F ( h | V ; µ ) = F Y j =1 q ( h (1) j | V ) M Y i =1 q ( h (2) i | V ) , (8) where µ = { µ (1) , µ (2) } are the mean-field parame- ters with q ( h (1) j = 1) = µ (1) j and q ( h (2) ik = 1) = µ (2) k , ∀ i ∈ { 1 , . . . , M } , s.t. P K k =1 µ (2) k = 1. Note that due to the shared weigh ts across all of the hidden softmaxes, q ( h (2) ik ) do es not dep enden t on i . In this case, the v ari- ational lo wer b ound tak es a particularly simple form: log P ( V ; θ ) ≥ X h Q M F ( h | V ; µ ) log P ( V , h ; θ ) + H ( Q M F ) ≥ ˆ v > + M µ (2) > W µ (1) − log Z ( θ , N ) + H ( Q M F ) , where ˆ v is a K × 1 vector, with its k th elemen t ˆ v k con- taining the coun t for the k th w ord. Since P K k =1 ˆ v k = N and P K k =1 µ (2) k = 1, the first term in the bound linearly com bines the effect of the data (which scales as N ) with the prior (which scales as M ). F or each training example, we maximize this low er b ound with respect to the v ariational parameters µ for fixed parameters θ , whic h results in the mean-field fixed-p oin t equations: µ (1) j ← σ K X k =1 W j k ˆ v k + M µ (2) k , (9) µ (2) k ← exp P F j =1 W j k µ (1) j P K k 0 =1 exp P F j =1 W j k 0 µ (1) j , (10) where σ ( x ) = 1 / (1 + exp( − x )) is the logistic func- tion. T o solve these fixed-point equations, w e simply cycle through lay ers, up dating the mean-field param- eters within a single la yer. Giv en the v ariational parameters µ , the model param- eters θ are then up dated to maximize the v ariational b ound using an MCMC-based sto chastic approxima- tion [10, 15, 18]. Let θ t and x t = { V t , h (1) t , h (2) t } b e the curren t parameters and the state. Then x t and θ t are up dated sequentially as follo ws: giv en x t , sam- ple a new state x t +1 using alternating Gibbs sampling. A new parameter θ t +1 is then obtained by making a gradien t step, where the intractable mo del’s expecta- tion E P model [ · ] in the gradient is replaced by a p oin t estimate at sample x t +1 . In practice, to deal with v ariable document lengths, w e tak e a minibatc h of data and run one Mark ov chain for eac h training case for a few steps. T o update the mo del parameters, w e use an av erage ov er those c hains. Simi- lar to Con trastive Divergence learning, in order to pro- vide a go o d starting p oin t for the sampling, we initial- ize each c hain at ˆ h (1) b y sampling from the mean-field appro ximation to the p osterior q ( h (1) | V ). 3.2 An Efficient Pretraining Algorithm The proper training pro cedure for the DBM model de- scrib ed ab o v e is quite slo w. This mak es it very impor- V H ( 2 ) = V W W h ( 1 ) Figure 3: Pretraining a t wo-la yer Boltzmann Mac hine using one-step contrastiv e divergence. The second hidden softmax lay er is initialized to be the same as the observ ed data. The units in the first hidden lay er hav e sto c hastic binary states, but the reconstructions of both the visible and second hidden lay er use probabilities, so b oth recon- structions are identical. tan t to pretrain the model so that the model param- eters start off in a nice region of space. F ortunately , due to parameter sharing b et ween the visible and hid- den softmax units, there exists an efficient pretraining metho d whic h makes the prop er training almost re- dundan t. Consider a DBM with N observed and M hidden soft- max units. Let us first assume that the num b er of hid- den softmaxes M is the same as the num b er of words N in a given do cumen t. If we were given the initial state v ector H ( 2 ) , we could train this DBM using one-step con trastive div ergence with mean-field reconstructions of b oth the states of the visible and the hidden softmax units, as sho wn in Fig. 3. Since we are not giv en the initial state, one option is to set H ( 2 ) to b e equal to the data V . Provided w e use mean-field reconstructions for b oth the visible and second-la yer hidden units, one- step con trastive div ergence is then exactly the same as training a Replicated Softmax RBM with only one hid- den lay er but with b ottom-up weigh ts that are twice the top-do wn weigh ts. T o pretrain a DBM with different num b er of visible and hidden softmaxes, we train an RBM with the b ottom-up w eights scaled by a factor of 1 + M N . In other words, in place of using W to compute the con- ditional probability of the hidden units (see Eq. 3), we use (1 + M N ) W : P ( h (1) j = 1 | V ) = σ (1 + M N ) K X k =1 v k W kj . (11) The conditional probability of the observ ed softmax units remains the same as in Eq. 4. This pro cedure is equiv alent to training an RBM with N + M observed visible units with each of the M extra units set to b e the empirical w ord distribution in the do cumen t, i.e.. for i ∈ { N + 1 , . . . , N + M } , v ik = P N j =1 v j k P N j =1 P K k 0 =1 v j k 0 Th us the M extra units are not 1-of-K, but represen t distributions o ver the K words 3 . This wa y of pretraining the Ov er-Replicated Softmax DBMs with tied weigh ts will not in general maximize the likelihoo d of the weigh ts. Ho wev er, in practice it pro duces mo dels that reconstruct the training data w ell and serve as a goo d starting point for generativ e fine-tuning of the t wo-la yer mo del. 3.3 Inference The p osterior distribution P ( h (1) | V ) represen ts the la- ten t topic structure of the observed document. Con- ditioned on the document, these activ ation probabili- ties can b e inferred using the mean-field approximation used to infer data-dep enden t statistics during training. A fast alternativ e to the mean-field p osterior is to m ul- tiply the visible to hidden w eights b y a factor of 1 + M N and approximate the true p osterior with a single ma- trix multiply , using Eq. 11. Setting M = 0 recov ers the prop er p osterior inference step for the standard Replicated Softmax mo del. This simple scaling op era- tion leads to significan t improv emen ts. The results re- p orted for retriev al and classification experiments used the fast pretraining and fast inference metho ds. 3.4 Cho osing M The num b er of hidden softmaxes M affects the strength of the additional prior. The v alue of M can b e chosen using a v alidation set. Since the v alue of M is fixed for all Over-Replicated DBMs, the effect of the prior will b e less for do cumen ts containing man y w ords. This is particularly easy to see in Eq. 11. As N b ecomes large, the scaling factor approac hes 1, di- minishing the part of implicit prior coming from the M hidden softmax units. Thus the v alue of M can b e c hosen based on the distribution of lengths of do cu- men ts in the corpus. 4 Exp erimen ts In this section, w e ev aluate the Over-Replicated Soft- max mo del b oth as a generativ e mo del and as a feature extraction metho d for retriev al and classification. Two datasets are used - 20 Newsgroups and Reuters Corpus V olume I (RCV1-v2). 3 Note that when M = N , we reco ver the setting of ha ving the b ottom-up weigh ts b eing twice the top-do wn w eights. 4.1 Description of datasets The 20 Newsgroups dataset consists of 18,845 p osts tak en from the Usenet newsgroup collection. Each p ost b elongs to exactly one newsgroup. F ollowing the prepro cessing in [12] and [7], the data w as partitioned c hronologically into 11,314 training and 7,531 test ar- ticles. After removing stopw ords and stemming, the 2000 most frequen t w ords in the training set were used to represen t the do cumen ts. The Reuters RCV1-v2 con tains 804,414 newswire ar- ticles. There are 103 topics whic h form a tree hier- arc hy . Thu s do cumen ts typically hav e multiple lab els. The data w as randomly split in to 794,414 training and 10,000 test cases. The av ailable data was already pre- pro cessed b y removing common stop words and stem- ming. W e use a v oc abulary of the 10,000 most frequent w ords in the training dataset. 4.2 T raining details The Ov er-Replicated Softmax mo del was first pre- trained with Con trastive Div ergence using the w eigh t scaling tec hnique describ ed in Sec. 3.2. Minibatches of size 128 w ere used. A v alidation set was held out from the training set for hyperparameter selection (1,000 cases for 20 newsgroups and 10,000 for R CV1-v2). The v alue of M and num b er of hidden units were chosen o ver a coarse grid using the v alidation set. T ypically , M = 100 p erformed well on b oth datasets. Increasing the n umber of hidden units lead to b etter performance on retriev al and classification tasks, until serious ov er- fitting became a problem around 1000 hidden units. F or p erplexity , 128 hidden units work ed quite w ell and ha ving to o many units made the estimates of the par- tition function obtained using AIS unstable. Starting with CD-1, the num b er of Gibbs steps was stepp ed up b y one after every 10,000 weigh t up dates till CD-20. W eight decay w as used to preven t ov erfitting. Addi- tionally , in order to encourage sparsity in the hidden units, KL-sparsity regularization was used. W e de- ca yed the learning rate as 0 1+ t/T , with T = 10 , 000 up dates. This approximate training was sufficien t to giv e go od results on retriev al and classification tasks. Ho wev er, to obtain go od p erplexity results, the mo del w as trained prop erly using the metho d describ ed in Sec. 3.1. Using 5 steps for mean-field inference and 20 for Gibbs sampling w as found to b e sufficien t. This additional training gav e impro v ements in terms of p er- plexit y but the impro vemen t on classification and re- triev al tasks was not statistically significant. W e also implemented the standard Replicated Softmax mo del. The training pro cedure was the same as the pretraining pro cess for the Ov er-Replicated Softmax mo del. Both the mo dels were implemented on GPUs. Pretraining took 3-4 hours for the 2-la yered Boltzmann T able 1: Comparison of the av erage test p erplexit y p er w ord. All models use 128 topics. 20 News Reuters T raining set size 11,072 794,414 T est set size 7,052 10,000 V ocabulary size 2,000 10,000 Avg Do cumen t Length 51.8 94.6 P erplexities Unigram 1335 2208 Replicated Softmax 965 1081 Ov er-Rep. Softmax ( M = 50) 961 1076 Ov er-Rep. Softmax ( M = 100) 958 1060 Mac hines (dep ending on M ) and the prop er training to ok 10-12 hours. The DocNADE mo del was run us- ing the publicly a v ailable code 4 . W e used default set- tings for all h yp erparameters, except the learning rates whic h were tuned separately for each hidden lay er size and data set. 4.3 Perplexit y W e compare the Over-Replicated Softmax mo del with the Replicated Softmax mo del in terms of p er- plexit y . Computing p erplexities inv olv es comput- ing the partition functions for these mo dels. W e used Annealed Imp ortance Sampling [9] for doing this. In order to get reliable estimates, we ran 128 Marko v c hains for each do cumen t length. The a verage test p erplexity p er w ord was computed as exp − 1 /L P L l =1 1 / N l log p ( v l ) , where N l is the num- b er of words in do cumen t l . T able 1 shows the per- plexit y a veraged ov er L = 1000 randomly c hosen test cases for each data set. Each of the mo dels has 128 laten t topics. T able 1 sho ws that the Over-Replicated Softmax mo del assigns slightly low er p erplexit y to the test data compared to the Replicated Softmax mo del. F or the Reuters data set the p erplexit y decreases from 1081 to 1060, and for 20 Newsgroups, it decreases from 965 to 958. Though the decrease is small, it is sta- tistically significant since the standard deviation was t ypically ± 2 o ver 10 random c hoices of 1000 test cases. Increasing the v alue of M increases the strength of the prior, which leads to further improv ements in p erplex- ities. Note that the estimate of the log probability for 2-lay ered Boltzmann Machines is a low er b ound on the actual log probability . So the p erplexities w e show are upper bounds and the actual p erplexities ma y be lo wer (provided the estimate of the partition function is close to the actual v alue). 4 http://www.dmi.usherb.ca/ ~ larocheh/code/ DocNADE.zip 20 Newsgroups (a) 128 topics (b) 512 topics Reuters R CV1-V2 (c) 128 topics (d) 512 topics Figure 4: Comparison of Precision-Recall curves for do cumen t retriev al. All Over-Replicated Softmax mo dels use M = 100 latent words. 4.4 Do cument Retriev al In order to do retriev al, we represen t each document V as the conditional p osterior distribution P ( h (1) | V ). This can be done exactly for the Replicated Softmax and Do cNADE mo dels. F or tw o-lay ered Boltzmann Mac hines, we extract this represen tation using the fast appro ximate inference as described in Sec. 3.3. Per- forming more accurate inference using the mean-field appro ximation metho d did not lead to statistically differen t results. F or the LDA, we used 1000 Gibbs sw eeps per test do cument in order to get an appro xi- mate p osterior ov er the topics. Do cumen ts in the training set (including the v alida- tion set) w ere used as a database. The test set w as used as queries. F or eac h query , do cumen ts in the database w ere rank ed using cosine distance as the sim- ilarit y metric. The retriev al task was performed sep- arately for each lab el and the results were av eraged. Fig. 4 compares the precision-recall curves. As shown b y Fig. 4, the Over-Replicated Softmax DBM out- p erforms other models on b oth datasets, particularly when retrieving the top few do cumen ts. T o find the source of impro vemen t, we analyzed the effect of do cument length of retriev al p erformance. Fig. 5 plots the av erage precision obtained for query do cumen ts arranged in order of increasing length. W e found that the Ov er-Replicated Softmax mo del gives large gains on do cumen ts with small num b ers of w ords, confirming that the implicit prior imp osed using a fixed v alue of M has a stronger effect on short do c- umen ts. As shown in Fig. 5, Do cNADE and Repli- cated Softmax mo dels often do not do w ell for do cu- men ts with few w ords. On the other hand, the Ov er- Replicated softmax mo del p erforms significan tly b et- ter for short documents. In most do cumen t collections, the length of do cumen ts ob eys a p o wer la w distribu- tion. F or example, in the 20 newsgroups dataset 50% of the documents hav e fewer than 35 w ords (Fig. 5c). This makes it very imp ortan t to do well on short do c- umen ts. The Ov er-Replicated Softmax model ac hieves this goal. 20 Newsgroups (a) 128 topics (b) 512 topics (c) Do cumen t length distribution Reuters (d) 128 topics (e) 512 topics (f ) Do cumen t length distribution Figure 5: Effect of document size on retriev al p erformance for different topic models. The x-axis in Figures (a), (b), (d), (e) represents test documents arranged in increasing order of their length. The y-axis sho ws the av erage precision obtained b y querying that document. The plots w ere smo othed to mak e the general trend visible. Figures (c) and (f ) sho w the histogram of do cument lengths for the resp ective datasets. The dashed vertical lines denote 10-p ercen tile b oundaries. T op : Average Precision on the 20 Newsgroups dataset. Bottom : Mean Average Precision on the Reuters dataset. The Ov er-Replicated Softmax mo dels p erforms significantly b etter for documents with few words. The adjoining histograms in each row show that such do cumen ts o ccur quite frequently in b oth data sets. 4.5 Do cument Classification In this set of experiments, w e ev aluate the learned rep- resen tations from the Ov er-Replicated Softmax mo del for the purp ose of do cumen t classification. Since the ob jective is to ev aluate the qualit y of the represen- tation, simple linear classifiers were used. Multino- mial logistic regression with a cross entrop y loss func- tion was used for the 20 newsgroups data set. The ev aluation metric was classification accuracy . F or the Reuters dataset, we used independent logistic regres- sions for eac h label since it is a multi-label classifica- tion problem. The ev aluation metric w as Mean Aver- age Precision. T able 2 shows the results of these exp erimen ts. The Ov er-Replicated Softmax mo del performs significantly b etter than the standard Replicated Softmax mo del and LDA across different net work sizes on b oth datasets. F or the 20 newsgroups dataset using 512 topics, LDA gets 64.2% accuracy . Replicated Softmax (67.7%) and Do cNADE (68.4%) impro ve up on this. The Over-Replicated Softmax mo del further impro ves T able 2: Comparison of Classification accuracy on 20 Newsgroups dataset and Mean Average Precision on Reuters RCV1-v2. Mo del 20 News Reuters 128 512 128 512 LD A 65.7 64.2 0.304 0.351 Do cNADE 67.0 68.4 0.388 0.417 Replicated Softmax 65.9 67.7 0.390 0.421 Ov er-Rep. Softmax 66.8 69.1 0.401 0.453 the result to 69.4%. The difference is larger for the Reuters dataset. In terms of Mean Av erage Precision (MAP), the Over-Replicated Softmax mo del ac hiev es 0.453 which is a very significant improv ement up on Do cNADE (0.427) and Replicated Softmax (0.421). W e further examined the source of impro vemen t by analyzing the effect of do cument length on the clas- sification performance. Similar to retriev al, we found that the Over-Replicated Softmax mo del p erforms well on short do cumen ts. F or long do cumen ts, the p erfor- mance of the differen t mo dels w as similar. 5 Conclusion The Over-Replicated Softmax mo del describ ed in this pap er is an effectiv e w ay of defining a flexible prior o ver the latent topic features of an RBM. This model causes no increase in the n umber of trainable param- eters and only a minor increase in training algorithm complexit y . Deep Boltzmann Mac hines are typically slo w to train. How ever, our fast appro ximate train- ing metho d makes it possible to train the mo del with CD, just like an RBM. The features extracted from do cumen ts using the Ov er-Replicated Softmax mo del p erform b etter than features from the standard Repli- cated Softmax and LDA mo dels and are comparable to Do cNADE across different netw ork sizes. While the num b er of hidden softmax units M , con- trolling the strength of the prior, was chosen once and fixed across all DBMs, it is p ossible to ha ve M de- p end on N . One option is to set M = cN , c > 0. In this case, for do cumen ts of all lengths, the second-la yer w ould p erform p erform c / c +1 of the mo deling work compared to the first lay er. Another alternativ e is to set M = N max − N , where N max is the maximum al- lo wed length of all do cumen ts. In this case, our DBM mo del will alw ays hav e the same num ber of replicated softmax units N max = N + M , hence the same arc hi- tecture and a single partition function. Giv en a do cu- men t of length N, the remaining N max − N words can b e treated as missing. All of these v ariations impro v e up on the standard Replicated Softmax mo del, LD A, and Do cNADE models, op ening up the space of new deep undirected topics to explore. References [1] Da vid M. Blei. Probabilistic topic mo dels. Com- mun. ACM , 55(4):77–84, 2012. [2] Da vid M. Blei, Thomas L. Griffiths, and Mic hael I. Jordan. The nested chinese restauran t pro cess and ba yesian nonparametric inference of topic hierarc hies. J. A CM , 57(2), 2010. [3] Da vid M. Blei, Andrew Ng, and Mic hael Jordan. Laten t diric hlet allo cation. JMLR , 3:993–1022, 2003. [4] K. Canini, L. Shi, and T. Griffiths. Online in- ference of topics with latent Dirichlet allocation. In Pr o c e e dings of the International Confer enc e on A rtificial Intel ligenc e and Statistics , v olume 5, 2009. [5] T. Griffiths and M. Steyvers. Finding scien tific topics. In Pr o c e e dings o f the National A c ademy of Scienc es , volume 101, pages 5228–5235, 2004. [6] Geoffrey E. Hinton. T raining pro ducts of ex- p erts by minimizing con trastive divergence. Neu- r al Computation , 14(8):1711–1800, 2002. [7] Hugo Laro c helle and Stanislas Lauly . A neural autoregressiv e topic mo del. In A dvanc es in Neur al Information Pr o c essing Systems 25 , pages 2717– 2725. 2012. [8] D. Mimno and A. McCallum. T opic mo dels conditioned on arbitrary features with diric hlet- m ultinomial regression. In UAI , pages 411–418, 2008. [9] Radford M. Neal. Annealed importance sampling. Statistics and Computing , 11(2):125–139, April 2001. [10] R. R. Salakhutdino v and G. E. Hinton. Deep Boltzmann machines. In Pr o c e e dings of the In- ternational Confer enc e on A rtificial Intel ligenc e and Statistics , volume 12, 2009. [11] Ruslan Salakhutdino v and Geoff Hin ton. A b etter w ay to pretrain deep b oltzmann mac hines. In A d- vanc es in Neur al Information Pr o c essing Systems 25 , pages 2456–2464. 2012. [12] Ruslan Salakh utdino v and Geoffrey Hin ton. Replicated softmax: an undirected topic mo del. In A dvanc es in Neur al Information Pr o c essing Systems 22 , pages 1607–1614. 2009. [13] Y. W. T eh, M. I. Jordan, M. J. Beal, and D. M. Blei. Hierarc hical Dirichlet processes. Journal of the Americ an Statistic al Asso ciation , 101(476):1566–1581, 2006. [14] Y. W. T eh, K. Kurihara, and M. W elling. Col- lapsed v ariational inference for HDP. In A dvanc es in Neur al Information Pr o c essing Systems , vol- ume 20, 2008. [15] T. Tieleman. T raining restricted Boltzmann ma- c hines using appro ximations to the lik eliho od gra- dien t. In ICML . ACM, 2008. [16] Chong W ang and David M. Blei. V ariational in- ference for the nested chinese restauran t pro cess. In NIPS , pages 1990–1998, 2009. [17] Eric P . Xing, Rong Y an, and Alexander G. Haupt- mann. Mining asso ciated text and images with dual-wing harmoniums. In UAI , pages 633–641. A UAI Press, 2005. [18] L. Y ounes. On the conv ergence of Marko vian sto c hastic algorithms with rapidly decreasing er- go dicit y rates, Marc h 17 2000.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment