Sparse Nested Markov models with Log-linear Parameters
Hidden variables are ubiquitous in practical data analysis, and therefore modeling marginal densities and doing inference with the resulting models is an important problem in statistics, machine learning, and causal inference. Recently, a new type of…
Authors: Ilya Shpitser, Robin J. Evans, Thomas S. Richardson
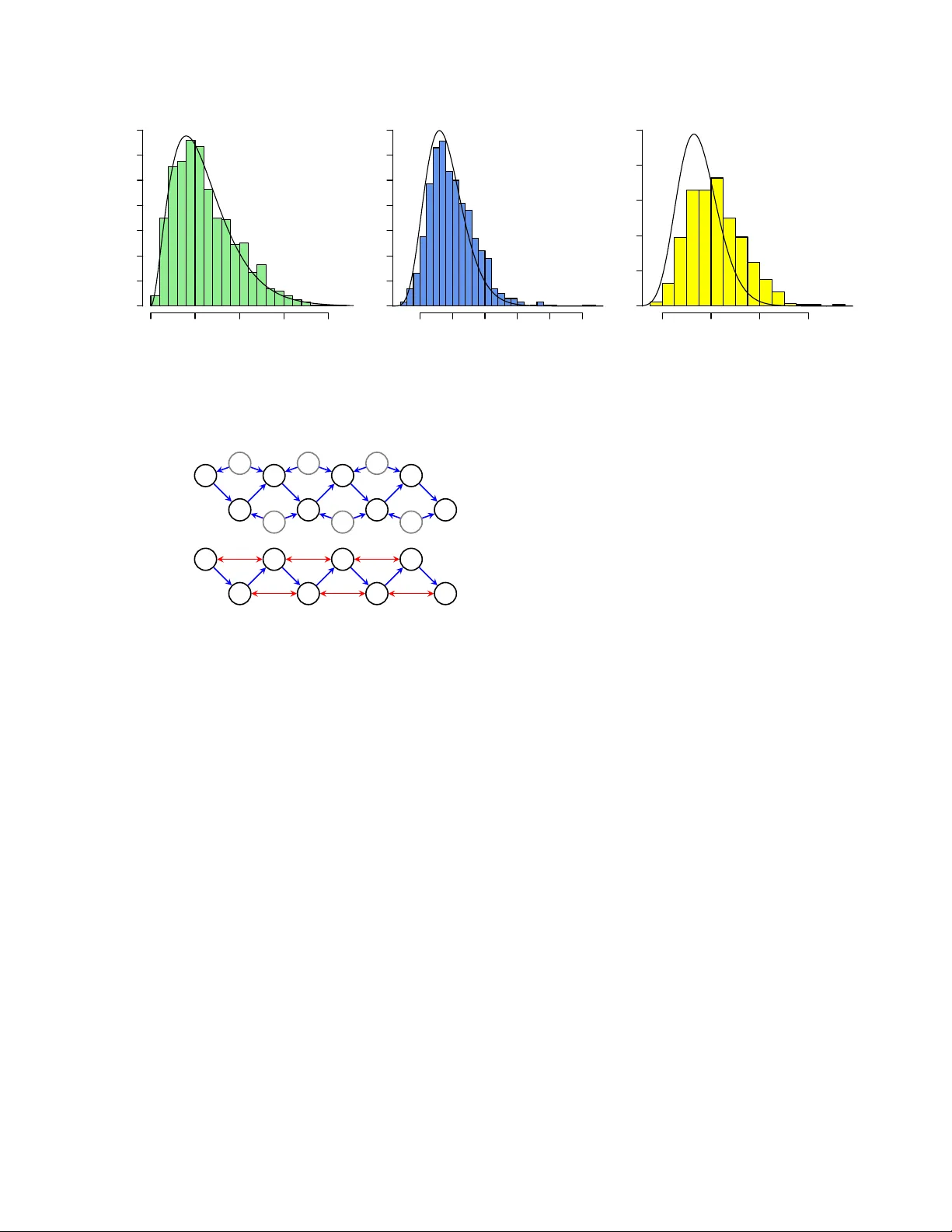
Sparse Nested Mark o v Mo dels with Log-linear P arameters Ily a Shpitser Mathematical Sciences Univ ersity of Southampton i.shpitser@soton.ac.uk Robin J. Ev ans Statistical Lab oratory Cam bridge Universit y rje42@cam.ac.uk Thomas S. Ric hardson Departmen t of Statistics Univ ersity of W ashington thomasr@u.w ashington.edu James M. Robins Departmen t of Epidemiology Harv ard Univ ersity robins@hsph.harv ard.edu Abstract Hidden v ariables are ubiquitous in practi- cal data analysis, and therefore mo deling marginal densities and doing inference with the resulting models is an imp ortan t problem in statistics, machine learning, and causal inference. Recen tly , a new type of graphi- cal mo del, called the nested Marko v mo del, w as developed which captures equality con- strain ts found in marginals of directed acyclic graph (D AG) mo dels. Some of these con- strain ts, suc h as the so called ‘V erma con- strain t’, strictly generalize conditional inde- p endence. T o make mo deling and inference with nested Marko v mo dels practical, it is necessary to limit the n umber of parameters in the mo del, while still correctly capturing the constrain ts in the marginal of a DA G mo del. Placing suc h limits is similar in spirit to sparsity metho ds for undirected graphical mo dels, and regression mo dels. In this paper, w e give a log-linear parameterization which allo ws sparse mo deling with nested Marko v mo dels. W e illustrate the adv antages of this parameterization with a sim ulation study . 1 In tro duction Analysis of complex multidimensional data is often made difficult by the twin problems of hidden v ari- ables, and a dearth of data relative to the dimension of the mo del. The former problem motiv ates the study of marginal and/or latent mo dels, while the latter has resulted in the dev elopment of sparsity metho ds. A particularly app ealing mo del for multidimensional data analysis is the Ba yesian net work or directed acyclic graph (DA G) mo del [10], where random v ari- ables are represented as vertices in the graph, with directed edges (arrows) b et ween them. The p opular- it y of D AG mo dels stems from their well understo od theory , and from the fact that they elicit an in tuitive causal interpretation: an arrow from a v ariable A to a v ariable B in a D AG mo del can b e interpreted, in a w ay whic h can b e made precise, to mean that A is a ‘direct cause’ of B . D AG mo dels assume all v ariables are observ ed, and a laten t v ariable mo del based on D AGs simply re- laxes this assumption. Ho wev er, latent v ariables in tro- duce a n umber of problems: it is difficult to correctly mo del the laten t state, and the resulting marginal den- sities are quite challenging to work with. An alter- nativ e is to enco de constraints found in marginals of D AG mo dels directly; a recen t approac h in this spirit is the nested Marko v mo del [15]. The adv an tage of the nested Marko v mo del is that it correctly captures the conditional indep endences and other equalit y con- strain ts found in marginals of DA G mo dels. How ev er, the discrete parameterization of nested Marko v mo d- els has the disadv antage of b eing unable to represent constrain ts in v arious marginals of DA Gs c oncisely , that is with few non-zero parameters. This implies that mo del selection metho ds based on scoring (via the BIC score [13] for instance) often prefer simpler mo dels which fail to capture indep endences correctly , but whic h contain many fewer parameters [15]. More generally , in high dimensional data analyses there is often such a shortage of samples that clas- sical statistical inference techniques do not work. T o address these issues, sparsity metho ds hav e b een de- v elop ed, which drive as many parameters in the sta- tistical mo del to zero as p ossible, while still providing a reasonable fit to the data. Sparsit y me thods hav e b een developed for regression mo dels [16], undirected graphical mo dels [8, 9], and even some marginal mo d- els [4]. It is not natural to apply sparsity techniques to ex- isting parameterizations of nested Marko v mo dels, b e- cause the parameters are context (or strata) sp ecific. 1 2 3 4 5 6 7 (a) 1 2 3 4 5 (b) Figure 1: (a) A DA G with no des 6 and 7 represent- ing hidden v ariables. (b) An ADMG representing the same conditional indep endences as (a) among the v ari- ables corresp onding to 1 , 2 , 3 , 4 , 5. In this pap er, we develop a log-linear parameteriza- tion for discrete nested Mark ov mo dels, where the pa- rameters represent (generalizations of ) log o dds-ratios within ‘kernels’ (informally ‘interv entional’ densities). These can b e viewed as interaction parameters, of the kind commonly set to zero b y sparsity metho ds. Our parameterization allo ws us to represent distributions con taining ‘V erma constrain ts’ in a sparse wa y , while main taining adv antages of nested Mark ov models, and a voiding the disadv an tages of using marginals of D AG mo dels directly . 2 Disadv antages of the M¨ obius P arameterization of Nested Marko v Mo dels One drawbac k of the standard parameterization of nested Mark o v models is that parameters are v ariation dep enden t; that is, fixing the v alue of one parameter constrains the ‘legal’ v alues of other parameters. This is in direct contrast with parameterizations of D AG mo dels where parameters asso ciated with a particu- lar Marko v factor (a conditional density for a v ariable giv en all its paren ts in the DA G) do not dep end on parameters asso ciated with other Marko v factors. W e illustrate another difficult y with an example. Here, and in subsequen t discussions, we will need to draw distinctions b et ween vertices in graphs, and corre- sp onding random v ariables in distributions or ‘kernels.’ W e use the following notation: v (low ercase) denotes a v ertex, X v the corresp onding random v ariable, and x v a v alue assignmen t to this v ariable. Lik ewise A (upp ercase) denotes a v ertex set, X A the corresp ond- ing random v ariable set, and x A an assignment to this set. Consider the marginal DA G sho wn in Fig. 1 (a). W e wish to av oid representing this domain with a DA G directly , in order not to commit to a particular state space of the unobserv ed v ariables X 6 and X 7 , and b e- cause, ev en if w e w ere willing to mak e suc h an assump- tion, the margin ov er ( X 1 , X 2 , X 3 , X 4 , X 5 ) obtained from a density that factorizes according to this DA G can b e complicated to work with [7]. T o use nested Marko v mo dels for this domain, we first construct an acyclic directed mixed graph (ADMG) that represents this DA G marginal, using the latent pro jection algorithm [17]. This graph is shown in Fig. 1 (b); directed arrows in the resulting ADMG repre- sen t directed paths in the D AG where an y intermediate no des are unobserved (in this case there are no such paths, and all directed edges in the ADMG are directly inherited from the D AG). Similarly , bidirected arro ws in the ADMG, such as 2 ↔ 5, represent marginally d- connected paths in the DA G which start and end with arro wheads p oin ting a wa y from the path, in this case 2 ← 6 → 5. If we now use the nested M¨ obius parameters, describ ed in more detail in subsequen t sections, to parameter- ize the resulting ADMG, we will quickly discov er that this results in a mo del of higher dimension relativ e to the dimension of DA G mo dels which share their sk ele- ton with this ADMG. F or example, the binary nested Mark ov mo del of the graph in Fig. 1 (b) has 16 param- eters, while b oth binary DA G mo dels corresp onding to graphs in Fig. 7 (a) and (b) hav e 11 parameters each. This leads to a w orry that a structure learning al- gorithm that tries to use nested M¨ obius parameters to recov er an ADMG from data by means of a score metho d, suc h as BIC [13], which rewards fit and pa- rameter parsimony , may prefer at low sample sizes in- correct indep endence mo dels given by DA Gs in pref- erence to correct mo dels given b y ADMGs, simply b e- cause the DA G mo dels comp ensate for their p oor fit of the data with a m uch smaller parameter count. In fact, this precise issue has b een observ ed in simulation studies rep orted in [15]. Addressing this problem with a M¨ obius parameteriza- tion is not easy , b ecause M¨ obius parameters are strata or context-specific; in other words, the parameteriza- tion is not indep endent of how the states are lab eled. F or instance, some of the M¨ obius parameters repre- sen ting confounding b et ween X 2 , X 4 and X 5 are: 1 θ { 2 , 4 , 5 } ( x 1 , x 3 ) = p (0 4 , 0 5 | x 3 , 0 2 , x 1 ) p (0 2 | x 1 ) for all v alues of x 1 , x 3 . In a binary mo del, this giv es 4 parameters. The kinds of regularities in the true gen- erativ e pro cess, whic h w e ma y w ant to exploit to cre- ate a dimension reduction in our mo del, typically in- v olve a lac k of in teractions among v ariables, or a laten t confounder with a low dimensional state space. Suc h regularities may often not translate into constraints naturally expressible in terms of M¨ obius parameters. T o av oid this difficulty , we need to construct parame- ters for nested Mark ov models which represen t v arious 1 T o sav e space, here and elsewhere we will write 1 i for an assignment of X i to 1, and 0 i for an assignment to 0. t yp es of interactions among v ariables directly . In fact, parameters represen ting in teractions are w ell kno wn in log-linear mo dels, of which undirected graphical mo d- els and certain regression mo dels form a sp ecial case. 3 Log-linear P arameters for Undirected Mo dels W e will use undirected graphical mo dels, also known as Marko v random fields, to illustrate log-linear mod- els. A Marko v random field ov er a multiv ariate binary state space X V , is a set of densities p ( x V ) represented b y an undirected graph G with vertices V , where p ( x V ) = exp X C ∈ cl( G ) ( − 1) k x C k 1 λ C ; here cl( G ) is the collection of (not necessarily maximal) cliques in the undirected graph, k · k 1 is the L 1 -norm, and λ C is a lo g-line ar p ar ameter . Note that the pa- rameter λ ∅ ensures the expression is normalized. Consider the undirected graph sho wn in Fig. 2. In this graph, all subsets of { 1 , 2 , 3 } , { 2 , 4 } , and { 4 , 5 , 6 } are cliques. The mo del represents densities where, condi- tional upon its adjacent no des, each no de is indepen- den t of all others. The log-linear parameter(s) corre- sp onding to eac h such subset of size k can b e viewed as represen ting k -w ay interactions among appropriate v ariables in the mo del. Setting some such interaction parameters to zero in a consistent wa y results in a mo del whic h still asserts the same conditional indepen- dences, but has a smaller parameter count, and with all strata in each clique treated symmetrically . F or in- stance, if we were to set all parameters for cliques of size k > 2 to zero, so that there remained only param- eters corresp onding to v ertices and individual edges, w e would obtain a mo del known as a Boltzmann ma- c hine [1]. A similar idea had b een used to give a sparse parameterization for discrete D AG mo dels [12]. In the remainder of the pap er, we describ e nested Mark ov mo dels, and giv e a log-linear parameteriza- tion for these mo dels which contains similar parame- ters that may b e set to zero. While in Marko v ran- dom field mo dels the parameters are asso ciated with sets of nodes which form cliques in the corresp onding undirected graph, in nested Marko v mo dels parame- ters will b e asso ciated with sp ecial sets of no des in the corresp onding ADMG called intrinsic sets . F urther, log-linear parameterizations of this t yp e can often in- corp orate individual-level contin uous baseline co v ari- ates [5]. 1 2 3 4 5 6 Figure 2: An undirected graph representing a log- linear mo del. 4 Graphs, Kernels, and Nested Mark o v Mo dels W e now introduce the relev an t bac kground needed to define the nested Mark ov mo del. A dir e cte d mixe d gr aph G ( V , E ) is a graph with a s et of v ertices V and a set of edges E , where the edges ma y b e directed ( → ) or bidirected ( ↔ ). A directed cycle is a path of the form x → · · · → y along with an edge y → x . An acyclic directed mixed graph (ADMG) is a mixed graph containing no directed cycles. An example is giv en in Fig. 1 (b). Let a , b and d b e v ertices in a mixed graph G . If b → a then we say that b is a p ar ent of a , and a is a child of b . If a ↔ b then a is said to b e a sp ouse of b . A vertex a is said to b e an anc estor of a v ertex d if either there is a directed path a → · · · → d from a to d , or a = d ; similarly d is said to b e a desc endant of a . The sets of paren ts, c hildren, sp ouses, ancestors and descendants of a in G are written pa G ( a ), c h G ( a ), sp G ( a ), an G ( a ), de G ( a ) resp ectively . W e apply these definitions dis- junctiv ely to sets, e.g. an G ( A ) = S a ∈ A an G ( a ). 4.1 Conditional ADMGs A c onditional acyclic directed mixed graph (CADMG) G ( V , W , E ) is an ADMG with a vertex set V ∪ W , where V ∩ W = ∅ , sub ject to the restriction that for all w ∈ W , pa G ( w ) = ∅ = sp G ( w ). The vertices in V are the r andom vertices, and those in W are called fixe d . Whereas an ADMG with vertex set V represents a join t densit y p ( x V ), a conditional ADMG represents the Marko v structure of a conditional densit y , or k ernel q V ( x V | x W ). F ollo wing [8, p.46], w e define a kernel to b e a non-negative function q V ( x V | x W ) satisfying: X x V q V ( x V | x W ) = 1 for all x W . (1) W e use the term ‘k ernel’ and write q V ( ·|· ) (rather than p ( ·|· )) to emphasize that these functions, though they satisfy (1) and thus most prop erties of conditional den- sities, are not in general formed via the usual op eration of conditioning on the ev ent X W = x W . T o conform with standard notation for densities, for ev ery A ⊆ V let q V ( x A | x W ) ≡ X V \ A q V ( x V | x W ) , q V ( x V \ A | x W ∪ A ) ≡ q V ( x V | x W ) q V ( x A | x W ) . F or a CADMG G ( V , W , E ) w e consider collections of random v ariables ( X v ) v ∈ V indexed by v ariables ( X w ) w ∈ W ; throughout this pap er the random v ari- ables take v alues in finite discrete sets ( X v ) v ∈ V and ( X w ) w ∈ W . F or A ⊆ V ∪ W we let X A ≡ × u ∈ A ( X u ), and X A ≡ ( X v ) v ∈ A . That we will alwa ys hold the v ariables in W fixed is precisely why w e do not p ermit edges b et w een vertices in W . An ADMG G ( V , E ) may b e seen as a CADMG in whic h W = ∅ . In this manner, though we will state sub- sequen t definitions for CADMGs, they also apply to ADMGs. The induc e d sub gr aph of a CADMG G ( V , W, E ) giv en b y a set A , denoted G A , consists of G ( V ∩ A, W ∩ A, E A ) where E A is the set of edges in G with b oth endp oin ts in A . In forming G A , the status of the vertices in A with regard to whether they are in V or W is pre- serv ed. 4.2 Districts and Mark ov Blank ets A set C is c onne cte d in G if ev ery pair of v ertices in C is joined by a path such that every vertex on the path is in C . F or a given CADMG G ( V , W , E ), denote by ( G ) ↔ the CADMG formed by removing all directed edges from G . A set connected in ( G ) ↔ is called bidir e cte d c onne cte d . F or a v ertex x ∈ V , the district (or c-comp onen t) of x , denoted by dis G ( x ), is the maximal bidirected con- nected set containing x . F or instance in the ADMG sho wn in Fig. 1 (b), the district of no de 2 is { 2 , 4 , 5 } . Districts in a CADMG form a partition of V ; vertices in W are excluded by definition. In a DA G G ( V , E ) the set of districts is the set of all single element sets { v } ⊆ V . A set of vertices A in G is called anc estr al if a ∈ A ⇒ an G ( a ) ⊆ A . In a CADMG G ( V , W , E ), if A is an ancestral subset of V ∪ W in G , t ∈ A ∩ V , and ch G ( t ) ∩ A = ∅ , then the Markov blanket of t in A is defined as: m b G ( t, A ) ≡ pa G dis G A ( t ) ∪ dis G A ( t ) \ { t } . 4.3 The fixing op eration and fixable vertices W e no w introduce a ‘fixing’ op eration on a CADMG whic h has the effect of transforming a random v ertex 1 2 3 4 5 (a) 1 2 3 4 (b) Figure 3: (a) The graph from Fig. 1 (b) after fixing 3. (b) An ADMG inducing a non-trivial nested Marko v mo del. in to a fixed vertex, thereby changing the graph. Ho w- ev er, this op eration is only applicable to a subset of the vertices, which we term the (p oten tially) fixable v ertices. Definition 1 Given a CADMG G ( V , W, E ) the set of fixable v ertices is F ( G ) ≡ { v | v ∈ V , dis G ( v ) ∩ de G ( v ) = { v }} . In words, v is fixable in G if there is no vertex v ∗ that is b oth a descendant of v and in the same district as v . F or the graph in Fig. 1 (b), the vertex 2 is not fixable, b ecause 4 is b oth its descendant and in the same district; all the other v ertices are fixable. Definition 2 Given a CADMG G ( V , W, E ) , and a kernel q V ( X V | X W ) , with every r ∈ F ( G ) we asso ciate a fixing transformation φ r on the p air ( G , q V ( X V | X W )) define d as fol lows: φ r ( G ) ≡ G ∗ ( V \ { r } , W ∪ { r } , E r ) , wher e E r is the subset of e dges in E that do not have arr owhe ads into r , and φ r ( q V ( x V | x W ); G ) ≡ q V ( x V | x W ) q V ( x r | x mb G ( r, an G (dis G ( r ))) ) Returning to the ADMG in Fig. 1 (b), fixing 3 in the graph means removing the edge 2 → 3, while fixing x 3 in p ( x 1 , x 2 , x 3 , x 4 , x 5 ) means dividing this marginal densit y by q 1 , 2 , 3 , 4 , 5 ( x 3 | x 2 ) = p ( x 3 | x 2 ). The resulting CADMG, shown in Fig. 3 (a), represents the resulting k ernel q 1 , 2 , 4 , 5 ( x 1 , x 2 , x 4 , x 5 | x 3 ). W e use ◦ to indicate comp osition of operations in the natural w ay , so that: φ r ◦ φ s ( G ) ≡ φ r ( φ s ( G )) and φ r ◦ φ s ( q V ( X V | X W ); G ) ≡ φ r ( φ s ( q V ( X V | X W ); G ) ; φ s ( G )) . 4.4 Reac hable and Intrinsic Sets In order to define the nested Marko v mo del, we will need to define sp ecial classes of v ertex sets in ADMGs. Definition 3 A CADMG G ( V , W ) is reachable fr om an ADMG G ∗ ( V ∪ W ) if ther e is an or dering of the ver- tic es in W = h w 1 , . . . , w k i , such that for j = 1 , . . . , k , w 1 ∈ F ( G ∗ ) and for j = 2 , . . . , k , w j ∈ F ( φ w j − 1 ◦ · · · ◦ φ w 1 ( G ∗ )) . A subgraph is reachable if, under some ordering, each v ertex w i is fixable in φ w i − 1 ( · · · φ w 2 ( φ w 1 ( G ∗ )) · · · ). Fixing operations do not in general comm ute, and thus only some orderings are v alid for fixing a particular set. F or example, in the ADMG shown in Fig. 1 (b), the set { 2 , 3 } may b e fixed, but only under the ordering where 3 is fixed first, to yield the CADMG shown in Fig. 3 (a), and then 2 is fixed in this CADMG. Fixing 2 first in Fig. 1 (b) is not v alid, b ecause 4 is b oth a descendan t of 2 and in the same district as 2 in that graph, and th us 2 is not fixable. If a CADMG G ( V , W ) is reachable from G ∗ ( V ∪ W ), w e say that the set V is reac hable in G ∗ . A reac hable set ma y be obtained by fixing v ertices using more than one v alid sequence. W e will denote an y v alid comp o- sition of fixing op erations that fixes a set A by φ A if applied to the graph, and by φ X A if applied to a k ernel. With a sligh t abuse of notation (though justified as we will later see) we suppress the precise fixing sequence c hosen. Definition 4 A set of vertic es S is in trinsic in G if it is a district in a r e achable sub gr aph of G . The set of intrinsic sets in an ADMG G is denote d by I ( G ) . F or example, in the graph in Fig. 1 (b), the set { 2 , 4 , 5 } is intrinsic (and reachable), while the set { 1 , 2 , 4 , 5 } is reac hable but not intrinsic. In any DA G G ( V , E ), I ( G ) = {{ x }| x ∈ V } , while in an y bidirected graph G , I ( G ) is equal to the set of all connected sets in G . 4.5 Nested Marko v Mo dels Just as for DA G mo dels, nested Marko v mo dels may b e defined via one of several equiv alent Marko v prop- erties. These prop erties are all neste d in the sense that they apply recursively to either reac hable or intrinsic sets derived from an ADMG. In particular, there is a nested analogue of the global Marko v prop ert y for D AGs (d-separation), the lo cal Marko v prop ert y for D AGs (whic h asserts that v ariables are indep enden t of non-descendan ts given paren ts), and the moralization- based prop ert y for DA Gs. These definitions app ear and are prov en equiv alent in [11]. It is p ossible to as- so ciate a unique ADMG with a particular marginal D AG mo del, and a nested Mark ov mo del asso ciated with this ADMG will reco ver all indep endences which hold in the marginal D AG [11]. W e now define a nested factorization on probability distributions represen ted b y ADMGs using special sets of no des called ‘recursive heads’ and ‘tails.’ Definition 5 F or an intrinsic set S ∈ I ( G ) of a CADMG G , define the r e cursive he ad (rh) as: rh( S ) ≡ { x ∈ S | ch G ( x ) ∩ S = ∅} . Definition 6 The tail asso ciate d with a r e cursive he ad H of an intrinsic set S in a CADMG G is given by: tail( H ) ≡ ( S \ H ) ∪ pa G ( S ) . In the graph in Fig. 1 (b), the recursive head of the in trinsic set { 2 , 4 , 5 } is equal to the set itself, while the tail is { 1 , 3 } . A kernel q V ( X V | X W ) satisfies the he ad factorization pr op erty for a CADMG G ( V , W, E ) if there exist k ernels { f S ( X H | X tail( H ) ) | S ∈ I ( G ) , H = rh G ( S ) } such that q V ( X V | X W ) = Y H ∈ J V K G S :rh G ( S )= H f S ( X H | X tail( H ) ) (2) where J V K G is a partition of V into heads giv en in [14]. Let G ( G ) ≡ { ( G ∗ , w ∗ ) | G ∗ = φ w ∗ ( G ) } for an ADMG G . That is, G ( G ) is the set of v alid fixing sequences and the CADMGs that they reach. The same graph ma y b e reached by more than one sequence w ∗ . W e say that a distribution p ( x V ) obeys the neste d he ad factor- ization pr op erty for G if for all ( G ∗ , w ∗ ) ∈ G ( G ), the k ernel φ w ∗ ( p ( X V ); G ) ob eys the head factorization for φ w ∗ ( G ) ≡ G ∗ . W e denote the set of such distributions b y P n h ( G ). Nested Marko v mo dels hav e b een defined via a nested district factorization criterion [15], and a n umber of Marko v prop erties [11]. The head factor- ization is another wa y of defining the nested Marko v mo del due to the following result. Theorem 7 The set P n h ( G ) is the neste d Markov mo del of G . Our decision to suppress the precise fixing sequence from the fixing op eration applied to sets is justified, due to the follo wing result. Theorem 8 If p ( x V ) is in the neste d Markov mo del of G , then for any r e achable set A in G , any valid fixing se quenc e on V \ A gives the same CADMG over A , and the same kernel q A ( x A | x V \ A ) obtaine d fr om p ( x V ) . 4.6 A M¨ obius Parameterization of Binary Nested Marko v Mo dels W e now give the original parameterization for binary nested Marko v mo dels. The approach generalizes in a straightforw ard wa y to finite discrete state spaces. Multiv ariate binary distributions in the nested Mark o v mo del for an ADMG G may b e parameterized by the follo wing: Definition 9 The nested M¨ obius parameters asso ci- ate d with a CADMG G ar e a set of functions: Q G ≡ q S ( X H = 0 | x tail( H ) ) for H = rh( S ) , S ∈ I ( G ) . In tuitively , a parameter q S ( X H = 0 | x tail( H ) ) is the probabilit y that the v ariable set X H assumes v alues 0 in a kernel obtained from p ( x V ) by fixing X V \ S , and conditioning on X tail( H ) . As a shorthand, w e will denote the parameter q S ( X H = 0 | x tail( H ) ) by θ H ( x tail( H ) ). Definition 10 L et ν : V ∪ W 7→ { 0 , 1 } b e an as- signment of values to the variables indexe d by V ∪ W . Define ν ( T ) to b e the values assigne d to variables in- dexe d by a subset T ⊆ V ∪ W . L et ν − 1 (0) = { v | v ∈ V , ν ( v ) = 0 } . A distribution P ( X V | X W ) is said to b e parameter- ized b y the set Q G , for CADMG G if: p ( X V = ν ( V ) | X W = ν ( W )) = X B : ν − 1 (0) ∩ V ⊆ B ⊆ V ( − 1) | B \ ν − 1 (0) | × Y H ∈ J B K G θ H ( X tail( H ) = ν (tail( H ))) (3) wher e the empty pr o duct is define d to b e 1 . F or example, the graph sho wn in Fig. 3 (b) rep- resen ting a mo del o ver binary random v ariables X 1 , X 2 , X 3 , X 4 is parameterized by the follo wing sets of parameters: θ 1 = p (0 1 ) θ 2 ( x 1 ) = p (0 2 | x 1 ) θ 1 , 3 ( x 2 ) = p (0 3 | x 2 , 0 1 ) p (0 1 ) θ 3 ( x 2 ) = X x 1 p (0 3 | x 2 , x 1 ) p ( x 1 ) θ 2 , 4 ( x 1 , x 3 ) = p (0 4 | x 3 , 0 2 , x 1 ) p (0 2 | x 1 ) θ 4 ( x 3 ) = X x 2 p (0 4 | x 3 , x 2 , x 1 ) p ( x 2 | x 1 ) . The total num b er of parameters is 1 + 2 + 2 + 2 + 4 + 2 = 13, which is 2 few er than a saturated parameterization of a 4 no de binary mo del, which contains 2 4 − 1 = 15 parameters. The tw o missing parameters reflect the fact that θ 4 ( x 3 ) do es not dep end on x 1 , which is a constrain t induced by the absence of the edge from 1 to 4 in Fig. 3 (b). Note that this constraint is not a conditional indep endence. In fact, no conditional indep endences o ver v ariables corresp onding to v ertices 1 , 2 , 3 , 4 are advertised in Fig. 3 (b). This parameterization maps θ H parameters to prob- abilities in a CADMG via the inv erse M¨ obius trans- form given by (3), and generalizes b oth the standard Mark ov parameterization of DA Gs in terms of param- eters of the form p ( x i = 0 | pa( x i )), and the parame- terization of bidirected graph mo dels given in [3]. 5 A Log-linear P arameterization of Nested Mark o v Mo dels W e begin by defining a set of ob jects whic h are func- tions of the observ ed density , and which will serve as our parameters. Definition 11 L et G ( V , E ) b e an ADMG and p ( x V ) a density over a set of binary r andom variables X V in the neste d Markov mo del of G . F or any S ∈ I ( G ) , let M = S ∪ pa G ( S ) , A ⊆ M (with A ∩ S 6 = ∅ ), and let q S ( x S | x M \ S ) = φ V \ S ( p ( x V ); G ) b e the asso ciate d kernel. Then define λ M A = 1 2 | M | X x M ( − 1) k x A k 1 log q S ( x S | x M \ S ) , to b e the nested log-linear parameter associated with A in S . F urther let Λ( G ) b e the c ol le ction { λ M A | S ∈ I ( G ) , M = S ∪ pa G ( S ) , rh G ( S ) ⊆ A ⊆ M } of these lo g-line ar p ar ameters. We c al l Λ( G ) the nested ingen uous parameterization of G . This parameterization is based on the graphical con- cepts of recursive heads and corresp onding tails. W e call the parameterization ‘nested ingen uous’ due to its similarit y to a marginal log-linear parameterization called ingenuous in [6], and in contrast to other log- linear parameterizations which may exist for nested Mark ov mo dels. Marginal mo del parameterizations of this type were first introduced in [2]. This definition extends easily to non-binary discrete data, in whic h case some parameters λ M A b ecome collections of pa- rameters. As an example, consider the graph shown in Fig. 3 (b) which represents a binary nested Marko v mo del. The nested ingenuous parameters asso ciated with the marginal p ( x 1 ) and conditional p ( x 2 | x 1 ) are λ 1 1 = 1 2 log p (0 1 ) p (1 1 ) λ 21 2 = 1 4 log p (0 2 | 0 1 ) · p (0 2 | 1 1 ) p (1 2 | 0 1 ) · p (1 2 | 1 1 ) λ 21 21 = 1 4 log p (0 2 | 0 1 ) · p (1 2 | 1 1 ) p (1 2 | 0 1 ) · p (0 2 | 1 1 ) whereas parameters asso ciated with the k ernel q 4 ( x 4 | x 3 ) = P x 2 p ( x 4 | x 3 , x 2 , x 1 ) p ( x 2 | x 1 ) are λ 43 4 = 1 4 log q 4 (0 4 | 0 3 ) · q 4 (0 4 | 1 3 ) q 4 (1 4 | 0 3 ) · q 4 (1 4 | 1 3 ) λ 43 43 = 1 4 log q 4 (0 4 | 0 3 ) · q 4 (1 4 | 1 3 ) q 4 (1 4 | 0 3 ) · q 4 (0 4 | 1 3 ) A parameter λ M A , where M is the union of a head H and its tail T , can b e viewed, by analogy with similar clique parameters in undirected log-linear models, as a | A | -w ay in teraction b et ween the v ertices in A , within the kernel corresp onding to M . F or instance the k ernel q 2 , 4 ( x 2 , x 4 | x 1 , x 3 ) = p ( x 4 | x 3 , x 2 , x 1 ) p ( x 2 | x 1 ), 2 mak es an appearance in 4 parameters in a binary mo del: λ 1234 24 , λ 1234 124 , λ 1234 234 , and λ 1234 1234 . If we set λ 1234 1234 to 0, w e claim there is no 4-w ay interaction b et w een X 1 , X 2 , X 3 , X 4 in the k ernel. It can b e sho wn that while the M¨ obius parameteriza- tion of the graph in Fig. 3 (b) is v ariation dep enden t, the nested ingen uous parameterization of the same graph is v ariation indep enden t. This is not true in general. In particular b oth parameterizations for the graph in Fig. 1 (b) are v ariation dep endent. 6 Main Results In this section w e prov e that the nested ingenuous pa- rameters indeed parameterize discrete nested Marko v mo dels. W e start with an intermediate result. Lemma 12 L et H ⊆ M and q ( x H | x M \ H ) b e a ker- nel. Then q is smo othly p ar ameterize d by the c ol- le ction of NLL p ar ameters { λ M A | H ⊆ A ⊆ M } to- gether with the ( | H | − 1) -dimensional mar gins of q , q ( x H \{ v } | x M \ H ) , v ∈ H . Pr o of: The pro of is essentially iden tical to the pro of of Lemma 4.4 in [6]. 6.1 The Main Result W e now define a partial order on heads and use this order to inductiv ely establish the main result. Definition 13 L et ≺ I ( G ) b e the p artial or der on he ads, H i , of intrinsic sets, S i , in G such that H i ≺ I ( G ) H j whenever S i ⊂ S j . Theorem 14 The neste d ingenuous p ar ameterization of an ADMG G with no des V p ar ameterizes pr e cisely those distributions p ( x V ) ob eying the neste d glob al Markov pr op erty with r esp e ct to G . 2 This kernel, viewed causally , is p ( x 2 , x 4 | do( x 1 , x 3 )). Pr o of: Let ≺ I ( G ) b e the partial ordering on heads giv en in Definition 13. W e pro ceed by induction on this ordering. F or the base case, w e know that sin- gleton heads { h } with empty tails are parameterized b y λ h h . If a singleton head has a non-empty tail, the conclusion follo ws immediately by Lemma 12. No w, supp ose that w e wish to find the kernel with a non-singleton head H † and a tail T † corresp onding to the intrinsic set S † . Assume, by inductive hypothe- sis, that we ha ve already obtained the kernels with all heads H such that H ≺ I ( G ) H † . W e claim this is sufficien t to give the ( | H † | − 1)-dimensional marginal k ernels q S † ( x H † \{ v } | x T † ), for all v ∈ H † . Fix a particular v ∈ H † . The set S † \ { v } is reachable, since V \ S † is a set with a v alid fixing sequence, and an y v ∈ H † has no c hildren in S † in φ V \ S † ( G ) so is fixable in φ V \ S † ( G ). Theorem 7 and Theorem 8 imply that for ev ery reachable set A , (2) holds. Hence: q S † ( x S † \{ v } | x V \ ( S † \{ v } ) ) = Y H ∈ J S † \{ v } K G S :rh G ( S )= H q S ( x H | x tail( H ) ) . (4) F or any S such that rh G ( S ) = H , and H ⊆ S † \ { v } , H ≺ I ( G ) H † , hence by the induction hypothesis, the k ernel q S ( x S | x pa ( S ) \ S ) is already obtained, and all k er- nels whic h app ear in (4) can be derived by condi- tioning from some suc h q S ( x S | x pa ( S ) \ S ). The desired k ernel q S † ( x H † \{ v } | x T † ) can itself b e obtained from q S † ( x S † \{ v } | x pa( S † ) \ S † ) b y conditioning. W e can rep eat this argument for any v ∈ H † . Fi- nally , the nested ingenuous parameterization con tains λ H † ∪ T † A for H † ⊆ A ⊆ H † ∪ T † . The result then follows b y Lemma 12. 7 Sim ulations T o illustrate the utilit y of setting higher order parame- ters to zero (‘remo ving’), w e present a sim ulation study based on the ADMG in Fig. 5 (b). This graph is a sp ecial case of t wo bidirected c hains of k vertices eac h, with a path of directed edges alternating betw een the c hains, for k = 4. The num b er of parameters in the relev an t binary nested Marko v mo del grows exp onen- tially with k in graphs of this t yp e. Consider also the laten t v ariable mo del defined by re- placing each bidirected edge with an indep enden t la- ten t v ariable shown in Fig. 5 (a), so that 1 ↔ 3 b e- comes 1 ← 9 → 3. If the state space of each laten t v ari- able is the same and fixed, then the num ber of param- eters in this hidden v ariable DA G mo del grows only linearly in k . This suggests that the nested Mark ov mo del may include higher order parameters whic h are 0 5 10 15 20 0.00 0.04 0.08 0.12 10 20 30 40 50 60 0.00 0.02 0.04 0.06 20 40 60 80 0.00 0.01 0.02 0.03 0.04 0.05 Figure 4: Histograms showing the increase in deviance asso ciated with setting to zero any nested log-linear parameters with effects higher than orders (from left to righ t) seven, six and five resp ectively . This corresp onds to remo ving 6, 18 and 35 parameters resp ectively; the relev an t χ 2 densit y is plotted in each case. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 (a) 1 2 3 4 5 6 7 8 (b) Figure 5: (a) A hidden v ariable D AG used to generate samples for Section 7. (b) The laten t pro jection of this generating D AG. not really necessary in this case (though the higher order parameters may b ecome necessary again if the state space of laten t v ariables grows). W e generated distributions from the latent v ariable mo del asso ciated with the DA G in Fig. 5 (a) as fol- lo ws: each of the six laten t v ariables tak es one of three states with equal probability , and each observed v ari- able takes the v alue 0 with a probability generated as an indep enden t uniform random v ariable on (0 , 1), conditional up on each p ossible v alue of its parents. F or each of 1,000 distributions pro duced independently using this metho d, we generated a dataset of size 5,000. W e then fitted the nested mo del generated by the graph in Fig. 5 (b) to each dataset b y maximum lik e- liho od estimation, using a v ariation of an algorithm found in [5], and measured the increase in deviance asso ciated with zeroing any nested ingenuous param- eters corresp onding to effects ab o ve a certain order. If these parameters w ere truly zero, we would exp ect the increase to follow a χ 2 -distribution with an ap- propriate n umber of degrees of freedom; the first tw o histograms in Fig. 4 demonstrate that the distribution of actual increases in deviance lo oks m uc h lik e the rele- v an t χ 2 -distribution if we remov e interactions of order 6 and higher. The third histogram shows that this starts to break down slightly when 5-wa y interactions are also zero ed. These results suggest that higher order parameters are often not useful for explaining finite datasets, and more parsimonious mo dels can b e obtained by remov- ing them; a similar simulation was p erformed for the Mark ov case in [6]. 7.1 Distinguishing Graphs The use of score-based search metho ds for recov ering nested Marko v mo dels had b een inv estigated [15]. It w as found that relatively large sample sizes were re- quired to reliably recov er the correct graph, even in examples with only 4 or 5 binary no des and after en- suring that the underlying distributions were appro x- imately faithful to the true graph. One phenomenon iden tified was that incorrect but more parsimonious graphs, esp ecially DA Gs, tended to hav e low er BIC scores than the correct mo dels, which include higher order parameters. Although BIC is guaranteed to b e smaller on the correct mo del asymptotically , in finite samples it applies strong p enalties for having addi- tional parameters with little explanatory p o w er. Here we present a simulation to show how the new parameterization can help to o vercome this difficulty . Using the metho d describ ed in the previous subsec- tion, we generated 1,000 multiv ariate binary distribu- tions which were nested Marko v with resp ect to the graph in Fig. 1 (b). F or each distribution w e gen- erated a dataset, and fitted the data to the correct mo del, which has 16 parameters, as well as the tw o D AGs giv en in Fig. 7 (a) and (b), which e ac h hav e 1e3 1e4 1e5 1e6 0.0 0.2 0.4 0.6 0.8 1.0 Sample Size Figure 6: F rom the experiment in Section 7.1: in red, the prop ortion of times graph in Fig. 1 (b) had low er BIC than the D AGs in Fig. 7, for v arying sample sizes; in blac k, the prop ortion of times some restricted v er- sion of this mo del had a low er BIC than an y restricted v ersions of either DA G. 11 parameters. This was rep eated at v arious sample sizes. The plot in Fig. 6 shows, in red, the prop ortion of times in which the BIC score for the correct mo del w as low er than that for eac h of the DA Gs, at v arious sample sizes. The correct graph only has the lo west BIC score of the three graphs on less than 3% of runs at sample size of n = 1,000, increasing to around 50% for n = 20,000. In addition to the full mo dels, we fitted the datasets to v ersions of the mo dels with higher order parameters remo ved; the graph in Fig. 1 (b) can b e restricted b y zeroing the 5-wa y parameter (leaving 15 free parame- ters), the 4-wa y and and ab o v e (13 params), or 3-wa y and abov e (10 params). Similarly w e can restrict the D AGs to hav e no 3-wa y effects, giving each mo del 10 free parameters. Fig. 6 sho ws, in black, the proportion of times that one of these restricted v ersions of the true mo del had a low er BIC than an y v ersion of either D A G mo del. W e see that the correct graph has the low est score in 40% of runs at n = 1,000, rising to around 70% at n = 20,000. Note that these results should not b e compared directly to those in [15], since the single ground truth la w used in that pap er was generated so as to ensure faithfulness to the correct graph, whereas w e are randomly sampling m ultiple la ws without b oth- ering to ensure an y particular prop erties in these laws other than consistency with the underlying D AG. These results suggest that these submo dels of the nested mo del ma y b e adv an tageous in recov ering the correct graphical structure using score-based metho ds. 1 2 3 4 5 (a) 1 2 3 4 5 (b) Figure 7: (a) and (b) tw o DA Gs with the same skeleton as the graph in Fig. 1 (b). Note that determining which higher order parameters should be set to zero for a given data set and sample size remains non-trivial. Automatic selection migh t b e p ossible with an L 1 -p enalized approach [16, 4]. 8 Discussion and Conclusions W e hav e introduced a new log-linear parameterization of nested Marko v mo dels o ver discrete state spaces. The log-linear parameters corresp ond to ‘in teractions’ in kernels obtained after an iterative application of truncation and marginalization steps (informally ‘in- teractions in interv en tional densities’). By contrast the M¨ obius parameters [15] corresp ond to context sp ecific effects in kernels (informally ‘context sp ecific causal effects’). W e hav e shown by means of a simulation study that in cases where data is generated from a marginal of a DA G with ‘weak confounders’, we can reduce the dimension of the mo del by ignoring higher order in- teraction parameters, while retaining the adv antages of nested Marko v mo dels compared to mo deling weak confounding directly in a D AG. Though there is no efficient, closed form mapping from ingen uous parameters to either M¨ obius parameters or standard probabilities, this is a smaller disadv antage than it may seem. This is because in cases where the ingenuous parameterization was used to select a particular submo del based on a dataset, we ma y still reparameterize and use M¨ obius parameters, or even standard join t probabilities if desired. Moreov er, this reparameterization step need only b e p erformed once, compared to m ultiple calls to a fitting procedure whic h iden tified the particular graph corresp onding to our submo del in the first place. The ingenuous and the M¨ obius parameterizations are th us complementary . The natural application of the ingen uous parameterization is in learning graph struc- ture from data in situations where many samples are not a v ailable, but we exp ect most confounding to b e w eak. The natural application of the M¨ obius param- eterization is the supp ort of probabilistic and causal inference in a particular graph [14, 15], in cases where an efficient mapping from parameters to joint proba- bilities is imp ortan t. References [1] D. H. Ackley , G. E. Hin ton, and T. J. Seino wski. A learning algorithm for boltzmann mac hines. Co gnitive Scienc e , 9(1):147–169, 1985. [2] W. P . Bergsma and T. Rudas. Marginal mo dels for categorical data. Annals of Statistics , 30(1):140–159, 2002. [3] M. Drton and T. S. Richardson. Binary mo dels for marginal indep endence. Journal of the R oyal Statisti- c al Society (Series B) , 70(2):287–309, 2008. [4] R. J. Ev ans. Paramet rizations of Discr ete Gr aphic al Mo dels . PhD thesis, Department of Statistics, Univer- sit y of W ashington, 2011. [5] R. J. Ev ans and A. F orcina. Two algorithms for fitting constrained marginal models. Computational Statis- tics & Data Analysis , 66:1–7, 2013. [6] R. J. Ev ans and T. S. Ric hardson. Marginal log-linear parameters for graphical Marko v models. Journal of the R oyal Statistic al So ciety (Series B) (to app e ar) , 2013. [7] D. Geiger, D. Heck erman, H. King, and C. Meek. Stratified exp onen tial families: Graphical mo dels and mo del selection. Annals of Statistics , 29(2):505–529, 2001. [8] S. L. Lauritzen. Gr aphic al Mo dels . Oxford, U.K.: Clarendon, 1996. [9] N. Meinshausen and P . B ¨ uhlmann. High-dimensional graphs and v ariable selection with the lasso. Annals of Statistics , 34(3):1436–1462, 2006. [10] J. Pearl. Pr ob abilistic R e asoning in Intel ligent Sys- tems . Morgan and Kaufmann, San Mateo, 1988. [11] T. S. Ric hardson, J. M. Robins, and I. Shpitser. Nested Mark ov properties for acyclic directed mixed graphs. In 28th Confer enc e on Unc ertainty in Artifi- cial Intel ligenc e (UAI-12) . A UAI Press, 2012. [12] T. Rudas, W. P . Bergsma, and R. Nemeth. Parame- terization and estimation of path mo dels for categor- ical data. In Pr o c e e dings in Computational Statistics, 17th Symp osium , pages 383–394. Physica-V erlag HD, 2006. [13] G. E. Sch warz. Estimating the dimension of a mo del. Annals of Statistics , 6:461–464, 1978. [14] I. Shpitser, T. S. Richardson, and J. M. Robins. An efficien t algorithm for computing interv entional dis- tributions in latent v ariable causal mo dels. In 27th Confer enc e on Unc ertainty in Artificial Intel ligenc e (UAI-11) . AUAI Press, 2011. [15] I. Shpitser, T. S. Richardson, J. M. Robins, and R. J. Ev ans. P arameter and structure learning in nested Mark ov mo dels. In UAI Workshop on Causal Struc- tur e Le arning 2012 , 2012. [16] R. Tibshirani. Regression shrink age and selection via the lasso. Journal of the R oyal Statistic al Society (Se- ries B) , 58(1):267–288, 1996. [17] T. S. V erma and Judea Pearl. Equiv alence and synthe- sis of causal mo dels. T ec hnical Rep ort R-150, Depart- men t of Computer Science, Universit y of California, Los Angeles, 1990.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment