Stochastic Rank Aggregation
This paper addresses the problem of rank aggregation, which aims to find a consensus ranking among multiple ranking inputs. Traditional rank aggregation methods are deterministic, and can be categorized into explicit and implicit methods depending on…
Authors: Shuzi Niu, Yanyan Lan, Jiafeng Guo
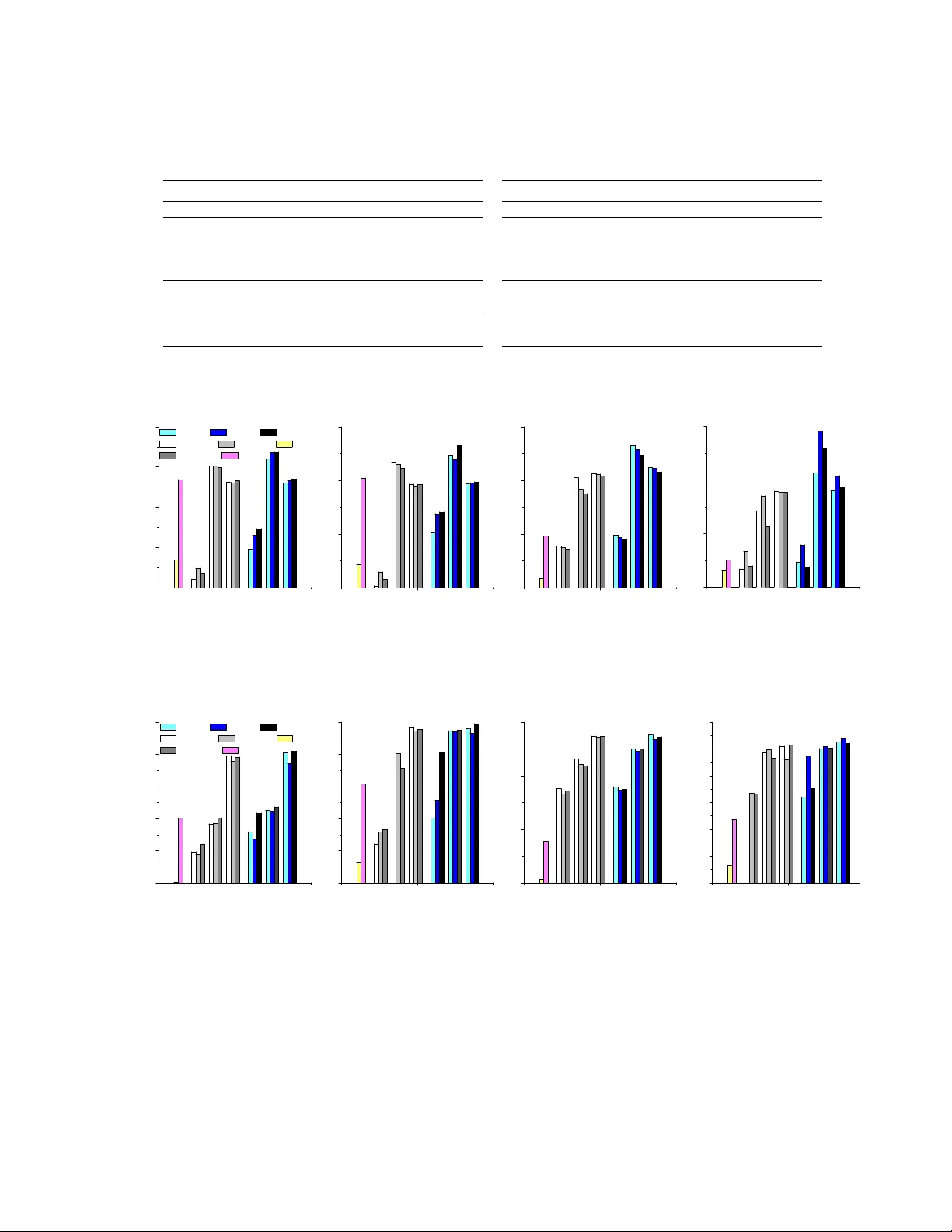
Sto c hastic Rank Aggregation Sh uzi Niu Y an yan Lan Jiafeng Guo Xueqi Cheng Institute of Computing T echnology , Chinese Academ y of Sciences, Beijing, P . R. China niush uzi@softw are.ict.ac.cn, { lany any an,guo jiafeng,cxq } @ict.ac.cn Abstract This pap er addresses the problem of rank aggregation, which aims to find a consensus ranking among m ultiple ranking inputs. T ra- ditional rank aggregation metho ds are deter- ministic, and can b e categorized in to explicit and implicit metho ds dep ending on whether rank information is explicitly or implicitly utilized. Surprisingly , exp erimen tal results on real data sets show that explicit rank ag- gregation metho ds would not w ork as well as implicit metho ds, although rank information is critical for the task. Our analysis indicates that the ma jor reason might be the unreli- able rank information from incomplete rank- ing inputs. T o solve this problem, w e prop ose to incorp orate uncertaint y into rank aggrega- tion and tackle the problem in b oth unsup er- vised and sup ervised scenario. W e call this no vel framew ork stochastic r ank aggr e gation (St.Agg for short). Sp ecifically , we introduce a prior distribution on ranks, and transform the ranking functions or ob jectives in tradi- tional explicit metho ds to their exp ectations o ver this distribution. Our exp erimen ts on b enc hmark data sets show that the prop osed St.Agg outp erforms the baselines in b oth un- sup ervised and sup ervised scenarios. 1 INTR ODUCTION Rank aggregation is a cen tral problem in many ap- plications, suc h as metasearc h, collaborative filtering and crowdsourcing tasks, where it attempts to find a consensus ranking among m ultiple ranking inputs. In literature, deterministic rank information has b een utilized to solve the rank aggregation problem, and we refer these metho ds as deterministic r ank aggr e gation . The conv entional methods can b e further divided into t wo categories: explicit and implicit metho ds. F or ex- plicit metho ds (Aslam & Montague, 2001; Cormac k et al., 2009), rank information is explicitly utilized for rank aggregation, e.g., (Aslam & Montague, 2001) uses the mean rank as the score and sorts items in ascend- ing order. While for implicit metho ds (Gleich & Lim, 2011; Th urstone, 1927), rank information is used im- plicitly , e.g., (Thurstone, 1927) defines the generative probabilit y of pairwise preferences based on rank infor- mation and adopts the maximum likelihoo d pro cedure for aggregation. Although rank information is crucial for the rank aggregation task, surprisingly , the explicit methods w ould not work well as implicit metho ds in practice. Our exp eriments on real data sets sho w that the im- plicit methods outp erform explicit methods, in b oth unsup ervised and sup ervised scenarios. The ro ot of the problem ma y lie in the unreliable rank information from multiple incomplete ranking inputs. T ypically , the ranking inputs in rank aggregation are partial rankings. F or example, in metasearch, only top searc h results are returned from each meta search en- gine with resp ect to its rep ository; in a recommender system, users only rate the items they hav e ev er seen. The incompleteness of the partial ranking makes the ranks of items no longer reliable. T aking the recom- mender system as an example, we do not kno w whether an unseen item will b e ranked higher or low er than the already rated ones for the user. As indicated by (V o orhees, 2002; F arah & V anderp o oten, 2007), the in- correct rank information will reduce the p erformance of an y explicit method. Therefore, it is not surpris- ing to see the failure of explicit metho ds based on the curren t unreliable rank information. T o amend this problem, we prop ose to incorp orate un- certain ty into rank aggregation and tackle the problem in b oth unsup ervised and sup ervised scenario. W e re- fer this nov el rank aggregation framework as sto chas- tic r ank aggr e gation (St.Agg for short). Specifically , a prior distribution deriv ed from pairwise contests is in tro duced on ranks to accommo date the unreliable rank information, since it has b een prov en that rank information enco ded in a pairwise w ay will b e robust (F arah & V anderp o oten, 2007). W e then define the new ranking functions or ob jectives (in unsup ervised or sup ervised resp ectiv ely) as the exp ectation of those in traditional methods with respect to the rank dis- tribution. In unsup ervised scenario, the new rank- ing functions are used to find the final ranking list. In sup ervised scenario, the learning to rank technique is employ ed to complete the rank aggregation task. Sp ecifically , a feature represen tation for each item is first designed, based on explicit features in (Aslam & Mon tague, 2001) and latent features in (V olko vs et al., 2012; Kolda & Bader, 2009). A gradien t metho d is then emplo yed to optimize the new ob jectiv es. Our exp eriments on benchmark data sets sho w that the prop osed St.Agg significan tly outp erforms tradi- tional rank aggregation metho ds, in b oth unsup ervised and sup ervised scenarios. F urthermore, we conduct exp erimen ts to demonstrate that St.Agg is more ro- bust than traditional metho ds, sho wing the b enefit of uncertain ty . In summary , w e prop ose a nov el rank aggregation framew ork whic h incorp orates uncertain ty of rank in- formation. Our ma jor con tributions include: (1) the finding that partial ranking inputs in rank aggregation will make the explicit methods fail, due to unreliable rank information; (2) the definition of rank distribu- tion based on pairwise contests, which is the basis of sto c hastic rank aggregation; and (3) the prop osal of a unified rank aggregation framework in b oth unsup er- vised and sup ervised scenarios. The rest of the pap er is organized as follo ws. W e first in tro duce some backgrounds on rank aggregation in Section 2, and then conduct some empirical study and analysis on why explicit metho ds will not work well in rank aggregation. Section 4 describ es the framework of sto c hastic rank aggregation, including the definition of rank distribution and St.Agg in b oth unsup ervised and sup ervised scenarios. Section 5 presents our ex- p erimen tal results and Section 6 concludes the pap er. 2 BA CK GR OUNDS In this section, we introduce some bac kgrounds on rank aggregation, including problem definition, pre- vious metho ds and ev aluation measures. 2.1 PR OBLEM DEFINITION In unsup ervised scenario, w e are given a set of n items { x 1 , · · · , x n } and multiple ranking inputs τ 1 , · · · , τ m o ver these items. τ i ( x j ) stands for the p osition of x j in the ranking τ i . If the length of τ i is n , τ i is called a full ranking; otherwise, it is called a partial ranking. The goal of unsupervised rank aggregation is to find a final ranking π ∈ Π ov er all the n items which b est reflects the ranking order in the ranking inputs, where Π is the space of all the full ranking with length n . T o ac hieve this goal, many aggregation algorithms try to optimize a similarity function F b et ween the ranking inputs τ 1 , · · · , τ m and the final ranking result π , while some other aggregation algorithms directly give the form of their final ranking function f without explicit optimization ob jectives. In supervised scenario, we are given N sets of items, denoted as D i = { x ( i ) 1 , · · · , x ( i ) n i } , i = 1 , · · · , N . F or each item set D i , a collection of ranking inputs τ ( i ) 1 , · · · , τ ( i ) m i are ov er this set. The ground-truth lab els for all items are provided in the form of multi-lev el ratings, such as three level ratings (2:highly relev ant, 1:relev ant, 0:ir- relev ant), denoted as Y ( i ) = ( y ( i ) 1 , · · · , y ( i ) n i ). In the training pro cess, an aggregation function f of ranking inputs is learned by optimizing a sum of a similar- it y function F on N sets, and F measures the sim- ilarit y b etw een these ranking inputs and the corre- sp onding ground-truth ranking. F or prediction, given an y item set D = { x 1 , · · · , x n } and m ranking inputs τ 1 , · · · , τ m o ver this set, the final ranking π is com- puted b y π = f ( τ 1 , · · · , τ m ). 2.2 METHODS Previous rank aggregation metho ds can be divided into t wo categories according to the w ay that rank infor- mation is used: explicit and implicit rank aggregation metho ds. Explicit metho ds directly utilize rank infor- mation to define the ranking function or the ob jectiv e function. While for implicit metho ds, other informa- tion such as pairwise preference or list wise ranking are first constructed based on the rank information, and then lev eraged for rank aggregation. 2.2.1 Unsup ervised Aggregation Metho ds Firstly , let w e in tro duce the t wo kinds of metho ds in unsup ervised scenario, resp ectiv ely . Explicit Metho ds. In unsupervised scenario, ex- plicit metho ds define the ranking function as the sum of utilit y functions of each items’s rank information, and then sort the items in descending order. The for- m ulation is describ ed as follo ws. f ( x j ) = m i =1 u ( x j , τ i ) , (1) where u ( · , · ) stands for the utility function. F or exam- ple, (Aslam & Montague, 2001) used the mean p osition as the ranking function as sho wn in Eq.(2), and (Cor- mac k et al., 2009) defined the reciprocal rank as the ranking function to further emphasize the top rank ed items as sho wn in Eq.(3). f ( x j ) = m i =1 u ( x j , τ i ) = m i =1 ( n − τ i ( x j )) , (2) f ( x j ) = m i =1 u ( x j , τ i ) = m i =1 1 C + τ i ( x j ) , (3) where C is a constant, n i is the length of τ i and τ i ( x j ) in b oth Eq.(2) and Eq.(3) means the p osition of x j in ranking τ i . Implicit Metho ds. (Dwork et al., 2001) used a Lo cal Kemenization pro cedure to approximate an optimal solution to minimize Kendall’s tau distance. (Gleic h & Lim, 2011) defined the difference b et w een the pairwise preference matrix from ranking input and the aggre- gated preference matrix, and adopted matrix factoriza- tion for optimization. (Th urstone, 1927) and (V olko vs & Zemel, 2012) defined the similarity measure to b e the generative probabilit y of pairwise preferences and then adopted the maximum likelihoo d procedure for aggregation. (Guiv er & Snelson, 2009) and (Lebanon & Lafferty , 2002) defined the similarit y measure to b e the generative probability of each ranking list and op- timized this similarity function by a maxim um lik eli- ho od pro cedure. 2.2.2 Sup ervised Aggregation Metho ds Secondly , we con tinue to in tro duce the t wo kinds of metho ds in sup ervised scenario, resp ectively . Explicit Metho ds. F or explicit methods in super- vised scenario, features are first extracted from the ranking inputs, and then the rank information gen- erated by the ranking function of these features are directly used in the ob jective function. After that, learning-to-rank technique are utilized for optimiza- tion. F or example, (V olko vs et al., 2012) prop osed to use ev aluation measures as the ob jective function, such as NDCG (Normalized Discounted Cumulativ e Gain) (J¨ arv elin & Kek¨ al¨ ainen, 2002), ERR (Exp ected Recip- ro cal Rank) (Chap elle et al., 2009) and RBP (Rank Biased Precision) (Moffat & Zob el, 2008). This ap- proac h is called RankAgg, and w e will review their mathematical form ulations in Section 2.3. Implicit Metho ds. (Liu et al., 2007) prop osed to minimize the num b er of disagreeing pairs b et ween the aggregated ranking result and the ground-truth. (V olko vs & Zemel, 2012) heuristically computed the similarit y b et ween the ranking input and the ground- truth to obtain the exp ertise degree of the corresp ond- ing annotator. The learned w eights are then used to aggregate the ranking lists for future data. (Qin et al., 2010) introduced coset-p erm utation distance in to Plack ett-Luce mo del for rank aggregation. 2.3 EV ALUA TION MEASURES Rank information is explicitly used in ev aluation mea- sures for rank aggregation, such as NDCG (J¨ arvelin & Kek¨ al¨ ainen, 2002), RBP (Moffat & Zob el, 2008) and ERR (Chap elle et al., 2009). W e would like to ex- press these measures as the sum of differences on each item’s generated rank and ground-truth, as sho wn in the follo wing equation. E v ( π , Y ) = n j =1 v ( y j , r j ) , (4) where E v stands for any ev aluation measure, v ( · , · ) stands for the difference function. W e give the exact forms of NDCG, RBP and ERR as follows. N DC G ( π , Y ) = n j =1 g ( y j ) D ( r j ) D C G max ( n ) , (5) where r j stands for the rank of x j in the final rank- ing π . g ( y j ) is the gain function with g ( y j ) = 2 y j − 1, D ( r j ) is the discount function with D ( r j ) = 1 log (1+ r j ) , and D C G max ( n ) stands for the maximum of n j =1 g ( y j ) D ( r j ) o ver Π. E RR ( π, Y ) = n j =1 1 r j P { users stop at r j } , (6) where the probability P { users stop at r j } is defined as i ∈{ i | r i 0 (9) (2) Eac h time w e add a new item x i , the rank will get one larger if x j is b eaten b y x i and it will sta y unc hanged otherwise. Therefore the rank distri- bution for item x j will b e updated by the follo wing recursiv e relation: P ( t ) ( R ( x j , τ ) = r ) = P ( t − 1) ( R ( x j , τ ) = r − 1) p ( x i ≻ τ x j ) + P ( t − 1) ( R ( x j , τ ) = r )(1 − p ( x i ≻ τ x j )) . (10) (3) After n − 1 iterations, P ( n ) ( R ( x j , τ ) = r ) will b e the final distributions P ( R ( x j , τ ) = r ). Based on the definition of rank distribution ab o ve, the ranking function or ob jective function used in an ex- plicit metho d can be turned into a new function b y tak- ing the exp ectation ov er this rank distribution, which will b e used in the new rank aggregation metho d, de- scrib ed in the following section. 4.2 UNSUPER VISED ST.AGG First we introduce the sp ecific form of pairwise prob- abilit y p ( x i ≻ τ x j ) for the computation of rank dis- tribution P ( R ( x j , τ ) = r ) in unsup ervised scenario. The exp ectations of ranking functions in explicit meth- o ds are then computed ov er the rank distribution, and used to obtain the final aggregated ranking. W e de- note our unsup ervised St.Agg as St.Agg f for different ranking functions. 4.2.1 Definition of Pairwise Probabilit y Inspired by the robust rank difference information (F arah & V anderp o oten, 2007) underlying in the rank- ing list, we define p ( x i , x j ) as the function of rank dif- ference b et w een x i and x j in the full ranking τ D τ o ver the subset D τ ⊆ D such as | τ D τ ( x i ) − τ D τ ( x j ) | n . W e w ould lik e to giv e an example of the definition of the pairwise probabilit y p ( x i ≻ τ x j ) satisfying p ( x i ≻ τ x j ) + p ( x j ≻ τ x i ) = 1 as b elo w : min { p ( x i ,x j ) , 1 − p ( x i , x j ) } , if τ D τ ( x i ) > τ D τ ( x j ) max { p ( x i ,x j ) , 1 − p ( x i , x j ) } , if τ D τ ( x i ) < τ D τ ( x j ) 0 . 5 , otherwise (11) Incorp orating Eq.(11) to the recursive pro cess Eq.(10), w e can obtain the probabilit y distribution o ver ranks P ( R ( x j , τ ) = r ). 4.2.2 Exp ectations As mentioned in section 2, the ranking function f ( x j ) in explicit metho ds is a sum of the utility function of rank information of a certain item from multiple ranking inputs. Thus w e can simply calculate the ex- p ectation of the ranking function f s ( x j ) ov er the rank distribution prop osed ab o ve. F or example, the new ranking function f s ( x j ) in St.Agg B C and St.Agg RRF can b e obtained b y incor- p orating rank distribution P ( R ( x j , τ i ) = r ) into the mean p osition function in Eq.(2) and the recipro cal rank function in Eq.(3) resp ectiv ely , as shown b elo w. f s ( x j ) = 1 m m i =1 n − 1 r =0 ( n − r ) P ( R ( x j , τ i ) = r ) , (12) f s ( x j ) = m i =1 n − 1 r =0 P ( R ( x j , τ i ) = r ) r + C . (13) where B C is short for Borda Count. F or such new aggregation metho ds, the final ranking is obtained by sorting in descending order of f s ( x j ). 4.3 SUPER VISED ST.AGG In sup ervised scenario, we utilize the state-of-the-art learning framework for the optimization problem in rank aggregation lik e RankAgg F (V olko vs et al., 2012) men tioned in the section 2.2. Similarly we denote our sup ervised St.Agg as St.Agg F for different definitions of optimization functions. Firstly , the sp ecific form of pairwise probabilit y p ( x i ≻ π x j ) for the computation of rank distribution P ( R ( x j , π ) = r ) is defined based on the aggregated ranking π . Then the optimization ob jectives in our sup ervised St.Agg can b e defined as the exp ectation of these ob jectiv es o ver rank distributions P ( R ( x j , π ) = r ). T o solv e this aggregation problem by a learn- ing pro cedure, a prop er feature mapping is first de- signed for represen tation, and then a gradient-based optimization metho d is adopted to learn the ranking function f . 4.3.1 Definition of the P airwise Probabilit y P airwise probability is defined on the basis of the ranking function f . Therefore, we define the score of eac h item x i as a normal random v ariable de- noted as s i with exp ectation f ( x i ) and v ariance σ 2 , i.e. s i ∼ N ( f ( x i ) , σ 2 ). Similar to the definition in unsup ervised scenario, the pairwise probability can b e defined as the function of score difference to reflect that the larger the score dif- ference betw een x i and x j , the more probable that x j is defeated by x i . Thus p ( x i ≻ π x j ) can b e defined as P ( s i − s j > 0), where s i − s j ∼ N ( f ( x i ) − f ( x j ) , 2 σ 2 ). The computation of p ( x i ≻ π x j ) can be taken as the follo wing Eq.(14). p ( x i ≻ π x j ) = + ∞ 0 1 2 σ √ π e − ( x − ( f ( x i ) − f ( x j ))) 2 4 σ 2 dx (14) Applying the sp ecific form of p ( x i ≻ π x j ) in Eq.(14) in to the recursive computation of P ( R ( x j , π ) = r ) in Eq.(10), the Binomial-lik e distribution P ( R ( x j , π ) = r ) are computed. F or the con venience of computing the deriv ation, the Binomial-lik e distribution can be appro ximated by the normal distribution with means n i =1 ,i = j p ( x i ≻ π x j ) and v ariance n i =1 ,i = j p ( x i ≻ π x j )(1 − p ( x i ≻ π x j )). 4.3.2 Exp ectations Ob jective functions in explicit metho ds mentioned in section 2.2 can b e expressed as the sum of difference functions, such as ERR in Eq.(6), RBP in Eq.(7) and NDCG in Eq.(5). Incorp orating P ( R ( x j , π ) = r ) into these ob jectives, the expectation of them can b e eas- ily obtained by taking the exp ectation of the differ- ence functions v ( · , · ) ov er the rank distribution, de- noted as ERR s , RBP s and NDCG s . The general form E v s ( π , Y ) and these three measures are listed b elow. E v s ( π , Y ) = n j =1 n − 1 r =0 v ( y i , r ) P ( R ( x j , π ) = r ) , ERR s ( π , Y ) = n j =1 n − 1 r =0 P (users stop at r ) P ( R ( x j , π ) = r ) r + 1 , RBP s ( π , Y ) = (1 − p ) n j =1 n − 1 r =0 y j p r P ( R ( x j , π ) = r ) , NDCG s ( π ,Y ) = n j =1 n − 1 r =0 g ( y j ) D (1 + r ) P ( R ( x j ,π ) = r )) D C G max ( n ) . 4.3.3 F eature-based Learning F ramework The remaining question is ho w to optimize these ex- p ected ob jectiv es in a feature-based learning frame- w ork. Stage I is to design a better feature mapping for item represen tation; Stage I I is the learning pro- cess of the sup ervised St.Agg, i.e. St.Agg F . Stage I: F e atur e mapping. In literature, feature map- ping techniques for rank aggregation can b e classified in to three groups in terms of information used in the feature extraction pro cess. (1) F e atur es in terms of user-item r elation. Borda Coun t is such a natural feature, whic h aims to as- sign an item a relev ance score p er ranking input ac- cording to its p osition in this ranking input only . F or example nB C ( x i , τ i ) = n − τ i ( x i ) n , so Ψ B F ( i ) = [ nB C ( x i , τ 1 ) , · · · , nB C ( x i , τ m )]. (2) F e atur es in terms of b oth user-item and item-item r elations. Maksims et al. (V olko vs et al., 2012) pro- p osed a transformation from all the ranking inputs in to latent feature representations for each item based on SVD factorization. Eac h ranking input τ i can b e transformed into a pairwise preference based ma- trix denoted as P i . Eac h matrix P i can be appro xi- mated by rank- p singular vector decomp osition P i ≈ U i Σ i V ′ i . Therefore, each item x i can be represen ted as a SVD-based feature v ector from m ranking in- puts, Ψ M F ( i ) = [ U 1 ( i, :) , diag (Σ 1 ) , V 1 ( i, :) , · · · , U m ( i, : ) , diag (Σ m ) , V m ( i, :)]. (3) F e atur es in terms of al l of the thr e e r elations. T ensor factorization method can take the item-item, item-user, user-user relations into consideration (Hong et al., 2012). In this pap er, we use CanDe- comp/P arafac (CP) decomp osition (Kolda & Bader, 2009) for tensor factorization due to the nice prop ert y that it has a unique solution of decomp osition, which pro vides a theoretical guarantee to get a stable solu- tion. Sp ecifically , the item-item-user tensor T with T (: , : , i ) = P i is factorized as T = p j =1 λ j U : ,j V : ,j W : ,j . Therefore CP-based feature v ector for item x i is rep- resen ted as Ψ T F ( i ) = [ U ( i, :) , V ( i, :)]. Stage II: Gr adient-b ase d le arning algorithm. Supp ose f is a linear mo del with parameter w . Here w e use gradien t metho d for the optimization of these exp ected ob jectives suc h as ERR s , RBP s and NDCG s . The gradien ts of these exp ected ob jectives are computed as b elo w. n j =1 n − 1 r =0 ∂ E v s ( π , Y ) ∂ P ( R ( x j , π ) = r ) ∂ P ( R ( x j , π ) = r ) ∂ w (15) F or ERR s , RBP s and NDCG s , the only difference of their partial deriv ativ es lies in the first part of deriv a- tiv es in the Eq.(15), which can b e easily deriv ed as follo ws. ∂ ERR s ( π , Y ) ∂ P ( R ( x j , π ) = r ) = P (users stop at r ) r + 1 , ∂ RBP s ( π , Y ) ∂ P ( R ( x j , π ) = r ) = (1 − p ) y j p r , ∂ NDCG s ( π , Y ) ∂ P ( R ( x j , π ) = r ) = g ( y j ) D ( r ) D C G max ( n ) . 5 EXPERIMENTS In this section we compare the p erformance of our ag- gregation metho ds St.Agg with traditional metho ds in terms of ERR, RBP and NDCG on tw o b enc hmark ag- gregation data sets, i.e. MQ2007-agg and MQ2008-agg in LETOR4.0. In unsup ervised scenario, the ground- truth is only used for ev aluation; In sup ervised sce- nario, the ground-truth is employ ed for b oth training and ev aluation. Finally w e mak e a detailed analysis on the robustness of St.Agg. 5.1 EFFECTIVENESS OF UNSUPER VISED ST.AGG As summarised in Section 2, the baseline metho ds fall in to tw o groups in unsup ervised scenario, i.e. the im- plicit group including Marko v Chain based metho ds denoted as MCLK (Dwork et al., 2001), SVP (Gle- ic h & Lim, 2011), MPM (V olko vs & Zemel, 2012) and Plac kett-Luce (Guiv er & Snelson, 2009), and the ex- plicit group including Borda Count (Aslam & Mon- tague, 2001) and RRF (Cormack et al., 2009). W e implemen t tw o unsup ervised St.Agg metho ds includ- ing St.Agg B C and St.Agg RRF . W e use the standard partition in LETOR4.0. F or parameter setting, w e c ho ose the parameters when a metho d reaches its b est p erformance on v alidation set. F or example, parameter C of RRF is set to 40 on MQ2007-agg and 10 on MQ2008-agg. The learning rate is 0.1 and precision is 0.01 for SVP on b oth data sets. The exp erimen tal results are shown in T able 1. Firstly , w e make a comparison b et ween the explicit metho ds and St.Agg in terms of NDCG@5, NDCG@10, ERR and RBP . W e can see that St.Agg B C and St.Agg RRF ha ve obvious adv antage ov er the explicit methods Borda Count and RRF in terms of all the measures. F or example, the highest p erformance impro vemen t of St.Agg B C is 79.7% in terms of NDCG@5 on MQ2007- agg compared with Borda Count. The highest p erfor- mance improv ement of St.Agg RRF is 32.3% in terms of NDCG@5 compared with RRF. Similar results can b e found on MQ2008-agg. It demonstrates that ex- plicit rank aggregation methods can b e significantly impro ved by incorp orating uncertain ty into rank ag- gregation. Secondly , w e mak e a comparison b et ween the im- plicit metho ds and St.Agg in terms of NDCG@5, NDCG@10, ERR and RBP . W e can see that St.Agg is consisten tly b etter even than the b est implicit metho d (MPM). Compared with MPM, St.Agg RRF ac hieves 5.2% higher in terms of NDCG@5 on MQ2007-agg. In terms of NDCG@10, our St.Agg B C p erforms 4.8% b et- ter than the b est implicit metho d (MPM) on MQ2007- agg. Similar results can b e found on the MQ2008-agg. Therefore, we conclude that explicit rank aggregation metho ds can outp erform the implicit metho ds after incorp orating uncertaint y in to rank aggregation. In summary , St.Agg f with exp ected ranking func- tion can improv e the p erformance compared with the explicit methods which utilize rank information di- rectly for aggregation. It also turned out to b e b et- ter than the state-of-art implicit aggregation metho ds on b oth data sets in terms of all the ev aluation mea- sures. Therefore, our proposal to incorp orate uncer- tain ty into rank aggregation, i.e. sto c hastic rank ag- gregation, is significan t for this task. 5.2 EFFECTIVENESS OF SUPER VISED ST.A GG Similarly in sup ervised scenario, our baseline meth- o ds fall in to t wo categories: (1) implicit rank aggre- gation metho ds including CPS (Qin et al., 2010) and θ -MPM (V olko vs & Zemel, 2012); and (2) explicit rank aggregation metho ds including metho ds men tioned in (V olko vs et al., 2012), denoted as RankAgg. Both RankAgg and St.Agg are in a feature-based learning framework. Therefore, it is also a key prob- lem to design a feature mapping for each item. In this pap er, three mappings are adopted: (1) Borda F eature Ψ B F ; (2) SVD-based F eatures Ψ M F ; and (3) CP-based F eatures Ψ T F . RankAgg and St.Agg under these differen t mappings are denoted as RankAgg(Ψ B F ), RankAgg(Ψ M F ), RankAgg(Ψ T F ) and St.Agg(Ψ B F ), St.Agg(Ψ M F ) St.Agg(Ψ T F ), resp ectiv ely . W e use the standard partition in LETOR4.0, and em- T able 1: P erformance Comparison under Unsup ervised Methods on MQ2007-agg and MQ2008-agg. All the results with b old type are significantly b etter than the baseline metho ds ( p -v alue < 0 . 05). (a) MQ2007-agg Metho ds N@5 N@10 ERR RBP BestInput 0.3158 0.3474 0.2476 0.3117 MCLK 0.2098 0.2450 0.1905 0.2798 SVP 0.2582 0.2859 0.2169 0.2941 Plac kett-Luce 0.3462 0.3574 0.2957 0.2999 MPM 0.3986 0.4210 0.3078 0.3229 BordaCoun t 0.2325 0.2637 0.2000 0.2868 RRF 0.3172 0.3474 0.2563 0.3108 St.Agg B C 0.4179 0.4384 0.3197 0.3347 St.Agg RRF 0.4195 0.4404 0.3199 0.3346 (b) MQ2008-agg Metho ds N@5 N@10 ERR RBP BestInput 0.3813 0.1756 0.2391 0.1574 MCLK 0.3402 0.1431 0.2055 0.1449 SVP 0.4004 0.1890 0.2523 0.1606 Plac kett-Luce 0.3737 0.1586 0.2696 0.1485 MPM 0.4283 0.2050 0.3023 0.1628 BordaCoun t 0.4052 0.1895 0.2547 0.1607 RRF 0.4239 0.1931 0.2756 0.1615 St.Agg B C 0.4515 0.2151 0.3021 0.1671 St.Agg RRF 0.4512 0.2157 0.3028 0.1673 1 0.32 0.36 0.40 0.44 0.48 St.Agg ERR St.Agg RBP St.Agg NDCG RankAgg ERR RankAgg RBP CPS RankAgg NDCG θ -MPM Ψ TF Ψ MF Ψ BF Ψ TF Ψ MF Ψ BF (a) NDCG@5 1 0.35 0.40 0.45 0.50 Ψ TF Ψ MF Ψ BF Ψ TF Ψ MF Ψ BF (b) NDCG@10 1 0.24 0.28 0.32 0.36 Ψ TF Ψ MF Ψ BF Ψ TF Ψ MF Ψ BF (c) ERR 1 0.30 0.32 0.34 0.36 Ψ TF Ψ MF Ψ BF Ψ TF Ψ MF Ψ BF (d) RBP Figure 2: P erformance Comparison of Sup ervised Aggregation Metho ds on MQ2007-agg 1 0.40 0.42 0.44 0.46 0.48 0.50 St.Agg ERR St.Agg RBP St.Agg NDCG RankAgg ERR RankAgg RBP CPS RankAgg NDCG θ -MPM Ψ TF Ψ MF Ψ BF Ψ TF Ψ MF Ψ BF (a) NDCG@5 1 0.18 0.19 0.20 0.21 0.22 0.23 Ψ TF Ψ MF Ψ BF Ψ TF Ψ MF Ψ BF (b) NDCG@10 1 0.20 0.24 0.28 0.32 Ψ TF Ψ MF Ψ BF Ψ TF Ψ MF Ψ BF (c) ERR 1 0.145 0.150 0.155 0.160 0.165 0.170 0.175 Ψ TF Ψ MF Ψ BF Ψ TF Ψ MF Ψ BF (d) RBP Figure 3: P erformance Comparison of Sup ervised Aggregation Metho ds on MQ2008-agg plo y fiv e-fold cross v alidation to ev aluate the p erfor- mance of each methods. F or gradient descent pro ce- dure in CPS (Qin et al., 2010), RankAgg (V olko vs et al., 2012) and our St.Agg, learning rate is cho- sen from 10 − 1 to 10 − 6 when the b est performance is ac hieved on the v alidation set with the maximal num- b er of iterations is 500. An additional parameter σ needs to b e tuned from 10 − 1 to 10 − 4 for St.Agg. 5.2.1 Comparison of Aggregation Metho ds W e first compare the p erformances of different meth- o ds, and the exp erimental results are listed in Figure 2 and Figure 3. W e can see that St.Agg outperforms RankAgg consistently in terms of NDCG@10, ERR and RBP under eac h feature mapping ( p -v alue < 0 . 05). F or example in Figure 2 on MQ2007-agg under Ψ M F , the improv ement of St.Agg N DC G o ver RankAgg N DC G is 4.6% in terms of NDCG@10, the impro v ement of St.Agg E RR o ver RankAgg E RR is 7.5% in terms of ERR, and the impro vemen t of St.Agg RB P o ver RankAgg RB P is 7.2% in terms of RBP . Compared with the b est of implicit aggregation meth- o ds ( θ -MPM) in Figure 2 on MQ2007-agg, St.Agg p erforms consistently b etter under any feature map- ping ( p -v alue < 0 . 01). Sp ecifically , the improv ement of St.Agg N DC G (Ψ M F ) ov er θ -MPM is 6.73% in terms of NDCG@10, the improv emen t of St.Agg E RR (Ψ M F ) o ver θ -MPM is 24.3% in terms of ERR and the im- pro vemen t of St.Agg RB P (Ψ M F ) ov er θ -MPM is 15.5% in terms of RBP . Similar results can be found on MQ2008-agg as sho wn in Figure 3. T o sum up, we can see that our prop osed St.Agg can significan tly outp erform all these baselines in terms of NDCG, ERR and RBP . 5.2.2 F eature Mapping Comparison W e further compare the effectiveness of different fea- ture mappings. F rom the results in Figure 2, we can see that Ψ M F is the b est among all the three mappings on MQ2007-agg ( p -v alue < 0 . 01). F or example, p erfor- mances on Ψ M F are consisten tly b etter than the other t wo mappings Ψ B F and Ψ T F for b oth St.Agg N DC G and RankAgg E RR . In Figure 3, obviously Ψ T F is the b est among all the three mappings on MQ2008-agg ( p - v alue < 0 . 01). F or example, p erformances on Ψ T F are consisten tly b etter than that on Ψ M F and Ψ B F for b oth St.Agg N DC G and RankAgg N DC G . Through ab o v e analysis, Ψ M F is b est on MQ2007-agg and Ψ T F is the b est on MQ2008-agg. Since MQ2008- agg is muc h smaller and noisier than MQ2007-agg, our exp erimen tal results agreed with the previous findings that feature mappings based on tensor factorization will be more robust for sparsity and noise (Kolda & Bader, 2009). 5.3 R OBUSTNESS ANAL YSIS OF ST.AGG It is imp ortan t to consider the robustness of rank ag- gregation methods. Here robustness means that the comparativ e p erformance will change little along with differen t ranking inputs, as defined in (Carterette & P etko v a, 2006). Considering the computational effi- ciency , here we only take unsupervised St.Agg for ex- ample. With the num b er of ranking inputs from 5 to 20 with a step 5, w e randomly choose the ranking in- puts from the whole data sets 20 times. Each p oin t in Figure 4 depicts the av erage NDCG@5 obtained on these 20 results. It is obvious that NDCG@5 of St.Agg k eeps high ab ov e all these explicit and implicit metho ds as the num b er 5 10 15 20 0.16 0.24 0.32 0.40 0.48 BordaCount RRF SVP MCLK St.Agg BC St.Agg RRF N D C G @ 5 Number of Ranking Inputs (a) MQ2007-agg 5 10 15 20 0.25 0.30 0.35 0.40 0.45 0.50 N D C G @ 5 Number of Ranking Inputs (b) MQ2008-agg Figure 4: Robustness Analysis of St.Agg of ranking inputs increases in the data set. Therefore, St.Agg is very robust to the change of ranking inputs b y incorporating uncertaint y in to ranks. In addition, the p erformance of each metho d tends to b e stable with the increase of the num b er of ranking inputs since its v ariance is smaller and smaller. 6 CONCLUSION In this pap er, we prop ose a nov el rank aggregation framew ork to incorp orate uncertaint y to this task, namely sto c hastic rank aggregation (i.e. St.Agg). W e giv e some empirical results and analysis to sho w that unreliable rank information from incomplete ranking inputs will make the approaches directly using rank information fail in practice. T o tackle this prob- lem, w e prop ose to treat rank as a random v ariable and define the distribution by pairwise contests. After that, a nov el rank aggregation framework in b oth un- sup ervised and sup ervised scenario is prop osed, which tak es the exp ectations of traditional ranking functions or ob jective functions for optimization. Finally , our extensiv e exp erimen ts on b enchmark data sets sho w that the proposed St.Agg is better in terms of both effectiv eness and robustness. F or future w ork, it is interesting to inv estigate how to incorp orate uncertain ty to implicit metho ds, and whether there are b etter wa ys to define the rank dis- tribution. Ac knowledgemen ts This research w ork was funded by the National Natural Science F oundation of China under Gran t No. 61232010, No. 61203298, No. 61003166 and No. 60933005, 863 Program of China under Grants No. 2012AA011003, and National Key T echnology R&D Program under Gran t No. 2011BAH11B02, No. 2012BAH39B02, No. 2012BAH39B04. W e also wish to express our thanks to Y aho o!Researc h for pro- viding the Y aho o!Rand dataset to us. References Aslam, J. A., & Mon tague, M. (2001). Mo dels for metasearc h. Pr o c e e dings of the 24th annual interna- tional ACM SIGIR c onfer enc e on R ese ar ch and de- velopment in information r etrieval SIGIR2001 (pp. 276–284). New Orleans, Louisiana, United States: A CM. Carterette, B., & P etko v a, D. (2006). Learning a ranking from pairwise preferences. Pr o c e e dings of the 29th annual international ACM SIGIR c onfer- enc e on R ese ar ch and development in information r etrieval SIGIR2006 (pp. 629–630). Seattle, W ash- ington, USA: A CM. Chap elle, O., Metlzer, D., Zhang, Y., & Grinspan, P . (2009). Expected recipro cal rank for graded rele- v ance. Pr o c e e dings of the 18th A CM international c onfer enc e on Information and know le dge manage- ment CIKM2009 (pp. 621–630). Hong Kong, China. Cormac k, G. V., Clark e, C. L. A., & Buettcher, S. (2009). Reciprocal rank fusion outperforms con- dorcet and individual rank learning metho ds. Pr o- c e e dings of the 32nd international ACM SIGIR c on- fer enc e on R ese ar ch and development in information r etrieval SIGIR2009 (pp. 758–759). New Y ork, NY, USA: A CM. Dw ork, C., Kumar, R., Naor, M., & Siv akumar, D. (2001). Rank aggregation metho ds for the w eb. Pr o c e e dings of the 10th international c onfer enc e on World Wide Web WWW2001 (pp. 613–622). New Y ork, NY, USA: ACM. F arah, M., & V anderp ooten, D. (2007). An out- ranking approach for rank aggregation in informa- tion retriev al. Pr o c e e dings of the 30th international ACM SIGIR c onfer enc e on R ese ar ch and develop- ment in information r etrieval SIGIR2007 (pp. 591– 598). Amsterdam, The Netherlands: A CM. Gleic h, D. F., & Lim, L.-h. (2011). Rank aggrega- tion via n uclear norm minimization. Pr o c e e dings of the 17th ACM SIGKDD international c onfer enc e on Know le dge disc overy and data mining KDD2011 (pp. 60–68). San Diego, California, USA: A CM. Guiv er, J., & Snelson, E. (2009). Bay esian inference for plack ett-luce ranking mo dels. Pr o c e e dings of the 26th A nnual International Confer enc e on Machine L e arning ICML2009 (pp. 377–384). New Y ork, NY, USA: A CM. Hong, L., Bekkerman, R., Adler, J., & Davison, B. D. (2012). Learning to rank so cial up date streams. Pr o- c e e dings of the 35th international ACM SIGIR c on- fer enc e on R ese ar ch and development in information r etrieval SIGIR2012 (pp. 651–660). Portland, Ore- gon, USA: A CM. J¨ arv elin, K., & Kek¨ al¨ ainen, J. (2002). Cumulated gain- based ev aluation of ir techniques. ACM T r ans. Inf. Syst. , 20 , 422–446. Kolda, T. G., & Bader, B. W. (2009). T ensor decom- p ositions and applications. SIAM R ev. , 51 , 455–500. Lebanon, G., & Lafferty , J. D. (2002). Cranking: Com- bining rankings using conditional probability mo d- els on p erm utations. r o c e e dings of the 19th An- nual International Confer enc e on Machine L e arning ICML2002 (pp. 363–370). Liu, Y.-T., Liu, T.-Y., Qin, T., Ma, Z.-M., & Li, H. (2007). Sup ervised rank aggregation. Pr o c e e dings of the 16th international c onfer enc e on World Wide Web WWW2007 (pp. 481–490). New Y ork, NY, USA: A CM. Moffat, A., & Zob el, J. (2008). Rank-biased preci- sion for measurement of retriev al effectiveness. ACM T r ans. Inf. Syst. , 27 , 2:1–2:27. Qin, T., Geng, X., & Liu, T.-Y. (2010). A new probabilistic model for rank aggregation. A d- vanc es in Neur al Information Pr o c essing Systems 23 NIPS2010 (pp. 1948–1956). Th urstone, L. L. (1927). The metho d of paired com- parisons for social v alues. The Journal of Abnormal and So cial Psycholo gy , 21 , 384–400. V olko vs, M. N., Laro c helle, H., & Zemel, R. S. (2012). Learning to rank by aggregating expert preferences. Pr o c e e dings of the 21st A CM international c onfer- enc e on Information and know le dge management CIKM2012 (pp. 843–851). Maui, Haw aii, USA: A CM. V olko vs, M. N., & Zemel, R. S. (2012). A flexible gen- erativ e model for preference aggregation. Pr o c e e d- ings of the 21st international c onfer enc e on World Wide Web WWW2012 (pp. 479–488). New Y ork, NY, USA: A CM. V o orhees, E. M. (2002). The philosoph y of informa- tion retriev al ev aluation. CLEF ’01 (pp. 355–370). Springer-V erlag.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment