Bethe-ADMM for Tree Decomposition based Parallel MAP Inference
We consider the problem of maximum a posteriori (MAP) inference in discrete graphical models. We present a parallel MAP inference algorithm called Bethe-ADMM based on two ideas: tree-decomposition of the graph and the alternating direction method of …
Authors: Qiang Fu, Huahua Wang, Arindam Banerjee
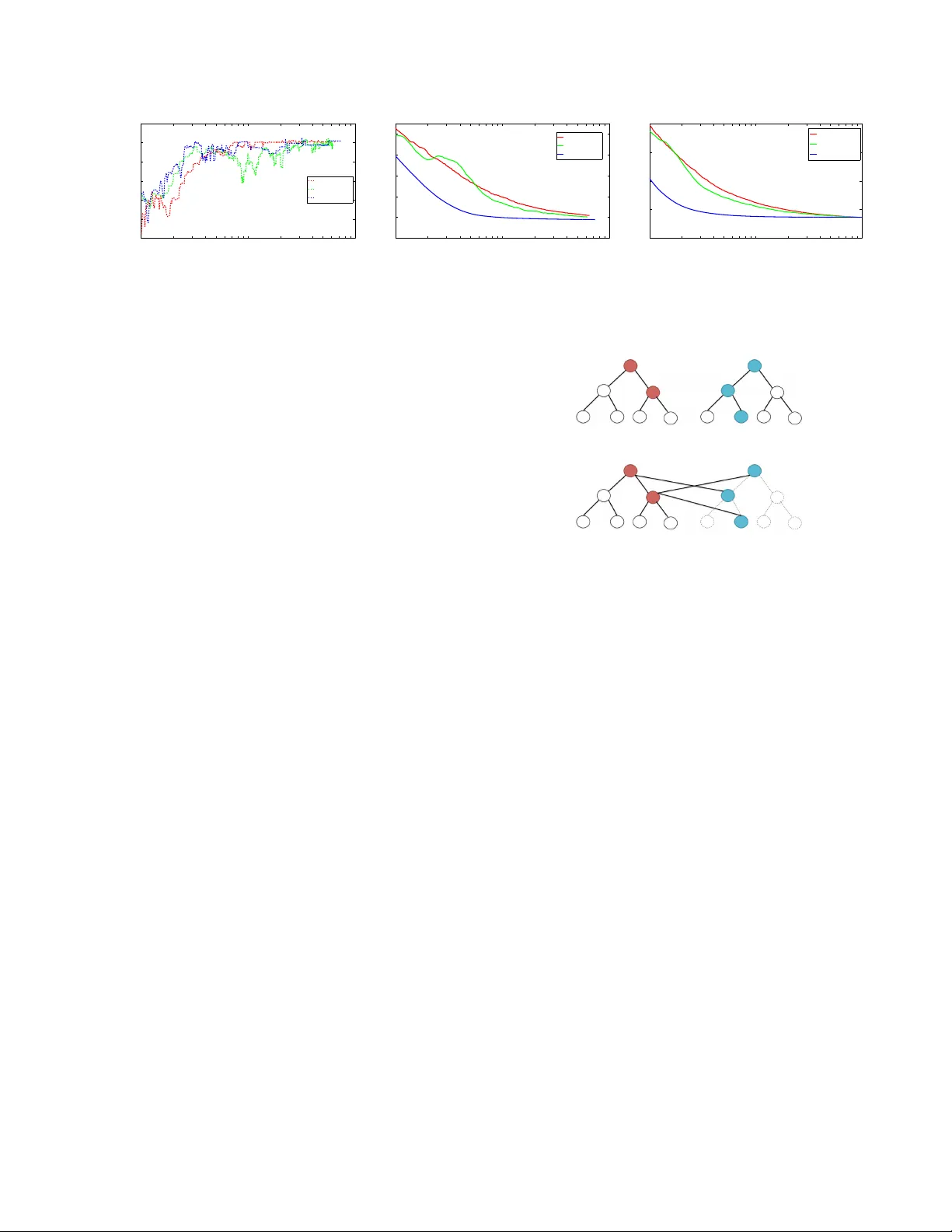
Bethe-ADMM f or T r ee Decomposition based Parallel MAP Infer ence Qiang Fu Huahua W ang Arindam Banerjee Department of Computer Science & Engineering Univ ersity of Minnesota, T win Cities Minneapolis, MN 55455 { qifu, huwang, banerjee } @cs.umn.edu Abstract W e consider the problem of maximum a pos- teriori (MAP) inference in discrete graphical models. W e present a parallel MAP infer- ence algorithm called Bethe-ADMM based on two ideas: tree-decomposition of the graph and the alternating direction method of multi- pliers (ADMM). Ho wev er, unlike the standard ADMM, we use an inexact ADMM augmented with a Bethe-div ergence based proximal func- tion, which makes each subproblem in ADMM easy to solve in parallel using the sum-product algorithm. W e rigorously prove global con ver- gence of Bethe-ADMM. The proposed algorithm is extensi vely ev aluated on both synthetic and real datasets to illustrate its effecti veness. Fur- ther , the parallel Bethe-ADMM is sho wn to scale almost linearly with increasing number of cores. 1 Introduction Giv en a discrete graphical model with kno wn structure and parameters, the problem of finding the most likely config- uration of the states is kno wn as the maximum a posteri- ori (MAP) inference problem [23]. Existing approaches to solving MAP inference problems on graphs with cycles often consider a graph-based linear programming (LP) re- laxation of the integer program [4, 18, 22] . T o solv e the graph-based LP relaxation problem, two main classes of algorithms hav e been proposed. The first class of algorithms are dual LP algorithms [7, 9, 11, 19, 20, 21], which uses the dual decomposition and solves the dual problem. The two main approaches to solving the dual problems are block coordinate descent [7] and sub-gradient algorithms [11]. The coordinate descent algorithms are em- pirically faster , howe ver , they may not reach the dual opti- mum since the dual problem is not strictly conv ex. Recent advances in coordinate descent algorithms perform tree- block updates [20, 21]. The sub-gradient methods, which are guaranteed to conv erge to the global optimum, can be slow in practice. For a detailed discussion on dual MAP algorithms, we refer the readers to [19]. The second class of algorithms are primal LP algorithms like the proximal algorithm [18]. The advantage of such algorithms is that it can choose different Bregman div ergences as proximal functions which can take the graph structure into account. Howe ver , the proximal algorithms do not have a closed form update at each iteration in general and thus lead to double-loop algorithms. As solving MAP inference in large scale graphical mod- els is becoming increasingly important, in recent work, parallel MAP inference algorithms [14, 15] based on the alternating direction method of multipliers (ADMM) [1] hav e been proposed. As a primal-dual algorithm, ADMM combines the advantage of dual decomposition and the method of multipliers, which is guaranteed to con ver ge globally and at a rate of O (1 /T ) ev en for non-smooth prob- lems [24]. ADMM has also been successfully used to solve large scale problem in a distrib uted manner [1]. Design of ef ficient parallel algorithms based on ADMM by problem decomposition has to consider a key tradeoff be- tween the number of subproblems and the size of each sub- problem. Having sev eral simple subproblems makes solv- ing each problem easy , but one has to maintain numerous dual variables to achieve consensus. On the other hand, having a fe w subproblems makes the number of constraints small, but each subproblem needs an elaborate often iter- ativ e algorithm, yielding a double-loop. Existing ADMM based algorithms for MAP inference [14, 15] decompose the problem into se veral simple subproblems, often based on single edges or local factors, so that the subproblems are easy to solve. Howe ver , to enforce consensus among the shared variables, such methods have to use dual v ari- ables proportional to the number of edges or local factors, which can make con vergence slo w on large graphs. T o o vercome the limitations of existing ADMM methods for MAP inference, we propose a novel parallel algorithm based on tree decomposition. The indi vidual trees need not be spanning and thus includes both edge decompo- sition and spanning tree decomposition as special cases. Compared to edge decomposition, tree decomposition has the flexibility of increasing the size of subproblems and reducing the number of subproblems by considering the graph structure. Compared to the tree block coordinate de- scent [20], which works with one tree at a time, our algo- rithm updates all trees in parallel. Note that the tree block coordinate descent algorithm in [21] updates disjoint trees within a forest in parallel, whereas our updates consider ov erlapping trees in parallel. Howe ver , tree decomposition raises a new problem: the subproblems cannot be solved efficiently in the ADMM framew ork and requires an iterati ve algorithm, yielding a double-loop algorithm [14, 18]. T o efficiently solve the subproblem on a tree, we propose a nov el inexact ADMM algorithm called Bethe-ADMM, which uses a Bregman di- ver gence induced by Bethe entropy on a tree, instead of the standard quadratic diver gence, as the proximal func- tion. The resulting subproblems on each tree can be solved exactly in linear time using the sum-product algo- rithm [12]. Howe ver , the proof of conv ergence for the standard ADMM does not apply to Bethe-ADMM. W e prov e global con ver gence of Bethe-ADMM and establish a O (1 /T ) con vergence rate, which is the same as the stan- dard ADMM [8, 24]. Overall, Bethe-ADMM overcomes the limitations of existing ADMM based MAP inference algorithms [14, 15] and provides the flexibility required in designing efficient parallel algorithm through: (i) T ree de- composition, which can take the graph structure into ac- count and greatly reduce the number of variables participat- ing in the consensus and (ii) the Bethe-ADMM algorithm, which yields efficient updates for each subproblem. W e compare the performance of Bethe-ADMM with exist- ing methods on both synthetic and real datasets and illus- trate four aspects. First, Bethe-ADMM is faster than exist- ing primal LP methods in terms of con vergence. Second, Bethe-ADMM is competitiv e with existing dual methods in terms of quality of solutions obtained. Third, in cer- tain graphs, tree decomposition leads to faster con ver gence than edge decomposition for Bethe-ADMM. Forth, parallel Bethe-ADMM, based on Open MPI, gets substantial speed- ups over sequential Bethe-ADMM. In particular, we show almost linear speed-ups with increasing number of cores on a graph with sev eral million nodes. The rest of the paper is organized as follows: W e re view the MAP inference problem in Section 2. In Section 3, we introduce the Bethe-ADMM algorithm and pro ve its global con vergence. W e discuss empirical ev aluation in Section 4, and conclude in Section 5. 2 Background and Related W ork W e first introduce some basic background on Mark ov Ran- dom Fields (MRFs). Then we briefly revie w existing ADMM based MAP inference algorithms in the literature. W e mainly focus on pairwise MRFs and the discussions can be easily carried ov er to MRFs with general factors. 2.1 Problem Definition A pairwise MRF is defined on an undirected graph G = ( V , E ) , where V is the vertex set and E is the edge set. Each node u ∈ V has a random v ariable X u associated with it, which can take value x u in some discrete space X = { 1 , . . . , k } . Concatenating all the random variables X u , ∀ u ∈ V , we obtain an n dimensional random vector X = { X u | u ∈ V } ∈ X n . W e assume that the distribution P of X is a Marko v Random Field [23], meaning that it factors according to the structure of the undirected graph G as follows: With f u : X 7→ R , ∀ u ∈ V and f uv : X × X 7→ R , ∀ ( u, v ) ∈ E denoting nodewise and edge wise poten- tial functions respectiv ely , the distribution takes the form P ( x ) ∝ exp n P u ∈ V f u ( x u ) + P ( u,v ) ∈ E f uv ( x u , x v ) o . An important problem in the context of MRF is that of max- imum a posteriori (MAP) inference, which is the follo wing integer programming (IP) problem: x ∗ ∈ argmax x ∈X n X u ∈ V f u ( x u ) + X ( u,v ) ∈ E f uv ( x u , x v ) . (1) The comple xity of (1) depends critically on the structure of the underlying graph. When G is a tree structured graph, the MAP inference problem can be solved ef ficiently via the max-product algorithm [12]. Howe ver , for an arbitrary graph G , the MAP inference algorithm is usually compu- tationally intractable. The intractability moti vates the de- velopment of algorithms to solve the MAP inference prob- lem approximately . In this paper , we focus on the linear programming (LP) relaxation method [4, 22]. The LP re- laxation of MAP inference problem is defined on a set of pseudomarginals µ u and µ uv , which are non-ne gativ e, nor - malized and locally consistent [4, 22]: µ u ( x u ) ≥ 0 , ∀ u ∈ V , X x u ∈X u µ u ( x u ) = 1 , ∀ u ∈ V , µ uv ( x u , x v ) ≥ 0 , ∀ ( u, v ) ∈ E , X x u ∈X u µ uv ( x u , x v ) = µ v ( x v ) , ∀ ( u, v ) ∈ E . (2) W e denote the polytope defined by (2) as L ( G ) . The LP relaxation of MAP inference problem (1) becomes solving the following LP: max µ ∈ L ( G ) h µ , f i . (3) If the solution µ to (3) is an integer solution, it is guaran- teed to be the optimal solution of (1). Otherwise, one can apply rounding schemes [17, 18] to round the fractional so- lution to an integer solution. 2.2 ADMM based MAP Inference Algorithms In recent years, ADMM [14, 15] has been used to solve large scale MAP inference problems. T o solve (3) using ADMM, we need to split nodes or/and edges and introduce equality constraints to enforce consensus among the shared variables. The algorithm in [14] adopts edge decomposi- tion and introduces equality constraints for shared nodes. Let d i be the degree of node i . The number of equality constraints in [14] is O ( P | V | i =1 d i k ) , which is approximately equal to O ( | E | k ) . For binary pairwise MRFs, the subprob- lems for the ADMM in [14] have closed-form solutions. For multi-v alued MRFs, howe ver , one has to first binarize the MRFs which introduces additional | V | k v ariables for nodes and 2 | E | k 2 variables for edges. The binarization process increases the number of factors to O ( | V | + 2 | E | k ) and the complexity of solving each subproblem increases to O ( | E | k 2 log k ) . W e note that in a recent work [13], the ac- tiv e set method is employed to solve the quadratic problem for arbitrary factors. A generalized variant of [14] which does not require binarization is presented in [15]. W e refer to this algorithm as Primal ADMM and use it as a baseline in Section 4. Although each subproblem in primal ADMM can be efficiently solved, the number of equality constraints and dual v ariables is O (2 | E | k + | E | k 2 ) . In [15], ADMM is also used to solve the dual of (1). W e refer to this algorithm as the Dual ADMM algorithm and use it as a baseline in Section 4. The dual ADMM works for multi-v alued MRFs and has a linear time algorithm for each subproblem, but the number of equality constraint is O (2 | E | k + | E | k 2 ) . 3 Algorithm and Analysis W e first sho w how to solv e (3) using ADMM based on tree decomposition. The resulting algorithm can be a double- loop algorithm since some updates do not ha ve closed form solutions. W e then introduce the Bethe-ADMM algorithm where ev ery subproblem can be solved exactly and effi- ciently , and analyze its con vergence properties. 3.1 ADMM for MAP Infer ence W e first show ho w to decompose (3) into a series of subproblems. W e can decompose the graph G into ov erlapping subgraphs and rewrite the optimization prob- lem with consensus constraints to enforce the pseudo- marginals on subgraphs (local variables) to agree with µ (global variable). Throughout the paper, we focus on tree-structured decompositions. T o be more specific, let T = { ( V 1 , E 1 ) , . . . , ( V | T | , E | T | ) } be a collection of sub- graphs of G which satisfies two criteria: (i) Each subgraph τ = ( V τ , E τ ) is a tree-structured graph and (ii) Each node u ∈ V and each edge ( u, v ) ∈ E is included in at least one subgraph τ ∈ T . W e also introduce local v ariable m τ ∈ L ( τ ) which is the pseudomarginal [4, 22] defined on each subgraph τ . W e use θ τ to denote the potentials on subgraph τ . W e denote µ τ as the components of global variable µ that belong to subgraph τ . Note that since µ ∈ L ( G ) and τ is a tree-structured subgraph of G , µ τ always lies in L ( τ ) . In the newly formulated optimization problem, we will impose consensus constraints for shared nodes and edges. For the ease of exposition, we simply use the equality constraint µ τ = m τ to enforce the consensus. The new optimization problem we formulate based on graph decomposition is then as follows: min m τ , µ | T | X τ =1 ρ τ h m τ , θ τ i (4) subject to m τ − µ τ = 0 , τ = 1 , . . . , | T | (5) m τ ∈ L ( τ ) , τ = 1 , . . . , | T | (6) where ρ τ is a positive constant associated with each sub- graph. W e use the consensus constraints (5) to make sure that the pseudomarginals agree with each other in the shared components across all the tree-structured subgraphs. Besides the consensus constraints, we also impose feasibil- ity constraints (6) , which guarantee that, for each subgraph, the local v ariable m τ lies in L ( τ ) . When the constraints (5) and (6) are satisfied, the global variable µ is guaranteed to lie in L ( G ) . T o make sure that problem (3) and (4)-(6) are equi valent, we also need to guarantee that min m τ | T | X τ =1 ρ τ h m τ , θ τ i = max µ h µ , f i , (7) assuming the constraints (5) and (6) are satisfied. It is easy to verify that, as long as (7) is satisfied, the specific choice of ρ τ and θ τ do not change the problem. Let 1 [ . ] be a binary indicator function and l = − f . For any positive ρ τ , ∀ τ ∈ T , e.g., ρ τ = 1 , a simple approach to obtaining the potential θ τ can be: θ τ ,u ( x u ) = l u ( x u ) P τ 0 ρ τ 0 1 [ u ∈ V τ 0 ] , u ∈ V τ , θ τ ,uv ( x u , x v ) = l uv ( x u , x v ) P τ 0 ρ τ 0 1 [( u, v ) ∈ E τ 0 ] , ( u, v ) ∈ E ( τ ) . Let λ τ be the dual variable and β > 0 be the penalty pa- rameter . The follo wing updates constitute a single iteration of the ADMM [1]: m t +1 τ = argmin m τ ∈ L ( τ ) h m τ , ρ τ θ τ + λ t τ i + β 2 || m τ − µ t τ || 2 2 , (8) µ t +1 = argmin µ | T | X τ =1 −h µ τ , λ t τ i + β 2 || m t +1 τ − µ τ || 2 2 , (9) λ t +1 τ = λ t τ + β ( m t +1 τ − µ t +1 τ ) . (10) In the tree based ADMM (8)-(10), the equality constraints are only required for shared nodes and edges. Assume there are m shared nodes and the shared node v i has C v i copies and there are n shared edges and the shared edge e j has C e j copies. The total number of equality constraints is O ( P m i =1 C v i k + P n j =1 C e j k 2 ) . A special case of tree de- composition is edge decomposition, where only nodes are shared. In edge decomposition, n = 0 and the number of equality constraints is O ( P m i =1 C v i k ) , which is approxi- mately equal to O ( | E | k ) and similar to [14]. In general, the number of shared nodes and edges in tree decomposition is much smaller than that in edge decomposition. The smaller number of equality constraints usually lead to faster con- ver gence in achieving consensus. Now , the problem turns to whether the updates (8) and (9) can be solv ed ef ficiently , which we analyze below: Updating µ : Since we have an unconstrained optimiza- tion problem (9) and the objecti ve function decomposes component-wisely , taking the deriv atives and setting them to zero yield the solution. In particular , let S u be the set of subgraphs which contain node u , for the node components, we hav e: µ t +1 u ( x u ) = 1 | S u | β X τ ∈ S u β m t +1 τ ,u ( x u ) + λ t τ ,u ( x u ) . (11) (11) can be further simplified by observing that P τ ∈ S u λ t τ ,u ( x u ) = 0 [1]: µ t +1 u ( x u ) = 1 | S u | T X τ =1 m t +1 τ ,u ( x u ) . (12) Let S uv be the subgraphs which contain edge ( u, v ) . The update for the edge components can be similarly derived as: µ t +1 u,v ( x u , x v ) = 1 | S uv | X τ ∈ S uv m t +1 τ ,uv ( x u , x v ) . (13) Updating m τ : For (8), we need to solve a quadratic op- timization problem for each tree-structured subgraph. Un- fortunately , we do not have a close-form solution for (8) in general. One possible approach, similar to the proximal algorithm, is to first obtain the solution ˜ m τ to the uncon- strained problem of (8) and then project ˜ m τ to L ( τ ) : m τ = argmin m ∈ L ( τ ) || m − ˜ m τ || 2 2 . (14) If we adopt the cyclic Bregman projection algorithm [2] to solve (14), the algorithm becomes a double-loop algorithm, i.e., the cyclic projection algorithm projects the solution to each individual constraint of L ( τ ) until conv ergence and the projection algorithm itself is iterativ e. W e refer to this algorithm as the Exact ADMM and use it as a baseline in Section 4. 3.2 Bethe-ADMM Instead of solving (8) exactly , a common way in inexact ADMMs [10, 25] is to linearize the objecti ve function in (8), i.e., the first order T aylor expansion at m t τ , and add a new quadratic penalty term such that m t +1 τ = argmin m τ ∈ L ( τ ) h y t τ , m τ − m t τ i + α 2 k m τ − m t τ k 2 2 , (15) where α is a positiv e constant and y t τ = ρ τ θ τ + λ t τ + β ( m t τ − µ t τ ) . (16) Howe ver , as discussed in the pre vious section, the quadratic problem (15) is generally dif ficult for a tree-structured graph and thus the conv entional inexact ADMM does not lead to an efficient update for m τ . By taking the tree struc- ture into account, we propose an ine xact minimization of (8) augmented with a Bregman div ergence induced by the Bethe entropy . W e show that the resulting proximal prob- lem can be solved exactly and efficiently using the sum- product algorithm [12]. W e prov e that the global conv er- gence of the Bethe-ADMM algorithm in Section 3.3. The basic idea in the new algorithm is that we replace the quadratic term in (15) with a Bre gman-div ergence term d φ ( m τ || m t τ ) such that m t +1 τ = argmin m τ ∈ L ( τ ) h y t τ , m τ − m t τ i + αd φ ( m τ || m t τ ) , (17) is efficient to solv e for any tree τ . Expanding the Bregman div ergence and removing the constants, we can re write (17) as m t +1 τ = argmin m τ ∈ L ( τ ) h y t τ /α − ∇ φ ( m t τ ) , m τ i + φ ( m τ ) . (18) For a tree-structured problem, what conv ex function φ ( m τ ) should we choose? Recall that m τ defines the marginal distributions of a tree-structured distrib ution p m τ ov er the nodes and edges: m τ ,u ( x u ) = X ¬ x u p m τ ( x 1 , . . . , x u , . . . , x n ) , ∀ u ∈ V τ , m τ ,uv ( x u , x v ) = X ¬ x u , ¬ x v p m τ ( x 1 ,. . .,x u , x v , . . .,x n ) , ∀ ( uv ) ∈ E τ . It is well known that the sum-product algorithm [12] ef fi- ciently computes the marginal distrib utions for a tree struc- tured graph. It can also be shown that the sum-product al- gorithm solves the follo wing optimization problem [23] for tree τ for some constant η τ : max m τ ∈ L ( τ ) h m τ , η τ i + H B ethe ( m τ ) , (19) where H B ethe ( m τ ) is the Bethe entropy of m τ defined as: H B ethe ( m τ ) = X u ∈ V τ H u ( m τ ,u ) − X ( u,v ) ∈ E τ I uv ( m τ ,uv ) , (20) where H u ( m τ ,u ) is the entropy function on each node u ∈ V τ and I uv ( m τ ,uv ) is the mutual information on each edge ( u, v ) ∈ E τ . Combing (18) and (19), we set η τ = ∇ φ ( m t τ ) − y t τ /α and choose φ to be the ne gativ e Bethe entropy of m τ so that (18) can be solved ef ficiently in linear time via the sum- product algorithm. For the sake of completeness, we summarize the Bethe- ADMM algorithm as follows : m t +1 τ = argmin m τ ∈ L ( τ ) h y t τ /α − ∇ φ ( m t τ ) , m τ i + φ ( m τ ) , (21) µ t +1 = argmin µ T X τ =1 −h λ t τ , µ τ i + β 2 || m t +1 τ − µ τ || 2 2 , (22) λ t +1 τ = λ t τ + β ( m t +1 τ − µ t +1 τ ) , (23) where y t τ is defined in (16) and − φ is defined in (20). 3.3 Con vergence W e prove the global con vergence of the Bethe-ADMM al- gorithm. W e first bound the Bregman di vergence d φ : Lemma 1 Let µ τ and ν τ be two concatenated vectors of the pseudomarginals on a tr ee τ with n τ nodes. Let d φ ( µ τ || ν τ ) be the Bre gman diver gence induced by the neg- ative Bethe entr opy φ . Assuming α ≥ max τ { β (2 n τ − 1) 2 } , we have αd φ ( µ τ || ν τ ) ≥ β 2 k µ τ − ν τ k 2 2 . (24) Pr oof: Let P τ ( x ) be a tree-structured distribution on a tree τ = ( V τ , E τ ) , where | V τ | = n τ and | E τ | = n τ − 1 . The pseudomarginal µ τ has a total of 2 n τ − 1 components, each being a marginal distribution. In particular, there are n τ marginal distributions corresponding to each node u ∈ V τ , giv en by µ τ ,u ( x u ) = X ¬ x u P τ ( x 1 , . . . , x u , . . . , x n ) . (25) Thus, µ u is the marginal probability for node u . Further , there are n τ − 1 marginal components correspond- ing to each edge ( u, v ) ∈ E τ , giv en by µ τ ,uv ( x u , x v ) = X ¬ ( x u ,x v ) P ( x 1 , . . . , x u , . . . , x v , . . . , x n ) . (26) Thus, µ uv is the marginal probability for nodes ( u, v ) . Let µ τ , ν τ be two pseudomarginals defined on tree τ and P µ τ , P ν τ be the corresponding tree-structured distri- butions. Making use of (25), we have k P µ τ − P ν τ k 1 ≥ k µ τ ,u − ν τ ,u k 1 , ∀ u ∈ V τ . (27) Similarly , for each edge, we have the following inequality because of (26) k P µ τ − P ν τ k 1 ≥ k µ τ ,uv − ν τ ,uv k 1 , ∀ ( u, v ) ∈ E τ . (28) Adding them together giv es (2 n τ − 1) k P µ τ − P ν τ k 1 ≥ k µ τ − ν τ k 1 ≥ k µ τ − ν τ k 2 . (29) According to Pinsker’ s inequality [3], we hav e d φ ( µ τ || ν τ ) = K L ( P µ τ , P ν τ ) ≥ 1 2 k P µ τ − P ν τ k 2 1 ≥ 1 2(2 n τ − 1) 2 k µ τ − ν τ k 2 2 . (30) Multiplying α on both sides and letting α ≥ β (2 n τ − 1) 2 complete the proof. T o prov e the con ver gence of the objective function, we de- fine a residual term R t +1 τ as R t +1 τ = ρ τ h m t +1 τ − µ ∗ τ , θ τ i , (31) where µ ∗ τ is the optimal solution for tree τ . W e sho w that R t +1 τ satisfies the following inequality: Lemma 2 Let { m τ , µ τ , λ τ } be the sequences generated by Bethe-ADMM. Assume α ≥ max τ { β (2 n τ − 1) 2 } . F or any µ ∗ τ ∈ L ( τ ) , we have R t +1 τ ≤ h λ t τ , µ ∗ τ − m t +1 τ i + α d φ ( µ ∗ τ || m t τ ) − d φ ( µ ∗ τ || m t +1 τ ) + β 2 k µ ∗ τ − µ t τ k 2 2 − k µ ∗ τ − m t τ k 2 2 − k m t +1 τ − µ t τ k 2 2 , (32) wher e R t +1 τ is defined in (31). Pr oof: Since m t +1 τ is the optimal solution for (21), for any µ ∗ τ ∈ L ( τ ) , we have the follo wing inequality: h y t r + α ( ∇ φ ( m t +1 τ ) − ∇ φ ( m t τ )) , µ ∗ τ − m t +1 τ i ≥ 0 . (33) Substituting (16) into (33) and rearranging the terms, we hav e R t +1 τ ≤ h λ t τ , µ ∗ τ − m t +1 τ i + β h m t τ − µ t τ , µ ∗ τ − m t +1 τ i + α h∇ φ ( m t +1 τ ) − ∇ φ ( m t τ ) , µ ∗ τ − m t +1 τ i . (34) The second term in the RHS of (34) is equiv alent to 2 h m t τ − µ t τ , µ ∗ τ − m t +1 τ i = k m t τ − m t +1 τ k 2 2 + k µ ∗ τ − µ t τ k 2 2 − k µ ∗ τ − m t τ k 2 2 − k m t +1 τ − µ t τ k 2 2 . (35) The third term in the RHS of (34) can be rewritten as h∇ φ ( m t +1 τ ) − ∇ φ ( m t τ ) , µ ∗ τ − m t +1 τ i = d φ ( µ ∗ τ || m t τ ) − d φ ( µ ∗ τ || m t +1 τ ) − d φ ( m t +1 τ || m t τ ) . (36) Substituting (35) and (36) into (34) and using Lemma 1 complete the proof. W e next show that the first term in the RHS of (32) satisfies the following result: 1 5 10 50 100 200 0 1000 2000 3000 4000 5000 6000 Time(seconds) Integer Objective Value Bethe−ADMM Exact ADMM Primal ADMM Proximal (a) Rounded solution with a = 0 . 5 . 1 5 10 50 100 200 0 500 1000 1500 2000 Time (seconds) Relative Error Bethe−ADMM Exact ADMM Primal ADMM Proximal (b) Relati ve error with a = 0 . 5 . 1 5 10 50 100 200 0 500 1000 1500 2000 2500 3000 Time (seconds) Relative Error Bethe−ADMM Exact ADMM Primal ADMM Dual ADMM (c) Relati ve error with a = 1 . Figure 1: Results of Bethe-ADMM, Exact ADMM, Primal ADMM and proximal algorithms on two simulation datasets. Figure 1(a) plots the value of the decoded inte ger solution as a function of runtime (seconds). Figure 1(b) and 1(c) plot the relative error with respect to the optimal LP objective as a function of runtime (seconds). For Bethe-ADMM, we set α = β = 0 . 05 . For Exact ADMM, we set β = 0 . 05 . For Primal ADMM, we set β = 0 . 5 . Bethe-ADMM conv erges faster than other primal based algorithms. Lemma 3 Let { m τ , µ τ , λ τ } be the sequences generated by Bethe-ADMM. F or any µ ∗ τ ∈ L ( τ ) , we have | T | X τ =1 h λ t τ , µ ∗ τ − m t +1 τ i ≤ 1 2 β ( k λ t τ k 2 2 − k λ t +1 τ k 2 2 ) + β 2 k µ ∗ τ − m t +1 τ k 2 2 − k µ ∗ τ − µ t +1 τ k 2 2 . Pr oof: Let µ i be the i th component of µ . W e augment µ τ , m τ and λ τ in the follo wing way: If µ i is not a compo- nent of µ τ , we set µ τ ,i = 0 , m τ ,i = 0 and λ τ ,i = 0 ; other - wise, the y are the corresponding components from µ τ , m τ and λ τ respectiv ely . W e can then re write (22) in the fol- lowing equi valent component-wise form: µ t +1 i = argmin µ i | T | X τ =1 h λ t τ ,i , m t +1 τ ,i − µ τ ,i i + β 2 || m t +1 τ ,i − µ τ ,i || 2 2 . For an y µ ∗ τ ∈ L ( τ ) , we have the follo wing optimality con- dition: − | T | X τ =1 h λ t τ ,i + β ( m t +1 τ ,i − µ t +1 τ ,i ) , µ ∗ τ ,i − µ t +1 τ ,i i ≥ 0 . (37) Combining all the components of µ t +1 , we can rewrite (37) in the following v ector form: − | T | X τ =1 h λ t τ + β ( m t +1 τ − µ t +1 τ ) , µ ∗ τ − µ t +1 τ i ≥ 0 . (38) Rearranging the terms yields | T | X τ =1 h λ t τ , µ ∗ τ − m t +1 τ i ≤ | T | X τ =1 h λ t τ , µ t +1 τ − m t +1 τ i − | T | X τ =1 β h m t +1 τ − µ t +1 τ , µ ∗ τ − µ t +1 τ i = | T | X τ =1 h λ t τ , µ t +1 τ − m t +1 τ i + β 2 | T | X τ =1 k µ ∗ τ − m t +1 τ k 2 2 −k µ ∗ τ − µ t +1 τ k 2 2 − k µ t +1 τ − m t +1 τ k 2 2 . (39) Recall µ t +1 τ − m t +1 τ = 1 β ( λ t τ − λ t +1 τ ) in (23), then h λ t τ , µ t +1 τ − m t +1 τ i − β 2 k µ t +1 τ − m t +1 τ k 2 2 = 1 2 β ( k λ t τ k 2 2 −k λ t +1 τ k 2 2 ) . (40) Plugging (40) into (39) completes the proof. W e also need the following lemma which can be found in [6]. W e omit the proof due to lack of space. Lemma 4 Let { m τ , µ τ , λ τ } be the sequences generated by Bethe-ADMM. Then | T | X τ =1 k m t +1 τ − µ t τ k 2 2 ≥ | T | X τ =1 k m t +1 τ − µ t +1 τ k 2 2 + k µ t +1 τ − µ t τ k 2 2 . Theorem 1 Assume the following hold: (1) m 0 τ and µ 0 τ ar e uniform tree-structur ed distributions, ∀ τ = 1 , . . . , | T | (2) λ 0 τ = 0 , ∀ τ = 1 , . . . , | T | ; (3) max τ d φ ( µ ∗ τ || m 0 τ ) = D µ ; (4) α ≥ max τ { β (2 n τ − 1) 2 } holds. Denote ¯ m T τ = 1 T P T − 1 t =0 m t τ and ¯ µ T τ = 1 T P T − 1 t =0 µ t τ . F or any T and the optimal solution µ ∗ , we have | T | X τ =1 ρ τ h ¯ m T τ − µ ∗ τ , θ τ i + β 2 k ¯ m T τ − ¯ µ T τ k 2 2 ≤ D µ α | T | T . Pr oof: Summing (32) ov er τ from 1 to | T | and using Lemma 3, we hav e: | T | X τ =1 R t +1 τ + β 2 k m t +1 τ − µ t τ k 2 2 ≤ | T | X τ =1 1 2 β ( k λ t τ k 2 2 − k λ t +1 τ k 2 2 ) + β 2 k µ ∗ τ − µ t τ k 2 2 − k µ ∗ τ − µ t +1 τ k 2 2 + β 2 k µ ∗ τ − m t +1 τ k 2 2 − k µ ∗ τ − m t τ k 2 2 + α d φ ( µ ∗ τ || m t τ ) − d φ ( µ ∗ τ || m t +1 τ ) . (41) Summing ov er the above from t = 0 to T − 1 , we hav e T − 1 X t =0 | T | X τ =1 R t +1 τ + β 2 k m t +1 τ − µ t τ k 2 2 ≤ | T | X τ =1 1 2 β ( k λ 0 τ k 2 2 − k λ T τ k 2 2 ) + β 2 k µ ∗ τ − µ 0 τ k 2 2 − k µ ∗ τ − µ T τ k 2 2 + β 2 k µ ∗ τ − m T τ k 2 2 − k µ ∗ τ − m 0 τ k 2 2 + α d φ ( µ ∗ τ || m 0 τ ) − d φ ( µ ∗ τ || m T τ ) ≤ | T | X τ =1 β 2 k µ ∗ τ − m T τ k 2 2 + α d φ ( µ ∗ τ || m 0 τ ) − d φ ( µ ∗ τ || m T τ ) ≤ | T | X τ =1 αd φ ( µ ∗ τ || m 0 τ ) , (42) where we use Lemma 1 to deriv e (42). Applying Lemma 4 and Jensen’ s inequality yield the desired bound. Theorem 1 establishes the O (1 /T ) conv ergence rate for the Bethe-ADMM in ergodic sense. As T → ∞ , the ob- jectiv e value P | T | τ =1 ρ τ h ¯ m T τ , θ τ i con verges to the optimal value and the equality constraints are also satisfied. 3.4 Extension to MRFs with General Factors Although we present Bethe-ADMM in the context of pair- wise MRFs, it can be easily generalized to handle MRFs with general factors. For a general MRF , we can vie w the dependency graph as a factor graph [12], a bipar- tite graph G = ( V ∪ F , E ) , where V and F are dis- joint set of variable nodes and factor nodes and E is a set of edges, each connecting a variable node and a fac- tor node. The distrib ution P ( x ) takes the form: P ( x ) ∝ exp P u ∈ V f u ( x u ) + P α ∈ F f α ( x α ) . The relaxed LP for general MRFs can be constructed in a similar fashion with that for pairwise MRFs. W e can then decompose the relaxed LP to subproblems de- fined on factor trees and impose equality constraints to en- force consistenc y on the shared variables among the sub- problems. Each subproblem can be solved efficiently using the sum-product algorithm for factor trees and the Bethe- ADMM algorithm for general MRFs bears similar structure with that for pairwise MRFs. 4 Experimental Results W e compare the Bethe-ADMM algorithm with several other state-of-the-art MAP inference algorithms. W e show the comparison results with primal based MAP inference algorithms in Section 4.1 and dual based MAP inference algorithm in Section 4.2 respectiv ely . W e also show in Sec- tion 4.3 how tree decomposition benefits the performance 100 1000 10000 100000 430 435 440 445 450 455 460 465 470 Time (seconds) Dual Objective Value Bethe−ADMM MPLP Figure 2: Both Bethe-ADMM and MPLP are run for sufficiently long, i.e., 50000 iterations. The dual objectiv e value is plotted as a function of runtime (seconds). The MPLP algorithm gets stuck and does not reach the global optimum. of Bethe-ADMM. W e run experiments in Section 4.1-4.3 using sequential updates. T o illustrate the scalability of our algorithm, we run parallel Bethe-ADMM on a multicore machine and show the linear speedup in Section 4.4. 4.1 Comparison with Primal based Algorithms W e compare the Bethe-ADMM algorithm with the prox- imal algorithm [18], Exact ADMM algorithm and Pri- mal ADMM algorithm [15]. For the proximal algorithm, we choose the Bregman di vergence as the sum of KL- div ergences across all node and edge distributions. Follow- ing the methodology in [18], we terminate the inner loop if the maximum constraint violation of L ( G ) is less than 10 − 3 and set w t = t . Similarly , in applying the Exact ADMM algorithm, we terminate the loop for solving m τ if the maximum constraint violation of L ( τ ) is less than 10 − 3 . For the Exact ADMM and Bethe-ADMM algorithm, we use ‘edge decomposition’: each τ is simply an edge of the graph and | T | = | E | . T o obtain the inte ger solution, we use node-based rounding: x ∗ u = argmax x u µ u ( x u ) . W e show experimental results on two synthetic datasets. The underlying graph of each dataset is a three dimensional m × n × t grid. W e generate the potentials as follows: W e set the nodewise potentials as random numbers from [ − a, a ] , where a > 0 . W e set the edgewise potentials according to the Potts model, i.e., θ uv ( x u , x v ) = b uv if x u = x v and 0 otherwise. W e choose b uv randomly from [ − 1 , 1] . The edgewise potentials penalize disagreement if b uv > 0 and penalize agreement if b uv < 0 . W e generate datasets using m = 20 , n = 20 , t = 16 , k = 6 with v arying a . Figure 1(a) shows the plots of (1) on one synthetic dataset and we find that the algorithms have similar performances on other simulation datasets. W e observe that all algo- rithms conv erge to the optimal value h µ ∗ , f i of (3) and we plot the relativ e error with respect to the optimal value |h µ ∗ − µ t , f i| on the two datasets in Figure 1(b) and 1(c). Overall, the Bethe-ADMM algorithm conv erges faster than other primal algorithms. W e observe that the proximal algorithm and Exact ADMM algorithm are the slowest, due to the sequential projection step. In terms of the de- coded inte ger solution, the Bethe-ADMM, Exact ADMM and proximal algorithm hav e similar performances. W e 10 100 1000 −400 −300 −200 −100 0 100 200 Time (seconds) Integer Objective Value Bethe−ADMM Dual ADMM MPLP (a) Rounded inte ger solution on 1jo8. 10 100 1000 120 140 160 180 200 220 Time (seconds) Dual Objective Value Bethe−ADMM Dual ADMM MPLP (b) Dual v alue on 1jo8. 100 1000 10000 400 450 500 550 600 Time (seconds) Dual Objective Value Bethe−ADMM Dual ADMM MPLP (c) Dual v alue on 1or7. Figure 3: Results of Bethe-ADMM, MPLP and Dual ADMM algorithms on two protein design datasets. Figure 3(a) plots the the value of the decoded integer solution as a function of runtime (seconds). Figure 3(b) and 3(c) plot the dual value as a function of runtime (seconds). For Dual ADMM, we set β = 0 . 05 . For Bethe-ADMM, we set α = β = 0 . 1 . Bethe-ADMM and Dual ADMM hav e similar performance in terms of con ver gence. All three methods hav e comparable performances for the decoded integer solution. also note that a higher objective function value does not necessarily lead to a better decoded integer solution. 4.2 Comparison with Dual based Algorithms In this section, we compare the Bethe-ADMM algorithm with the MPLP algorithm [7] and the Dual ADMM al- gorithm [15]. W e conduct experiments on protein design problems [26]. In these problems, we are gi ven a 3D struc- ture and the goal is to find a sequence of amino-acids that is the most stable for that structure. The problems are mod- eled by nodewise and pairwise factors and can be posed as finding a MAP assignment for the given model. This is a demanding setting in which each problem may hav e hun- dreds of variables with 100 possible states on a verage. W e run the algorithms on two problems with dif ferent sizes [26], i.e., 1jo8 (58 nodes and 981 edges) and 1or7 (180 nodes and 3005 edges). For the MPLP and Dual ADMM algorithm, we plot the value of the integer programming problem (1) and its dual.. For Bethe-ADMM algorithm, we plot the value of dual LP of (3) and the integer pro- gramming problem (1). Note that although Bethe-ADMM and Dual ADMM hav e different duals, their optimal val- ues are the same. W e run the Bethe-ADMM based on edge decomposition. Figure 3 shows the result. W e observe that the MPLP algorithm usually con verges faster , but since it is a coordinate ascent algorithm, it can stop prematurely and yield suboptimal solutions. Figure 2 shows that on the 1fpo dataset, the MPLP algorithm con- ver ges to a suboptimal solution. W e note that the conv er- gence time of the Bethe-ADM and Dual ADM are similar . The three algorithms have similar performance in terms of the decoded integer solution. 4.3 Edge based vs T r ee based In the pre vious experiments, we use ‘edge decomposition’ for the Bethe-ADMM algorithm. Since our algorithm can work for an y tree-structured graph decomposition, we want to empirically study how the decomposition affects the per- formance of the Bethe-ADMM algorithm. In the follo w- ing experiments, we sho w that if we can utilize the graph (a) (b) Figure 4: A simulation dataset with m = 2 , s = 7 and n = 3 . In 4(a), the red nodes ( S 12 ) are sampled from tree 1 and the blue nodes ( D 12 ) are sampled from tree 2. In 4(b) , sampled nodes are connected by cross-tree edges ( E 12 ). T ree 1 with nodes in D 12 and edges in E 12 still form a tree, denoted by solid lines. This augmented tree is a tree-structured subgraph for Bethe-ADMM. structure when decomposing the graph, the Bethe-ADMM algorithm will ha ve better performance compared to simply using ‘edge decomposition’, which does not take the graph structure into account. W e conduct experiments on synthetic datasets. W e gen- erate MRFs whose dependency graphs consist of sev eral tree-structured graphs and cross-tree edges to introduce cy- cles. T o be more specific, we first generate m binary tree structured MRFs each with s nodes. Then for each ordered pair of tree-structured MRFs ( i, j ) , 1 ≤ i, j ≤ m, i 6 = j , we uniformly sample n nodes from MRF i with replace- ment and uniformly sample n ( n ≤ s ) nodes from MRF j without replacement, resulting in two node sets S ij and D ij . W e then connect the nodes in S ij and D ij , denoting them as E ij . W e repeat this process for ev ery pair of trees. By construction, the graph consisting of tree i , nodes in D ij and edges in E ij , ∀ j 6 = i is still a tree. W e will use these m augmented trees as the tree-structured subgraphs for the Bethe-ADMM algorithm. Figure 4 illustrates the graph generation and tree decomposition process. A sim- ple calculation sho ws that for this particular tree decompo- sition, O ( m 2 nk ) equality constraints are maintained, while for edge decomposition, O ( msk + m 2 nk ) are maintained. When the graph has dominant tree structure, tree decompo- sition leads to much less number of equality constraints. 0 1 2 3 4 5 6 7 8 9 0 0.2 0.4 0.6 0.8 1 Time (seconds) Maximum Constraint Violation Tree Decomposition Edge Decomposition (a) s = 1023 . 0 5 10 15 20 25 30 35 40 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Time (seconds) Maximum Constraints Violation Tree Decomposition Edge Decomposition (b) s = 4095 . 0 20 40 60 80 100 120 140 160 180 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Time (seconds) Maximum Constraint Violation Tree Decomposition Edge Decomposition (c) s = 16383 . Figure 5: Results of Bethe-ADMM algorithms based on tree and edge decomposition on three simulation datasets with m = 10 , n = 20 . The maximum constraint violation in L ( G ) is plotted as a function of runtime (seconds). For both algorithms, we set α = β = 0 . 05 . The tree based Bethe-ADMM algorithm has better performance than that of the edge based Bethe-ADMM when the tree structure is more dominant in G . For the experiments, we run the Bethe-ADMM algorithm based on tree and edge decomposition with different values of s , keeping m and n fixed. It is easy to see that the tree structure becomes more dominant when s becomes larger . Since we observe that both algorithms first conv erge to the optimal value of (3) and then the equality constraints are gradually satisfied, we ev aluate the performance by com- puting the maximum constraint violation of L ( G ) at each iteration for both algorithms. The faster the constraints are satisfied, the better the algorithm is. The results are shown in Figure 5. When the tree structure is not obvious, the two algorithms have similar performances. As we increase s and the tree structure becomes more dominant, the differ - ence between the two algorithms is more pronounced. W e attribute the superior performance to the fact that for the tree decomposition case, much fewer number of equality constraints are imposed and each subproblem on tree can be solved ef ficiently using the sum-product algorithm. 4.4 Scalability Experiments on Multicores The dataset used in this section is the Climate Research Unit (CR U) precipitation dataset [16], which has monthly precipitation from the years 1901-2006. The dataset is of high gridded spatial resolution (360 × 720, i.e., 0.5 degree latitude × 0.5 de gree longitude) and includes the precipita- tion ov er land. Our goal is to detect major droughts based on precipita- tion. W e formulate the problem as the one of estimating the most likely configuration of a binary MRF , where each node represents a location. The underlying graph is a three dimensional grid (360 × 720 × 106) with 7,146,520 nodes and each node can be in two possible states: dry and nor- mal. W e run the Bethe-ADMM algorithm on the CR U dataset and detect droughts based on the integer solution after node-based rounding. For the details of the this e x- periment, we refer to readers to [5]. Our algorithm suc- cessfully detects nearly all the major droughts of the last century . W e also examine how the Bethe-ADMM algo- rithm scales on the CRU dataset with more than 7 million variables. W e run the Open MPI code with different num- 1 2 3 4 5 6 7 8 9 10 0 2000 4000 6000 8000 10000 Number of cores Runtime (seconds) Figure 6: The Open MPI implementation of Bethe-ADMM has almost linear speedup on the CR U dataset with more than 7 mil- lion nodes. ber of cores and the result in Figure 6 sho ws that we obtain almost linear speedup with the number of cores. 5 Conclusions W e propose a prov ably con ver gent MAP inference algo- rithm for large scale MRFs. The algorithm is based on the ‘tree decomposition’ idea from the MAP inference liter- ature and the alternating direction method from the opti- mization literature. Our algorithm solves the tree structured subproblems efficiently via the sum-product algorithm and is inherently parallel. The empirical results show that the new algorithm, in its sequential version, compares fav or- ably to other existing approximate MAP inference algo- rithm in terms of running time and accuracy . The exper - imental results on lar ge datasets demonstrate that the paral- lel version scales almost linearly with the number of cores in the multi-core setting. Acknowledgements This research was supported in part by NSF CAREER Grant IIS-0953274, and NSF Grants IIS-1029711, IIS- 0916750, and IIS-0812183. The authors would like to thank Stefan Liess and Peter K. Snyder for the helpful dis- cussion on the CRU experiment. The authors are grateful for the technical support from the Univ ersity of Minnesota Supercomputing Institute (MSI). References [1] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein. Dis- tributed optimization and statistical learning via the alternat- ing direction method of multipliers. F oundations and T rends in Machine Learning , 3(1):1–122, 2011. [2] Y . Censor and S. Zenios. P arallel Optimization: Theory , Al- gorithms, and Applications . Oxford Univ ersity Press, 1998. [3] N. Cesa-Bianchi and G. Lugosi. Prediction, Learning, and Games . Cambridge University Press, 2006. [4] C. Chekuri, S. Khanna, J. Naor, and L. Zosin. A linear programming formulation and approximation algorithms for the metric labeling problem. SIAM Journal on Discr ete Mathematics , 18(3):608–625, Mar . 2005. [5] Q. Fu, A. Banerjee, S. Liess, and P . K. Snyder . Drought detection of the last century: An MRF-based approach. In Pr oceedings of the SIAM International Confer ence on Data Mining , 2012. [6] Q. Fu, H. W ang, A. Banerjee, S. Liess, and P . K. Sny- der . MAP inference on million node graphical models: KL-div ergence based alternating directions method. T echni- cal report, Computer Science and Engineering Department, Univ ersity of Minesota, 2012. [7] A. Globerson and T . Jaakkola. Fixing max-product: Conv er- gent message passing algorithms for MAP LP-relaxations. In Pr oceedings of the T wenty-F irst Annual Confer ence on Neural Information Pr ocessing Systems , 2007. [8] B. He and X. Y uan. On the O (1 /n ) con ver gence rate of the Douglas-Rachford alternating direction method. SIAM Journal on Numerical Analysis , 50(2):700–709, 2012. [9] V . Jojic, S. Gould, and D. K oller . Fast and smooth: Acceler- ated dual decomposition for MAP inference. In Pr oceedings of the twenty-Seventh International Confer ence on Machine Learning , 2010. [10] S. P . Kasivisw anathan, P . Melville, A. Banerjee, and V . Sind- hwani. Emerging topic detection using dictionary learning. In Pr oceedings of the T wentieth ACM international confer- ence on Information and knowledge manag ement , 2011. [11] N. Komodakis, N. Paragios, and G. Tziritas. MRF energy minimization and beyond via dual decomposition. IEEE T ransactions on P attern Analysis and Machine Intelligence , 33(3):531 –552, march 2011. [12] F . R. Kschischang, B. J. Frey , and H. A. Loeliger . Factor graphs and the sum-product algorithm. IEEE T ransactions on Information Theory , 47(2):498–519, 2001. [13] A. F . Martins. The Geometry of Constrained Structur ed Pr e- diction: Applications to Infer ence and Learning of Natural Language Syntax . PhD thesis, Carnegie Mellon Univ ersity , 2012. [14] A. F . Martins, P . M. Aguiar , M. A. Figueiredo, N. A. Smith, and E. P . Xing. An augmented Lagrangian ap- proach to constrained MAP inference. In Pr oceedings of the T wenty-Eighth International Confer ence on Machine Learn- ing , 2011. [15] O. Meshi and A. Globerson. An alternating direction method for dual MAP LP relaxation. In Proceedings of the Eur opean Conference on Machine Learning and Principles and Practice of Knowledge Disco very in Databases , 2011. [16] T . D. Mitchell, T . R. Carter , P . D. Jones, M. Hulme, and M. New . A compr ehensive set of high-r esolution grids of monthly climate for Eur ope and the globe: the observed r ecor d (1901-2000) and 16 scenarios (2001-2100) . T yndall Centre for Climate Change Research, 2004. [17] P . Raghav an and C. D. Thompson. Randomized rounding: A technique for prov ably good algorithms and algorithmic proofs. Combinatorica , 7(4):365–374, 1987. [18] P . Ra vikumar , A. Agarwal, and M. J. W ainwright. Message- passing for graph-structured linear programs: Proximal methods and rounding schemes. Journal of Machine Learn- ing Resear ch , 11:1043–1080, 2010. [19] D. Sontag, A. Globerson, and T . Jaakkola. Introduction to dual decomposition for inference. In S. Sra, S. Nowozin, and S. J. Wright, editors, Optimization for Machine Learning . MIT Press, 2011. [20] D. Sontag and T . Jaakkola. T ree block coordinate descent for MAP in graphical models. In Pr oceedings of the T welfth In- ternational Confer ence on Artificial Intelligence and Statis- tics . [21] D. T arlo w , D. Batra, P . K ohli, and V . K olmogorov . Dy- namic tree block coordinate ascent. In Pr oceedings of the T wenty-Eighth International Confer ence on Machine Learn- ing , 2011. [22] M. J. W ainwright, T . S. Jaakkola, and A. S. W illsky . MAP estimation via agreement on (hyper)trees: Message-passing and linear-programming approaches. IEEE T ransactions of Information Theory , 51(11):3697–3717, 2005. [23] M. J. W ainwright and M. I. Jordan. Graphical models, expo- nential families, and v ariational inference. F oundations and T rends in Mac hine Learning , 1(1-2):1–305, 2008. [24] H. W ang and A. Banerjee. Online alternating direction method. In Pr oceedings of the T wenty-Ninth International Confer ence on Machine Learning , 2012. [25] J. Y ang and Y . Zhang. Alternating direction algorithms for l1-problems in compressiv e sensing. SIAM Journal on Sci- entific Computing , 33(1):250–278, 2011. [26] C. Y anover , T . Meltzer, and Y . W eiss. Linear programming relaxations and belief propagation: an empirical study . Jour- mal of Machine Learning Resear ch , 7:1887–1907, 2006.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment