Learning Stable Multilevel Dictionaries for Sparse Representations
Sparse representations using learned dictionaries are being increasingly used with success in several data processing and machine learning applications. The availability of abundant training data necessitates the development of efficient, robust and provably good dictionary learning algorithms. Algorithmic stability and generalization are desirable characteristics for dictionary learning algorithms that aim to build global dictionaries which can efficiently model any test data similar to the training samples. In this paper, we propose an algorithm to learn dictionaries for sparse representations from large scale data, and prove that the proposed learning algorithm is stable and generalizable asymptotically. The algorithm employs a 1-D subspace clustering procedure, the K-hyperline clustering, in order to learn a hierarchical dictionary with multiple levels. We also propose an information-theoretic scheme to estimate the number of atoms needed in each level of learning and develop an ensemble approach to learn robust dictionaries. Using the proposed dictionaries, the sparse code for novel test data can be computed using a low-complexity pursuit procedure. We demonstrate the stability and generalization characteristics of the proposed algorithm using simulations. We also evaluate the utility of the multilevel dictionaries in compressed recovery and subspace learning applications.
💡 Research Summary
**
The paper introduces a novel multilevel dictionary (MLD) learning framework designed for large‑scale data and provides rigorous theoretical guarantees of algorithmic stability and generalization. The core idea is to use K‑hyperline clustering—a 1‑dimensional subspace clustering method—as a building block at each level of a hierarchical dictionary. At the first level, K₁ atoms (unit‑norm vectors) are learned by fitting K‑hyperlines to the entire training set. Each training sample is then approximated by the atom with the largest absolute inner product, and the residual (the difference between the sample and its projection onto that atom) becomes the input for the next level. This process repeats for L levels, yielding a set of sub‑dictionaries {Ψ₁,…,Ψ_L}.
A key contribution is the use of the Minimum Description Length (MDL) principle to automatically determine the number of atoms Kₗ at each level. The MDL cost balances the bits required to encode the data given the dictionary (the sparse codes) against the bits needed to encode the dictionary itself. This prevents over‑fitting and leads to an “energy hierarchy”: early levels capture high‑energy geometric structures, while later levels model lower‑energy stochastic textures.
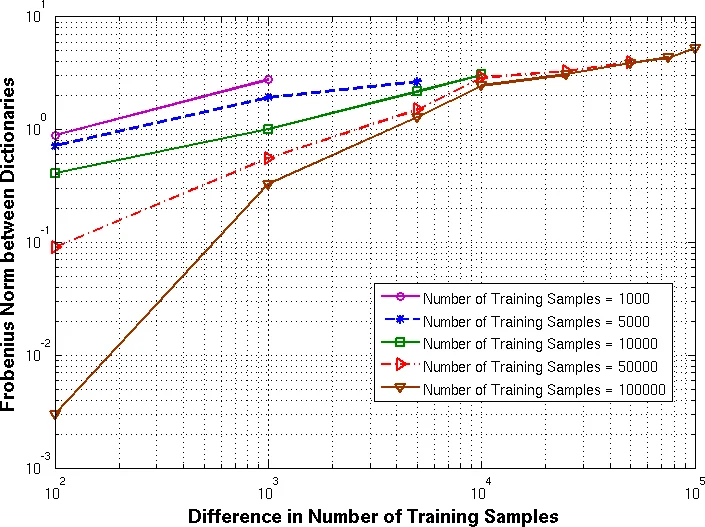
The authors prove stability by showing that K‑hyperline clustering belongs to a uniform Donsker class, which implies that the empirical distortion uniformly converges to its expectation. Consequently, for any two i.i.d. training sets drawn from the same distribution, the dictionaries learned from them converge in L₁(P) distance as the number of samples T → ∞. When the clustering objective has a unique minimizer, convergence holds even for completely disjoint training sets; if multiple minimizers exist, convergence still holds provided the difference between the two training sets is o(√T), while a difference of Ω(√T) can cause instability.
Generalization is established by bounding the gap between empirical risk and expected risk at O(1/√T), extending earlier results on sparse coding to the multilevel setting. Because each level solves an independent clustering problem, the overall sample complexity does not explode with the total number of atoms.
For inference, the authors propose Multilevel Pursuit (MulP), a low‑complexity greedy algorithm. At each level, the algorithm selects the atom with maximal absolute correlation, assigns a coefficient of one, and updates the residual for the next level. The total computational cost scales linearly with the sum of atoms across levels, making it suitable for real‑time applications.
To improve robustness when training data are scarce, an ensemble approach is introduced: multiple MLD models are trained on different random subsets of the data, and their sparse codes are combined (e.g., by averaging) during testing. This reduces variance and yields more stable performance.
Experimental validation covers four aspects: (1) empirical verification of stability and generalization by measuring dictionary distances across different training sets; (2) compressed sensing recovery where MLD+MulP outperforms online K‑SVD and L₁‑minimization by 1–2 dB PSNR at 10–30 % measurement rates, especially under noisy conditions; (3) noise robustness, showing superior reconstruction quality at low SNR; and (4) subspace learning, where graphs constructed from MLD sparse codes (MLP‑graph) achieve 5–10 % higher classification accuracy than k‑NN graphs or graphs based on conventional dictionaries.
In summary, the paper makes the following contributions: (i) a hierarchical dictionary learning algorithm based on K‑hyperline clustering; (ii) rigorous proofs of asymptotic stability and generalization; (iii) an MDL‑driven model order selection scheme; (iv) an ensemble method for robust dictionary construction; (v) a fast multilevel pursuit algorithm; and (vi) extensive experiments demonstrating advantages in compressed recovery and subspace learning. Limitations include the restriction to 1‑D subspaces, sensitivity of MDL to data distribution, and increased training cost due to ensembling. Future work may explore extensions to higher‑dimensional subspaces, Bayesian information criteria, and model compression techniques such as knowledge distillation.
Comments & Academic Discussion
Loading comments...
Leave a Comment