Learning Sequence Neighbourhood Metrics
Recurrent neural networks (RNNs) in combination with a pooling operator and the neighbourhood components analysis (NCA) objective function are able to detect the characterizing dynamics of sequences and embed them into a fixed-length vector space of arbitrary dimensionality. Subsequently, the resulting features are meaningful and can be used for visualization or nearest neighbour classification in linear time. This kind of metric learning for sequential data enables the use of algorithms tailored towards fixed length vector spaces such as R^n.
💡 Research Summary
The paper “Learning Sequence Neighbourhood Metrics” proposes a novel framework for embedding variable‑length sequential data into a fixed‑dimensional metric space by jointly training a recurrent neural network (RNN) and a neighbourhood components analysis (NCA) loss. The authors argue that many real‑world problems—medical monitoring, robotics, speech, finance—produce time‑ordered data whose dynamics are essential for discrimination, yet most conventional machine‑learning algorithms operate on static vectors. To bridge this gap they combine three ingredients: (1) a powerful sequence model, specifically Long Short‑Term Memory (LSTM) cells, which can capture long‑range dependencies; (2) a differentiable pooling operator (sum, mean or max) that aggregates the entire hidden‑state sequence into a single vector; and (3) the NCA objective, which directly optimizes the geometry of the embedding so that points sharing the same class label become close neighbours while points from different classes are pushed apart.
The technical pipeline works as follows. An input sequence x = (x₁,…,x_T) is fed into an LSTM‑based RNN, producing hidden states h₁,…,h_T. A pooling function p aggregates these hidden states into a fixed‑length embedding e = p(h₁,…,h_T). For a batch of embeddings {e_i} the NCA defines a stochastic neighbour probability p_{ij} = exp(−‖e_i−e_j‖²)/∑{k≠i}exp(−‖e_i−e_k‖²) (with p{ii}=0). The probability that point i is correctly classified is the sum of p_{ij} over all j that share i’s label. The overall loss is the expected number of correctly classified points, i.e. the sum over i of these probabilities. Because every component—RNN, pooling, and NCA—is differentiable, gradients can be back‑propagated through the whole system. The authors implement the model in Theano, using stochastic gradient descent, RPROP, or L‑BFGS to optimize the parameters.
Experiments are conducted on two fronts. First, a suite of 12 univariate time‑series classification benchmarks from the UCR archive is used to evaluate the method against the standard 1‑Nearest‑Neighbour classifier on Discrete Wavelet Transform (1‑NN‑DWT) features. Hyper‑parameters (number of hidden units, pooling type, batch size, data whitening, etc.) are tuned via random search (200 trials per dataset). Results show that the NCA‑LSTM embeddings achieve comparable or superior classification accuracy to 1‑NN‑DWT on most datasets, with particularly strong performance on synthetic control, ECG, and other high‑dimensional series. The authors note that very small training sets relative to the number of model parameters can lead to over‑fitting, which explains occasional failures on datasets with few samples per class.
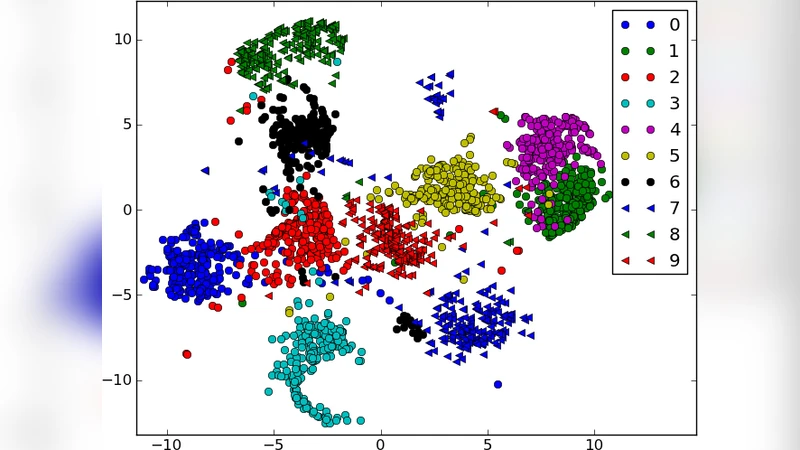
Second, the method is evaluated on the TIDIGITS spoken‑digit benchmark. Audio is pre‑processed into 13‑dimensional MFCC vectors per frame. A network with 40 LSTM units and a 30‑dimensional embedding is trained using the NCA loss. For comparison, an identical LSTM architecture is trained with a conventional cross‑entropy loss. The NCA model attains a test‑set classification probability of 97.9 %, whereas the cross‑entropy model reaches 92.6 %. Visualisation of the learned embeddings with t‑SNE reveals well‑separated clusters for each digit, and interestingly some digits form multiple sub‑clusters, indicating that NCA captures a non‑linear manifold rather than a simple linear separation.
The authors highlight several advantages of their approach: (i) embedding a new sequence requires only a forward pass through the RNN, i.e. O(T) time and memory independent of sequence length; (ii) the resulting embeddings are fixed‑size vectors, enabling the use of any off‑the‑shelf algorithm that expects Euclidean data (k‑NN, SVM, clustering, etc.); (iii) the NCA loss provides a discriminative metric without requiring explicit pairwise distance engineering; and (iv) the framework is agnostic to the underlying recurrent architecture, allowing future extensions with Echo State Networks, multiplicative RNNs, or attention‑based models.
Limitations are also discussed. Computing the NCA loss naïvely scales quadratically with the batch size, which can become a bottleneck for very large datasets. Moreover, when the number of trainable parameters exceeds the number of training examples, the model may over‑fit, as observed on some UCR datasets. The paper suggests future work on approximating NCA (e.g., via sampling or hierarchical softmax) and experimenting with alternative recurrent units to further improve scalability and robustness.
In summary, the paper introduces a clean, end‑to‑end trainable system that maps sequences to a semantically meaningful Euclidean space by marrying recurrent neural networks with neighbourhood‑based metric learning. The empirical results demonstrate that the learned embeddings are both discriminative for classification and useful for visualisation, offering a practical tool for researchers and practitioners dealing with sequential data.
Comments & Academic Discussion
Loading comments...
Leave a Comment