Privacy in Content-Oriented Networking: Threats and Countermeasures
As the Internet struggles to cope with scalability, mobility, and security issues, new network architectures are being proposed to better accommodate the needs of modern systems and applications. In particular, Content-Oriented Networking (CON) has emerged as a promising next-generation Internet architecture: it sets to decouple content from hosts, at the network layer, by naming data rather than hosts. CON comes with a potential for a wide range of benefits, including reduced congestion and improved delivery speed by means of content caching, simpler configuration of network devices, and security at the data level. However, it remains an interesting open question whether or not, and to what extent, this emerging networking paradigm bears new privacy challenges. In this paper, we provide a systematic privacy analysis of CON and the common building blocks among its various architectural instances in order to highlight emerging privacy threats, and analyze a few potential countermeasures. Finally, we present a comparison between CON and today’s Internet in the context of a few privacy concepts, such as, anonymity, censoring, traceability, and confidentiality.
💡 Research Summary
The paper presents a systematic privacy analysis of Content‑Oriented Networking (CON), a next‑generation Internet architecture that routes and retrieves data based on content names rather than host addresses. After outlining the motivations for moving beyond the traditional IP model—namely scalability, mobility, and security—the authors describe the core building blocks of CON: hierarchical or flat naming, name‑based routing tables (FIB), in‑network caching (Content Store), and pending interest tables (PIT) that keep state for each request. Each of these components introduces distinct privacy concerns.
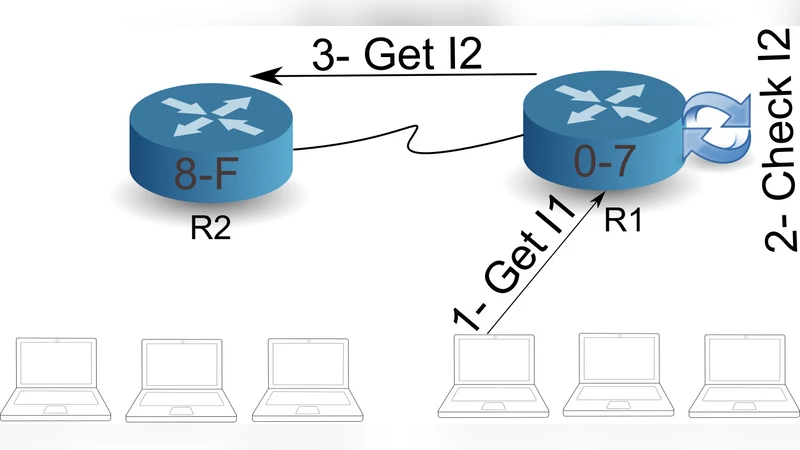
First, the explicit content name carried in every Interest packet can reveal a user’s interests, location, or even identity when observed by a passive adversary. Because names are often human‑readable (e.g., /health/diagnosis/virus‑test), they can be directly linked to sensitive topics. Second, in‑network caches enable “cache‑privacy attacks”: an adversary can probe a router to learn whether a particular name is stored, thereby inferring that some user in the vicinity has requested that content. Third, timing attacks exploit the latency difference between cache hits and misses; by measuring round‑trip times an attacker can deduce whether a user’s request was satisfied from a nearby cache, revealing consumption patterns. Fourth, the PIT maintains per‑request state, which can be exploited to correlate multiple Interests from the same source, undermining anonymity. Fifth, the name‑based routing infrastructure itself can be censored or filtered by blocking specific name prefixes, allowing fine‑grained content suppression that is more precise than IP‑based filtering.
The authors categorize privacy threats along four dimensions: anonymity, censorship resistance, traceability, and confidentiality. They argue that while CON provides data‑level integrity through mandatory signatures, it does not automatically protect the confidentiality of the metadata (names, routing information) that accompanies the data. Consequently, users may lose anonymity, become traceable, or be subject to targeted censorship despite the underlying cryptographic guarantees.
To mitigate these risks, the paper surveys several countermeasures. Name encryption (e.g., hashing, homomorphic encryption) hides the semantic content of names from intermediate routers while still allowing deterministic routing. Privacy‑enhanced caching strategies—such as randomizing cache placement, adding dummy entries, or employing probabilistic eviction—reduce the success probability of cache probing attacks. Private Information Retrieval (PIR) and Oblivious Transfer protocols enable a consumer to retrieve data without revealing the exact name to the network. Multipath forwarding and traffic mixing disperse Interests across multiple routes, making correlation attacks more difficult. Finally, access control lists and authenticated routing can enforce that only authorized entities can request or forward certain name prefixes, limiting the impact of malicious name‑based censorship. The paper evaluates these techniques through simulation, showing trade‑offs between added latency, bandwidth overhead, and privacy gain.
A comparative analysis with today’s IP‑based Internet highlights that CON introduces new privacy attack surfaces (e.g., name leakage, PIT correlation) but also offers novel defenses (e.g., content signatures, cache‑based acceleration). In the anonymity dimension, CON is more vulnerable unless names are obfuscated; in censorship resistance, CON can be more easily filtered but can also employ encrypted names and multipath routing to evade blocks. Traceability is heightened by PIT state, yet can be mitigated by aggressive PIT expiration and anonymizing overlays. Confidentiality of the payload remains strong due to signatures, but metadata confidentiality requires additional encryption layers.
The paper concludes that while CON promises performance and security benefits, privacy cannot be treated as an afterthought. Designing a privacy‑preserving CON demands integrated solutions spanning naming, caching, routing, and access control. Future work should focus on standardizing privacy‑aware naming schemes, developing lightweight PIR mechanisms suitable for high‑throughput networks, and creating user‑friendly privacy configuration tools. Only through such holistic design can CON achieve its full potential without compromising user privacy.