Full-text Support for Publish/Subscribe Ontology Systems
We envision a publish/subscribe ontology system that is able to index millions of user subscriptions and filter them against ontology data that arrive in a streaming fashion. In this work, we propose a SPARQL extension appropriate for a publish/subscribe setting; our extension builds on the natural semantic graph matching of the language and supports the creation of full-text subscriptions. Subsequently, we propose a main-memory subscription indexing algorithm which performs both semantic and full-text matching at low complexity and minimal filtering time. Thus, when ontology data are published matching subscriptions are identified and notifications are forwarded to users.
💡 Research Summary
The paper presents a comprehensive solution for a publish/subscribe ontology system capable of handling millions of continuous queries (subscriptions) and matching them against RDF data streams in real time. The authors address two core challenges: (1) extending SPARQL to support expressive full‑text search within subscriptions, and (2) designing a main‑memory indexing algorithm that can perform both semantic graph matching and full‑text matching efficiently.
SPARQL Extension
To bridge the gap between SPARQL’s graph‑pattern focus and the need for sophisticated text retrieval, the authors introduce a new binary operator ftcontains. A subscription can now contain a clause such as FILTER ftcontains(?articleText, "economic" ftand "crisis"). The operator works only on variables bound to literal objects, and it supports Boolean combinations (ftand, ftor), proximity, and phrase matching. By treating the full‑text condition as an additional filter on the variable, the extension preserves SPARQL’s declarative style while adding powerful text‑search capabilities beyond simple regular expressions.
Indexing Architecture
The indexing solution consists of two complementary structures:
-
Semantic Match Table – Inspired by the iBroker system, this is a two‑level hash table that encodes the join chain of a SPARQL subscription. The first level hashes the subject‑predicate pair, while the second level hashes the object (or constant part). This representation enables rapid traversal of the semantic join sequence when a new RDF triple arrives.
-
Property Hash Table + Tries – For the full‑text component, each constant part of a triple pattern (e.g., the predicate that points to a literal) becomes a key in a property hash table. The value associated with the key is a composite structure: (i) a set of tries that store the keywords appearing in the full‑text part of all subscriptions sharing that property, and (ii) a keyword hash that provides O(1) access to the roots of those tries. By grouping subscriptions with common keyword prefixes into shared trie nodes, memory consumption is dramatically reduced and lookup time is accelerated.
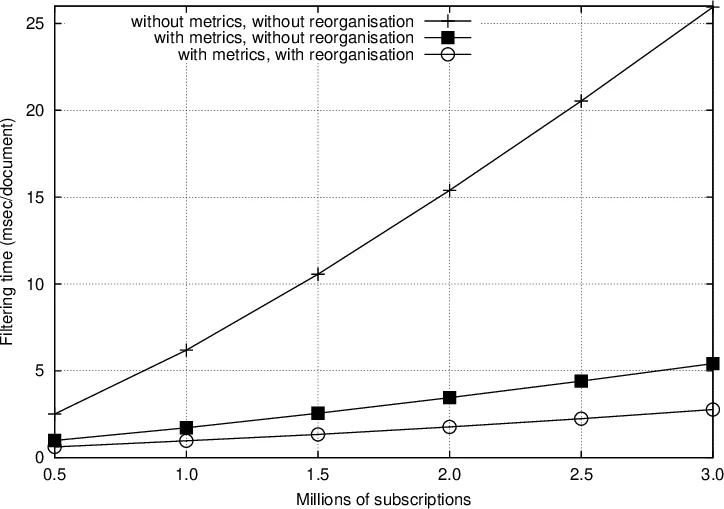
Metrics‑Guided Insertion and Reorganization
When a new subscription is added, the algorithm computes a set of metrics (keyword frequency, subscription length, trie depth, etc.) to decide the optimal insertion point within the forest of tries. Because the insertion process is greedy, the final layout can be sensitive to the order of arrivals. To mitigate this, the system periodically performs a reorganization phase. All subscriptions inserted since the last reorganization are rescored, sorted, and re‑inserted into the trie forest, thereby maximizing common sub‑structures and minimizing traversal depth during filtering.
Experimental Evaluation
The authors evaluate the approach using 3.1 million extended abstracts from DBpedia as a simulated RDF stream and generate synthetic subscription sets ranging from 0.1 million to 5 million entries. Three configurations are compared: (i) deterministic insertion without metrics, (ii) metric‑guided insertion without reorganization, and (iii) metric‑guided insertion with periodic reorganization. Filtering time per document (milliseconds) is measured. Results show that configuration (iii) consistently achieves the lowest filtering latency—often below 0.5 ms per document—demonstrating that the combination of metrics and reorganization yields a near‑linear scaling even with millions of subscriptions. Memory usage remains modest (a few gigabytes) thanks to the trie compression and hash‑based access.
Contributions and Future Work
The paper’s primary contributions are:
- A seamless SPARQL extension (
ftcontains) that brings full‑text Boolean, proximity, and phrase queries into the publish/subscribe paradigm. - A hybrid indexing scheme that unifies semantic graph matching and full‑text matching in main memory, leveraging two‑level hashing and shared tries.
- A dynamic optimization strategy (metrics + periodic reorganization) that preserves low filtering latency despite the greedy nature of trie insertion.
Limitations include the reliance on a purely in‑memory data structure, which may become a bottleneck for truly massive RDF streams (tens of billions of triples) or for distributed deployments. Future research directions suggested by the authors involve extending the system to disk‑based or distributed storage, incorporating ranking or scoring mechanisms into the full‑text operator, and exploring integration with modern language‑model‑based retrieval techniques.
In summary, the work demonstrates that a carefully engineered combination of language extensions and memory‑efficient indexing can enable real‑time, scalable publish/subscribe services for semantic web applications, bridging the gap between graph‑oriented querying and full‑text information retrieval.
Comments & Academic Discussion
Loading comments...
Leave a Comment