Discovering Sequential Patterns in a UK General Practice Database
The wealth of computerised medical information becoming readily available presents the opportunity to examine patterns of illnesses, therapies and responses. These patterns may be able to predict illnesses that a patient is likely to develop, allowing the implementation of preventative actions. In this paper sequential rule mining is applied to a General Practice database to find rules involving a patients age, gender and medical history. By incorporating these rules into current health-care a patient can be highlighted as susceptible to a future illness based on past or current illnesses, gender and year of birth. This knowledge has the ability to greatly improve health-care and reduce health-care costs.
💡 Research Summary
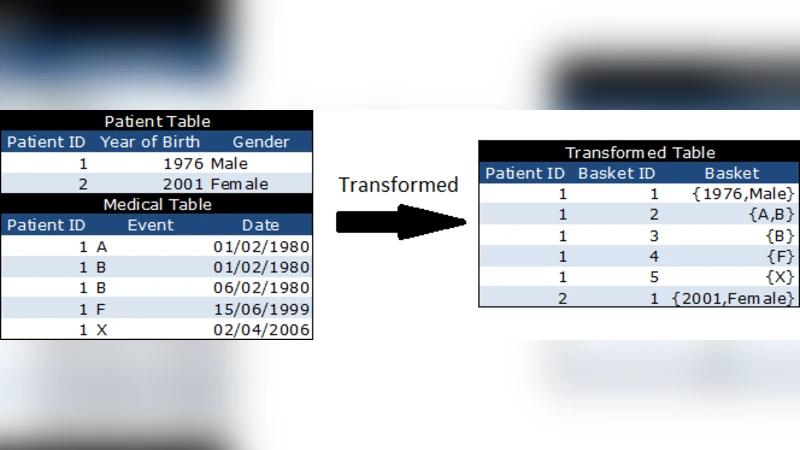
The paper investigates the use of sequential pattern mining to uncover temporal associations among patients’ age, gender, and medical histories within the UK’s THIN (The Health Improvement Network) general practice database. The authors first transform the raw THIN records—comprising roughly 350,000 patients, 25 million prescriptions, and 15 million coded medical events—into a transaction‑style database analogous to retail “basket” data. Each patient’s events occurring on the same calendar day are grouped into a single basket, baskets are ordered chronologically, and the first basket is enriched with the patient’s year of birth (yob) and gender, thereby embedding demographic information directly into the sequential data.
For mining, the study employs SP ADE (Sequential Pattern Discovery using Equivalence Classes), a lattice‑based early‑pruning algorithm that works with vertical projections and position codes. Unlike many traditional sequential mining methods, SP ADE does not require a minimum support threshold, allowing rare items (low‑frequency diagnoses or treatments) to be considered as long as the confidence of the resulting rule exceeds a user‑defined threshold. The authors set this confidence threshold at 0.1 for computational efficiency and applied the cspade function from the R package arulesSequences.
The mining process yielded 97,883 sequential rules. The authors categorize the insights derived from these rules into several themes:
-
Disease Relapse Patterns – Rules of the form A, A → A (e.g., repeated depressive disorder) show increasing confidence with each additional occurrence, quantifying the heightened risk of chronicity after multiple episodes. For instance, a single diagnosis of “Depressive disorder NEC” is followed by a repeat in 34.3 % of cases, while two prior diagnoses raise the repeat probability to 52.7 %.
-
Gender Differences – By comparing rules that include gender in the antecedent with those that do not, the study highlights sex‑specific risk variations. The rule “Essential hypertension, female → Essential hypertension” has a higher confidence than its gender‑agnostic counterpart, suggesting women are more likely to experience hypertension recurrence.
-
Age‑Specific Incidence – Incorporating yob at the start of each sequence enables the extraction of age‑related rules such as “1943 → Essential hypertension” (confidence ≈ 0.117) and “1944 → Essential hypertension” (confidence ≈ 0.110). The difference indicates that patients aged 67 are about 6.4 % more likely than those aged 66 to have developed hypertension, providing a quantitative view of age‑related risk acceleration.
-
Effect of Clinical Interventions – Rules that pair health‑education or monitoring actions with subsequent disease outcomes allow assessment of preventive efficacy. For example, “Health education offered, Essential hypertension → Essential hypertension” has a lower confidence than “Essential hypertension → Essential hypertension,” implying that education may reduce the chance of hypertension relapse.
-
Comorbidity‑Driven Risk – Certain antecedents, such as “Pure hypercholesterolaemia,” “Depression,” “Type 2 diabetes mellitus,” and “Chronic kidney disease stage 3,” each precede “Essential hypertension” in more than 10 % of cases, quantifying known comorbidity relationships.
-
Population Sub‑Group Signals – Some rules reveal less obvious links, such as the association of acute conjunctivitis with young birth years (yob 2000‑2003) and with conditions like infantile eczema or croup, suggesting that age‑related sub‑populations drive certain disease patterns.
The authors acknowledge several limitations. Many patient histories are incomplete because the THIN data only span from 2003 onward; older cohorts (e.g., born before 1942) may have experienced events before the database’s start, leading to missing early‑life rules. Moreover, because most patients are still alive, their sequences are truncated, which can depress support and confidence values for long‑term associations (e.g., A → B where B occurs many years after A). The authors propose that analyses restricted to patients with full birth‑to‑death records, or weighting rules by the temporal gap between antecedent and consequent, could mitigate these biases. Additionally, SP ADE’s inability to generate interval‑based antecedents (e.g., “yob < 1944”) limits the expressiveness of age rules.
In conclusion, the study demonstrates that sequential pattern mining can extract clinically meaningful, quantitative rules from a large primary‑care database, encompassing relapse probabilities, gender and age disparities, and the impact of preventive interventions. These rules have the potential to be integrated into electronic health‑record systems as real‑time alerts, guiding clinicians toward early detection and targeted prevention. Future work is suggested to validate the predictive utility of the discovered rules in prospective settings, to explore more sophisticated temporal modeling (e.g., time‑aware confidence measures), and to assess how such rule‑based alerts affect patient outcomes and healthcare costs.
Comments & Academic Discussion
Loading comments...
Leave a Comment