Approximate Bayesian Image Interpretation using Generative Probabilistic Graphics Programs
The idea of computer vision as the Bayesian inverse problem to computer graphics has a long history and an appealing elegance, but it has proved difficult to directly implement. Instead, most vision tasks are approached via complex bottom-up processi…
Authors: Vikash K. Mansinghka, Tejas D. Kulkarni, Yura N. Perov
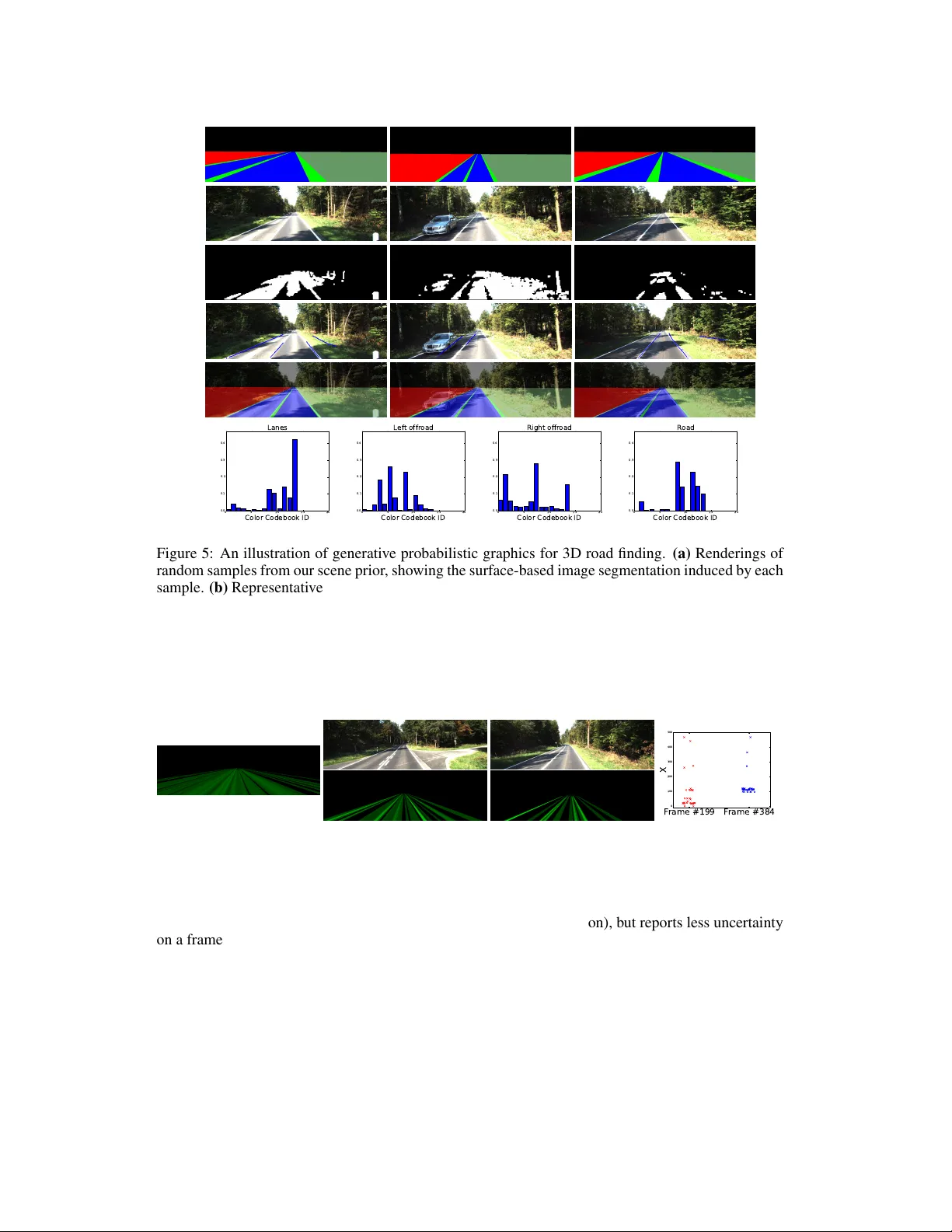
A ppr oximate Bayesian Image Interpr etation using Generativ e Pr obabilistic Graphics Programs V ikash K. Mansinghka ∗ 1,2 , T ejas D. Kulkarni ∗ 1,2 , Y ura N. Perov 1,2,3 , and Joshua B. T enenbaum 1,2 1 Computer Science and Artificial Intelligence Laboratory , MIT 2 Department of Brain and Cognitiv e Sciences, MIT 3 Institute of Mathematics and Computer Science, Siberian Federal Univ ersity Abstract The idea of computer vision as the Bayesian in verse problem to computer graph- ics has a long history and an appealing elegance, but it has proved difficult to di- rectly implement. Instead, most vision tasks are approached via comple x bottom-up processing pipelines. Here we sho w that it is possible to write short, simple prob- abilistic graphics programs that define flexible generative models and to automat- ically inv ert them to interpret real-world images. Generativ e probabilistic graph- ics programs consist of a stochastic scene generator, a renderer based on graphics software, a stochastic likelihood model linking the renderer’ s output and the data, and latent variables that adjust the fidelity of the renderer and the tolerance of the likelihood model. Representations and algorithms from computer graphics, origi- nally designed to produce high-quality images, are instead used as the deterministic backbone for highly approximate and stochastic generati ve models. This formu- lation combines probabilistic programming, computer graphics, and approximate Bayesian computation, and depends only on general-purpose, automatic inference techniques. W e describe two applications: reading sequences of degraded and ad- versarially obscured alphanumeric characters, and inferring 3D road models from vehicle-mounted camera images. Each of the probabilistic graphics programs we present relies on under 20 lines of probabilistic code, and supports accurate, ap- proximately Bayesian inferences about ambiguous real-world images. 1 Introduction Computer vision has historically been formulated as the problem of producing symbolic descriptions of scenes from input images [9]. This is usually done by building bottom-up processing pipelines that isolate the portions of the image associated with each scene element and extract features that are indicativ e of its identity . Many pattern recognition and learning techniques can then be used to build classifiers for individual scene elements, and sometimes to learn the features themselv es [7, 6]. This approach has been remarkably successful, especially on problems of recognition. Bottom-up pipelines that combine image processing and machine learning can identify written characters with high accuracy and recognize objects from large sets of possibilities. Howe ver , the resulting systems typically require large training corpuses to achieve reasonable levels of accurac y , and are difficult both to build and modify . For example, the T esseract system [15] for optical character recognition is ov er 10 , 000 lines of C++. Small changes to the underlying assumptions frequently necessitates end-to-end retraining and/or redesign. * The first two authors contrib uted equally to this work. * (vkm, kulkarni, perov, jbt)@mit.edu 1 Generativ e models for a range of image parsing tasks are also being explored [16, 3, 17, 21, 19]. These provide an appealing av enue for integrating top-down constraints with bottom-up processing, and pro- vide an inspiration for the approach we tak e in this paper . But like traditional bottom-up pipelines for vision, these approaches hav e relied on considerable problem-specific engineering, chiefly to design and/or learn custom inference strategies, such as MCMC proposals [17, 21] that incorporate bottom-up cues. Other combinations of top-down knowledge with bottom up processing have been remarkably powerful. For example, [8] has shown that global, 3D geometric information can significantly improve the performance of bottom-up object detectors. In this paper , we propose a nov el formulation of image interpretation problems, called generativ e prob- abilstic graphics programming (GPGP). Generativ e probabilistic graphics programs share a common template: a stochastic scene generator, an approximate renderer based on existing graphics software, a highly stochastic likelihood model for comparing the renderer’ s output with the observed data, and latent variables that control the fidelity of the renderer and the tolerance of the image likelihood. Our probabilistic graphics programs are written in a variant of the Church probabilistic programming lan- guage [5]. Each model we introduce requires less than 20 lines of probabilistic code. The renderers and likelihoods for each are based on standard templates written as short Python programs. Unlike typical generati ve models for scene parsing, in verting our probabilistic graphics programs requires no custom inference algorithm design. Instead, we rely on the automatic Metropolis-Hastings transition operators provided by our probabilistic programming system. The approximations and stochasticity in our renderer , scene generator and likelihood models serve to implement a variant of approximate Bayesian computation [18, 10]. This combination can produce a kind of self-tuning analogue of an- nealing that facilities reliable con vergence. T o the best of our knowledge, our GPGP framew ork is the first real-world image interpretation formu- lation to combine probabilistic programming, automatic inference, computer graphics, and approx- imate Bayesian computation; this constitutes our main contribution. Our second contribution is to provide demonstrations of the ef ficacy of this approach on two image interpretation problems: read- ing snippets of degraded and adversarially obscured alphanumeric characters, and inferring 3D road models from vehicle mounted cameras. In both cases we quantitatively report the accuracy of our approach on representative test datasets, as compared to standard bottom-up baselines that hav e been extensi vely engineered. 2 Generative Probabilistic Graphics Programs and A pproximate Bayesian Inference. Generativ e probabilistic graphics programs define generativ e models for images by combining four components. The first is a stochastic scene generator written as probabilistic code that makes random choices for the location and configuration of the main elements in the scene. The second is an appr ox- imate r enderer based on existing gr aphics softwar e that maps a scene S and control v ariables X to an image I R = f ( S, X ) . The third is a stochastic likelihood model for image data I D that enables scor- ing of rendered scenes gi ven the control v ariables. The fourth is a set of latent v ariables X that control the fidelity of the renderer and/or the tolerance in the stochastic likelihood model. These components are described schematically in Figure 1. W e formulate image interpretation tasks in terms of sampling (approximately) from the posterior distribution o ver images: P ( S | I D ) ∝ P ( S ) P ( X ) δ f ( S,X ) ( I R ) P ( I D | I R , X ) W e perform inference ov er ex ecution histories of our probabilistic graphics programs using a uniform mixture of generic, single-variable Metropolis-Hastings transitions, without any custom, bottom-up proposals. W e first giv e a general description of the generativ e model and inference algorithm in- duced by our probabilistic graphics programs; in later sections, we describe specific details for each application. Let S = { S i } be a decomposition of the scene S into parts S i with independent priors P ( S i ) . For example, in our te xt application, the S i s include binary indicators for the presence or absence of each glyph, along with its identity (“ A“ through ”Z”, plus digits 0-9), and parameters including location, 2 Stochastic Scene Generator Approximate Renderer Stochastic Comparison S ~ P(S) I R = f(S,X) Data I D X ~ P(X) P(I D |I R ,X) Figure 1: An ov erview of the generati ve probabilistic graphics frame work. Each of our models shares a common template: a stochastic scene generator which samples possible scenes S according to their prior , latent v ariables X that control the fidelity of the rendering and the tolerance of the model, an approximate render f ( S, X ) → I R based on existing graphics software, and a stochastic likelihood model P ( I D | I R , X ) that links observed rendered images. A scene S ∗ sampled from the scene gener- ator according to P ( S ) could be rendered onto a single image I ∗ R . This would be extremely unlikely to exactly match the data I ∗ D . Instead of requiring exact matches, our formulation can broaden the renderer’ s output P ( I R | S ∗ ) and the image likelihood P ( I ∗ D | I R ) via the latent control variables X . Inference ov er X mediates the degree of smoothing in the posterior . size and rotation. Also let X = { X j } be a decomposition of the control variables X into parts X j with priors P ( X j ) , such as the bandwidths of per-glyph Gaussian spatial blur kernels, the variance of a Gaussian image likelihood, and so on. Our proposals modify single elements of the scene and control variables at a time, as follo ws: P ( S ) = Y i P ( S i ) q i ( S 0 i , S i ) = P ( S 0 i ) P ( X ) = Y j P ( X j ) q j ( X 0 j , X j ) = P ( X 0 j ) Now let K = |{ S i }| + |{ X j }| be the total number of random variables in each ex ecution. For simplicity , we describe the case where this number can be bounded abov e beforehand, i.e. total a priori scene comple xity is limited. At each inference step, we choose a random v ariable index k < K uniformly at random. If k corresponds to a scene variable i , then we propose from q i ( S 0 i , S i ) , so our overall proposal kernel q (( S, X ) → ( S 0 , X 0 )) = δ S − i ( S 0 ) P ( S 0 i ) δ X ( X 0 ) . If k corresponds to a control variable j , we propose from q j ( X 0 j , X j ) . In both cases we re-render the scene I 0 R = f ( S 0 , X 0 ) . W e then run the kernel associated with this variable, and accept or reject via the Metropolis-Hastings equation: α M H (( S, X ) → ( S 0 , X 0 )) = min 1 , P ( I D | f ( S 0 , X 0 ) , X 0 ) P ( S 0 ) P ( X 0 ) q (( S 0 , X 0 ) → ( S, X )) P ( I D | f ( S, X ) , X ) P ( S ) P ( X ) q (( S, X ) → ( S 0 , X 0 )) W e implement our probabilistic graphics programs in a v ariant of the Church probabilistic program- ming language. The Metropolis-Hastings inference algorithm we use is provided by default in this system; no custom inference code is required. In the context of our generative probabilistic graph- ics formulation, this algorithm makes implicit use of ideas from approximate Bayesian computation (ABC). ABC methods approximate Bayesian inference ov er complex generative processes by using an exogenous distance function to compare sampled outputs with observed data. In the original rejection sampling formulation, samples are accepted only if they match the data within a hard threshold. Sub- sequently , combinations of ABC and MCMC were proposed [10], including variants with inference ov er the threshold v alue [14]. Most recently , extensions hav e been introduced where the hard cutoff is replaced with a stochastic lik elihood model [18]. Our formulation incorporates a combination of these insights: rendered scenes are only approximately constrained to match the observed image, with the tightness of the match mediated by inference over factors such as the fidelity of the rendering and the stochasticity in the likelihood. This allows image variability that is unnecessary or even undesirable to model to be treated in a principled fashion. 3 Figure 2: Four input images from our CAPTCHA corpus, along with the final results and con vergence trajectory of typical inference runs. The first row is a highly cluttered synthetic CAPTCHA exhibiting extreme letter o verlap. The second ro w is a CAPTCHA from T urboT ax, the third ro w is a CAPTCHA from A OL, and the fourth row shows an example where our system makes errors on some runs. Our probabilistic graphics program did not originally support rotation, which was needed for the A OL CAPTCHAs; adding it required only 1 additional line of probabilistic code. See the main text for quantitativ e details, and supplemental material for the full corpus. 3 Generative Probabilistic Graphics in 2D for Reading Degraded T ext. W e dev eloped a probabilistic graphics program for reading short snippets of degraded text consisting of arbitrary digits and letters. See Figure 2 for representativ e inputs and outputs. In this program, the latent scene S = { S i } contains a bank of variables for each glyph, including whether a potential letter is present or absent from the scene, what its spatial coordinates and size are, what its identity is, and how it is rotated: P ( S pres i = 1) = 0 . 5 P ( S x i = x ) = 1 /w 0 ≤ x ≤ w 0 otherwise P ( S y i = y ) = 1 /h 0 ≤ x ≤ h 0 otherwise P ( S glyph id i = g ) = ( 1 /G 0 ≤ S glyph id i < G 0 otherwise P ( S θ i = g ) = 1 / 2 θ max − θ max ≤ S θ i < θ max 0 otherwise Our renderer rasterizes each letter independently , applies a spatial blur to each image, composites the letters, and then blurs the result. W e also applied global blur to the original training image before applying the stochastic likelihood model on the blurred original and rendered images. The stochastic likelihood model is a multiv ariate Gaussian whose mean is the blurry rendering; formally , I D ∼ N ( I R ; σ ) . The control variables X = { X j } for the renderer and likelihood consist of per-letter Gaussian spatial blur bandwidths X i j ∼ λ · B eta (1 , 2) , a global image blur on the rendered image X blur rendered ∼ β · B eta (1 , 2) , a global image blur on the original test image X blur test ∼ γ · B eta (1 , 2) , and the standard deviation of the Gaussian likelihood σ ∼ Gamma (1 , 1) (with λ , γ and β set to fav or small bandwidths). T o make hard classification decisions, we use the sample with lo west pixel reconstruction error from a set of 5 approximate posterior samples. W e also experimented with enabling enumerative (griddy) Gibbs sampling for uniform discrete variables with 10% probability . The probabilistic code for this model is shown in Figure 4. T o assess the accuracy of our approach on adversarially obscured text, we developed a CAPTCHA corpus consisting of o ver 40 images from widely used websites such as T urboT ax, E-T rade, and A OL, plus additional challenging synthetic CAPTCHAs with high degrees of letter overlap and superim- posed distractors. Each source of text violates the underlying assumptions of our probabilistic graph- ics program in different ways. TurboT ax CAPTCHAs incorporate occlusions that break strok es within 4 (a) 0 5000 10000 15000 20000 MH transitions 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 Pixel Difference (L2 Norm) 1e11 High Stochasticity Low Stochasticity (b) (c) 0 5000 10000 15000 20000 25000 Iterations 1.2 1.0 0.8 0.6 0.4 0.2 0.0 Logscore 1e7 (d) 0 5000 10000 15000 20000 25000 Iterations 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Pixel Difference (L2 Norm) 1e12 (e) 0 5000 10000 15000 20000 25000 Iterations 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5 6.0 Letter Count (f) 0 5000 10000 15000 20000 25000 Iteration 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 Blur Kernel D C E A B Figure 3: Inference over renderer fidelity significantly improves the reliability of inference. (a) Re- construction errors for 5 runs of two variants of our probabilistic graphics program for text. W ithout sufficient stochasticity and approximation in the generati ve model — that is, with a strong prior o ver a purely deterministic, high-fidelity renderer — inference gets stuck in local energy minima (red lines). W ith inference over renderer fidelity via per-letter and global blur, the tolerance of the image likeli- hood, and the number of letters, con vergence impro ves substantially (blue lines). Many local minima in the likelihood are escaped over the course of single-variable inference, and the blur variables are automatically adjusted to support localizing and identifying letters. (b) Clockwise from top left: an input CAPTCHA, two typical local minima, and one correct parse. (c,d,e,f) A representati ve run, il- lustrating the con ver gence dynamics that result from inference over the renderer’ s fidelity . From left to right, we show ov erall log probability , pixel-wise disagreement (many local minima are escaped over the course of inference), the number of active letters in the scene, and the per-letter blur variables. Inference automatically adjusts blur so that ne wly proposed letters are often blurred out until they are localized and identified accurately . letters, while A OL CAPTCHAs include per-letter warping. These CAPTCHAs all in volve arbitrary digits and letters, and as a result lack cues from word identity that the best published CAPTCHA breaking systems depend on [11]. W e observe robust character recognition giv en enough inference, with an overall character detection rate of 70.6%. T o calibrate the difficulty of our corpus, we also ran the T esseract optical character recognition engine [15] on our corpus; its character detection rate was 37.7%. W e hav e found that the dynamically-adjustable fidelity of our approximate renderer and the high stochasticity of our generativ e model are necessary for inference to robustly conv erge to accurate results. This aspect of our formulation can be viewed as a kind of self-tuning, stochastic Bayesian analogue of annealing, and significantly improv es the rob ustness of our approach. See Figure 3 for an illustration of these dynamics. 4 Generative Probabilistic Graphics in 3D: Road Finding. W e hav e also dev eloped a generative probabilistic graphics program for localizing roads in 3D from single images. This is an important problem in autonomous driving. As with many perception prob- lems in robotics, there is clear scene structure to exploit, but also considerable uncertainty about the scene, as well as substantial image-to-image variability that needs to be robustly ignored. See Figure 5b for example inputs. The probabilistic graphics program we use for this problem is shown in Figure 7. The latent scene S is comprised of the height of the roadway from the ground plane, the road’ s width and lane size, and the 3D offset of the corner of the road from the (arbitrary) camera location. The prior encodes assumption that the lanes are small relativ e to the road, and that the road has two lanes and is very likely to be visible (but may not be centered). This scene is then rendered to produce a surface-based segmentation image , that assigns each input pixel to one of 4 regions r ∈ R = { left offroad , right offroad , road , lane } . Rendering is done for each scene element sepa- 5 ASSUME max-num-glyphs 10 ASSUME is_present (mem (lambda (id) ( bernoulli 0.5))) ASSUME pos_x (mem (lambda (id) ( uniform_discrete 0 200))) ASSUME pos_y (mem (lambda (id) ( uniform_discrete 0 200))) ASSUME size_x (mem (lambda (id) ( uniform_discrete 0 100))) ASSUME size_y (mem (lambda (id) ( uniform_discrete 0 100))) ASSUME rotation (mem (lambda (id) ( uniform_continuous -20.0 20.0))) ASSUME glyph (mem (lambda (id) ( uniform_discrete 0 35))) // 26 + 10. ASSUME blur (mem (lambda (id) ( * 7 ( beta 1 2)))) ASSUME global_blur ( * 7 ( beta 1 2)) ASSUME data_blur ( * 7 ( beta 1 2)) ASSUME epsilon ( gamma 1 1) ASSUME port 8000 // External renderer and likelihood server. ASSUME load_image ( load_remote port "load_image") ASSUME render_surfaces ( load_remote port "glyph_renderer") ASSUME incorporate_stochastic_likelihood ( load_remote port "likelihood") ASSUME data ( load_image "captcha_1.png" data_blur) ASSUME image ( render_surfaces max-num-glyphs global_blur (pos_x 1) (pos_y 1) (glyph 1) (size_x 1) (size_y 1) (rotation 1) (blur 1) (is_present 1) (pos_x 2) (pos_y 2) (glyph 2) (size_x 2) (size_y 2) (rotation 2) (blur 2) (is_present 2) ...) ASSUME use_enumeration 0.1 // Use 90% MH, 10% Gibbs. OBSERVE ( incorporate_stochastic_likelihood data image epsilon) True Figure 4: A generativ e probabilistic graphics program for reading degraded te xt. The scene generator chooses letter identity (A-Z and digits 0-9), position, size and rotation at random. These random variables are fed into the renderer , along with the bandwidths of a series of spatial blur kernels (one per letter, another for the overall redered image from generativ e model and another for the original input image). These blur kernels control the fidelity of the rendered image. The image returned by the renderer is compared to the data via a pixel-wise Gaussian likelihood model, whose variance is also an unknown v ariable. rately , follo wed by compositing, as with our 2D text program. See Figure 5a for random surface-based segmentation images drawn from this prior . Extensions to richer road and ground geometries are an interesting direction for future work. In our experiments, we used k -means (with k = 20 ) to cluster RGB values from a randomly chosen training image. W e used these clusters to build a compact appearance model based on cluster-center histograms, by assigning text image pixels to their nearest cluster . Our stochastic likelihood incor- porates these histograms, by multiplying together the appearance probabilities for each image region r ∈ R . These probabilities, denoted ~ theta r , are smoothed by pseudo-counts drawn from a Gamma distribution. Let Z r be the per-region normalizing constant, and I D ( x,y ) be the quantized pixel at coordinates ( x, y ) in the input image. Then our likelihood model is: P ( I D | I R , ) = Y r ∈ R Y x,y s . t . I R = r θ I D ( x,y ) r + Z r Figure 5f shows appearance model histograms from one random training frame. Figure 5c shows the extremely noisy lane/non-lane classifications that result from the appearance model on its own, without our scene prior; accurac y is e xtremely low . Other, richer appearance models, such as Gaussian mixtures ov er RGB v alues (which could be either hand specified or learned), are compatible with our formulation; our simple, quantized model was chosen primarily for simplicity . W e use the same generic Metropolis-Hastings strate gy for inference in this problem as in our te xt application. Although deterministic search strate gies for MAP inference could be developed for this particular program, it is less clear how to build a single deterministic search algorithm that could work on both of the generativ e probabilistic graphics programs we present. 6 (a) (b) (c) (d) (e) (f) 0 5 10 15 20 Color Codebook ID 0.0 0.1 0.2 0.3 0.4 Lanes 0 5 10 15 20 Color Codebook ID 0.0 0.1 0.2 0.3 0.4 Left offroad 0 5 10 15 20 Color Codebook ID 0.0 0.1 0.2 0.3 0.4 Right offroad 0 5 10 15 20 Color Codebook ID 0.0 0.1 0.2 0.3 0.4 Road Figure 5: An illustration of generativ e probabilistic graphics for 3D road finding. (a) Renderings of random samples from our scene prior, sho wing the surface-based image se gmentation induced by each sample. (b) Representativ e test frames from the KITTI dataset [4]. (c) Maximum likelihood lane/non- lane classification of the images from (b) based solely on the best-performing single-training-frame appearance model (ignoring latent geometry). Geometric constraints are clearly needed for reliable road finding. (d) Results from [1]. (e) T ypical inference results from the proposed generativ e proba- bilistic graphics approach on the images from (b). (f) Appearance model histograms (over quantized RGB values) from the best-performing single-training-frame appearance model for all four region types: lane , left offr oad , right offr oad and road . (a) Lanes superimposed from 30 scenes sampled from our prior (b) 30 posterior samples on a low accuracy (Frame 199), high uncertainty frame (c) 30 posterior samples on a high accurac y (Frame 384), low uncertainty frame Frame #199 Frame #384 0 100 200 300 400 500 X (d) Posterior samples of left lane position for both frames Figure 6: Approximate Bayesian inference yields samples from a broad, multimodal scene posterior on a frame that violates our modeling assumptions (note the intersection), b ut reports less uncertainty on a frame more compatible with our model (with perceptually reasonable alternativ es to the mode). In T able 1, we report the accurac y of our approach on one road dataset from the KITTI V ision Bench- mark Suite. T o focus on accuracy in the face of visual variability , we do not exploit temporal corre- spondences. W e test on every 5th frame for a total of 80. W e report lane/non-lane accuracy results for maximum lik elihood classification o ver 10 appearance models (from 10 randomly chosen training images), as well as for the single best appearance model from this set. W e use 10 posterior samples per frame for both. For reference, we include the performance of a sophisticated bottom-up baseline system from [1]. This baseline system requires significant 3D a priori knowledge, including the in- trinsic and extrinsic parameters of the camera, and a rough intial segmentation of each test image. In contrast, our approach has to infer these aspects of the scene from the image data. W e also show 7 // Units in arbitrary, uncentered renderer coordinate system. ASSUME road_width ( uniform_discrete 5 8) ASSUME road_height ( uniform_discrete 70 150) ASSUME lane_pos_x ( uniform_continuous -1.0 1.0) ASSUME lane_pos_y ( uniform_continuous -5.0 0.0) ASSUME lane_pos_z ( uniform_continuous 1.0 3.5) ASSUME lane_size ( uniform_continuous 0.10 0.35) ASSUME eps ( gamma 1 1) ASSUME port 8000 // External renderer and likelihood server. ASSUME load_image ( load_remote port "load_image") ASSUME render_surfaces ( load_remote port "road_renderer") ASSUME incorporate_stochastic_likelihood ( load_remote port "likelihood") ASSUME theta_left ( list 0.13 ... 0.03) ASSUME theta_right ( list 0.03 ... 0.02) ASSUME theta_road ( list 0.05 ... 0.07) ASSUME theta_lane ( list 0.01 ... 0.21) ASSUME data ( load_image "frame201.png") ASSUME surfaces ( render_surfaces lane_pos_x lange_pos_y lange_pos_z road_width road_height lane_size) OBSERVE ( incorporate_stochastic_likelihood theta_left theta_right theta_road theta_lane data surfaces eps) True Figure 7: Source code for a generativ e probabilistic graphics program that infers 3D road models. Method Accuracy Aly et al [1] 68.31% GPGP (Best Single Appearance) 64.56% GPGP (Maximum Likelihood ov er Multiple Appearances) 74.60% T able 1: Quantitativ e results for lane detection accuracy on one of the road datasets in the KITTI V ision Benchmark Suite [4]. See main text for details. examples of the uncertainty estimates that result from approximate Bayesian inference in Figure 6. Our probabilistic graphics program for this problem requires under 20 lines of probabilistic code. 5 Discussion W e hav e shown that it is possible to write short probabilistic graphics programs that use simple 2D and 3D computer graphics techniques as the backbone for highly approximate generative models. Approximate Bayesian inference ov er the ex ecution histories of these probabilistic graphics programs — automatically implemented via generic, single-variable Metropolis-Hastings transitions, using ex- isting rendering libraries and simple likelihoods — then implements a new variation on analysis by synthesis [20]. W e ha ve also shown that this approach can yield accurate, globally consistent interpre- tations of real-world images, and can coherently report posterior uncertainty over latent scenes when appropriate. Our core contributions are the introduction of this conceptual framew ork and two initial demonstrations of its efficac y . T o scale our inference approach to handle more complex scenes, it will likely be important to con- sider more complex forms of automatic inference, beyond the single-variable Metropolis-Hastings proposals we currently use. For example, discriminatively trained proposals could help, and in fact could be trained based on forward e xecutions of the probabilistic graphics program. Appearance mod- els deriv ed from modern image features and texture descriptors [13, 12] — going beyond the simple quantizations we currently use — could also reduce the burden on inference and improve the gen- eralizability of individual programs. It is important to note that the high dimensionality inv olved in probabilistic graphics programming does not necessarily mean inference (and ev en automatic infer- ence) is impossible. For example, approximate inference in models with probabilities bounded away from 0 and 1 can sometimes be prov ably tractable via sampling techniques, with runtimes that depend 8 on factors other than dimensionality [2]. In fact, preliminary experiments with our 2D text program (not shown) appear to show flat conv ergence times with up to 30 unknown letters. Exploring the role of stochasticity in facilitating tractability is an important a venue for future work. The most interesting potential of generativ e probabilistic graphics programming is the avenue it pro- vides for bringing powerful graphics representations and algorithms to bear on the hard modeling and inference problems in vision. For example, to av oid global re-rendering after each inference step, we need to represent and exploit the conditional independencies in the rendering process. Lifting graph- ics data structures such as z-buf fers into the probabilistic program itself might enable this. Real-time, high-resolution graphics software contains solutions to many hard technical problems in image syn- thesis. Long term, we hope probabilistic extensions of these ideas ultimately become part of analogous solutions for image analysis. Acknowledgments W e are grateful to Keith Bonawitz and Eric Jonas for preliminary work exploring the feasibility of CAPTCHA breaking in Church, and to Seth T eller , Bill Freeman, T ed Adelson, Michael James and Max Siegel for helpful discussions. References [1] Mohamed Aly. “Real time detection of lane markers in urban streets”. In: Intelligent V ehicles Symposium, 2008 IEEE . IEEE. 2008, pp. 7–12. [2] Paul Dagum and Michael Luby. “An optimal approximation algorithm for Bayesian inference”. In: Artificial Intelligence 93.1 (1997), pp. 1–27. [3] L Del Pero et al. “Bayesian geometric modeling of indoor scenes”. In: Computer V ision and P attern Recognition (CVPR), 2012 IEEE Confer ence on . IEEE. 2012, pp. 2719–2726. [4] Andreas Geiger, Philip Lenz, and Raquel Urtasun. “Are we ready for autonomous dri ving? The KITTI vision benchmark suite”. In: Computer V ision and P attern Recognition (CVPR), 2012 IEEE Confer ence on . IEEE. 2012, pp. 3354–3361. [5] Noah Goodman, V ikash Mansinghka, Daniel Roy, Keith Bonawitz, and Joshua T enenbaum. “Church: A language for generativ e models”. In: U AI . 2008. [6] Geoffre y E Hinton and Zoubin Ghahramani. “Generativ e models for discovering sparse dis- tributed representations”. In: Philosophical T ransactions of the Royal Society of London. Series B: Biological Sciences 352.1358 (1997), pp. 1177–1190. [7] Geoffre y E Hinton, Simon Osindero, and Y ee-Whye T eh. “A fast learning algorithm for deep belief nets”. In: Neural computation 18.7 (2006), pp. 1527–1554. [8] Derek Hoiem, Alex ei A Efros, and Martial Hebert. “Putting objects in perspectiv e”. In: Com- puter V ision and P attern Recognition, 2006 IEEE Computer Society Confer ence on . V ol. 2. IEEE. 2006, pp. 2137–2144. [9] Berthold Klaus Paul Horn. Robot vision . the MIT Press, 1986. [10] Paul Marjoram, John Molitor, V incent Plagnol, and Simon T av ar ´ e. “Markov chain Monte Carlo without likelihoods”. In: Pr oceedings of the National Academy of Sciences 100.26 (2003). [11] Greg Mori and Jitendra Malik. “Recognizing objects in adversarial clutter: Breaking a visual CAPTCHA”. In: Computer V ision and P attern Recognition, 2003. Pr oceedings. 2003 IEEE Computer Society Confer ence on . V ol. 1. IEEE. 2003, pp. I–134. [12] Aude Oliv a and Antonio T orralba. “Modeling the shape of the scene: A holistic representation of the spatial en velope”. In: International journal of computer vision 42.3 (2001), pp. 145–175. [13] Javier Portilla and Eero P Simoncelli. “A parametric texture model based on joint statistics of complex wa velet coefficients”. In: International J ournal of Computer V ision 40.1 (2000). [14] Oliv er Ratmann, Christophe Andrieu, Carsten W iuf, and Sylvia Richardson. “Model criticism based on likelihood-free inference, with an application to protein network ev olution”. In: 106.26 (2009), pp. 10576–10581. [15] Ray Smith. “An ov erview of the T esseract OCR engine”. In: Ninth International Confer ence on Document Analysis and Recognition. V ol. 2. IEEE. 2007, pp. 629–633. 9 [16] Zhuowen T u, Xiangrong Chen, Alan L Y uille, and Song-Chun Zhu. “Image parsing: Unifying segmentation, detection, and recognition”. In: International Journal of Computer V ision 63.2 (2005), pp. 113–140. [17] Zhuowen T u and Song-Chun Zhu. “Image Segmentation by Data-Driven Markov Chain Monte Carlo”. In: IEEE T rans. P attern Anal. Mach. Intell. 24.5 (May 2002). [18] Richard D Wilkinson. “Approximate Bayesian computation (ABC) gives exact results under the assumption of model error”. In: arXiv pr eprint arXiv:0811.3355 (2008). [19] David Wing ate, Noah D Goodman, A Stuhlmueller, and J Siskind. “Nonstandard interpreta- tions of probabilistic programs for efficient inference”. In: Advances in Neural Information Pr ocessing Systems 23 (2011). [20] Alan Y uille and Daniel Kersten. “V ision as Bayesian inference: analysis by synthesis?” In: T rends in co gnitive sciences 10.7 (2006), pp. 301–308. [21] Y ibiao Zhao and Song-Chun Zhu. “Image Parsing via Stochastic Scene Grammar”. In: Ad- vances in Neural Information Pr ocessing Systems . 2011. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment