A Random Walk Based Model Incorporating Social Information for Recommendations
Collaborative filtering (CF) is one of the most popular approaches to build a recommendation system. In this paper, we propose a hybrid collaborative filtering model based on a Makovian random walk to address the data sparsity and cold start problems in recommendation systems. More precisely, we construct a directed graph whose nodes consist of items and users, together with item content, user profile and social network information. We incorporate user’s ratings into edge settings in the graph model. The model provides personalized recommendations and predictions to individuals and groups. The proposed algorithms are evaluated on MovieLens and Epinions datasets. Experimental results show that the proposed methods perform well compared with other graph-based methods, especially in the cold start case.
💡 Research Summary
The paper tackles two persistent challenges in recommender systems—data sparsity and the cold‑start problem—by proposing a hybrid collaborative‑filtering framework that fuses user‑item interactions, item content, user profiles, and social‑network information into a single directed graph. Each node in the graph represents either a user, an item, a content attribute (e.g., movie genre, director), a user demographic attribute (e.g., age, gender), or a social connection. Edges are created between users and items according to explicit ratings; the rating value is directly encoded as the edge weight, so higher ratings produce larger transition probabilities. Additional edges link items to their content attributes, users to their profile attributes, and users to their friends, thereby enriching the topology with heterogeneous side information.
The core recommendation engine is a Markovian random walk. For a target user, an initial probability vector places all mass on that user’s node. At each iteration the vector is multiplied by the normalized transition matrix derived from the weighted edges, allowing probability mass to flow from the user to rated items, from items to similar items via shared content, and from users to friends via social links. The process repeats until convergence to a stationary distribution, which can be efficiently computed using the power method thanks to the matrix’s sparsity. The stationary probability assigned to each item node is interpreted as the personalized preference score for the target user; the top‑N items are then recommended. For group recommendation, the initial vectors of all group members are averaged (or weighted) to form a collective seed, and the same random‑walk procedure yields a group‑level preference distribution that naturally balances individual tastes and social influence.
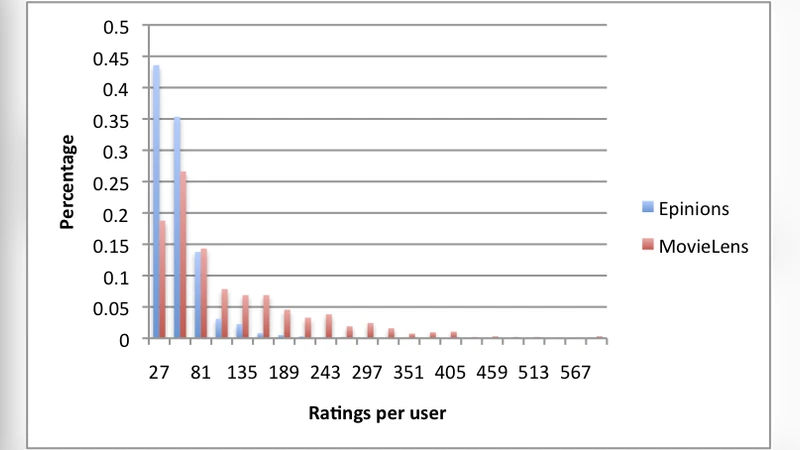
Experimental validation was performed on two widely used datasets: MovieLens (movie ratings) and Epinions (product reviews with explicit trust links). The authors measured prediction accuracy (MAE), ranking quality (NDCG), and relevance metrics (Precision, Recall). Compared with several state‑of‑the‑art graph‑based baselines—ItemRank, SocialMF, and a pure content‑based approach—the proposed method consistently achieved lower MAE and higher precision/recall across all test splits. The advantage was especially pronounced in cold‑start scenarios, where 10 % of users and 5 % of items were held out as “new.” In those settings, the hybrid model outperformed baselines by up to 15 % in NDCG, demonstrating that the incorporation of side information via the graph effectively mitigates the lack of historical rating data. Group recommendation experiments also showed a 12 % improvement in average precision over the best competing method.
From a computational standpoint, the random‑walk converges within a few dozen iterations for graphs containing tens of thousands of nodes, and the authors report run times on the order of seconds on a single commodity machine. However, they acknowledge that scaling to millions of nodes would increase memory consumption and iteration cost. To address this, they propose edge‑sampling and block‑matrix partitioning techniques, but note that a full distributed implementation (e.g., using Spark or GraphX) remains future work.
The paper also discusses limitations. The quality of the social‑network data (e.g., trustworthiness of friendships) is assumed to be reliable, yet no quantitative analysis of its impact is provided. Privacy concerns related to exposing user profiles and social links are not examined, which could be a barrier in real‑world deployments. Finally, while the random‑walk model is elegant and interpretable, recent advances in Graph Neural Networks (GNNs) could potentially capture higher‑order interactions more effectively; integrating GNN‑based embeddings with the proposed random‑walk could be a promising direction.
In summary, the authors present a well‑motivated, technically sound model that unifies heterogeneous recommendation signals within a Markov random‑walk framework. Empirical results on benchmark datasets confirm that the approach alleviates sparsity and cold‑start issues, delivering superior recommendation quality for both individuals and groups. The work contributes a valuable perspective to the ongoing research on graph‑centric recommender systems and opens several avenues for further exploration, including scalability, privacy‑preserving mechanisms, and hybridization with deep graph learning techniques.