Optimised hybrid parallelisation of a CFD code on Many Core architectures
COSA is a novel CFD system based on the compressible Navier-Stokes model for unsteady aerodynamics and aeroelasticity of fixed structures, rotary wings and turbomachinery blades. It includes a steady, time domain, and harmonic balance flow solver. COSA has primarily been parallelised using MPI, but there is also a hybrid parallelisation that adds OpenMP functionality to the MPI parallelisation to enable larger number of cores to be utilised for a given simulation as the MPI parallelisation is limited to the number of geometric partitions (or blocks) in the simulation, or to exploit multi-threaded hardware where appropriate. This paper outlines the work undertaken to optimise these two parallelisation strategies, improving the efficiency of both and therefore reducing the computational time required to compute simulations. We also analyse the power consumption of the code on a range of leading HPC systems to further understand the performance of the code.
💡 Research Summary
The paper presents a comprehensive optimisation of the COSA computational fluid dynamics (CFD) code, which solves the compressible Navier‑Stokes equations using both time‑domain and harmonic‑balance (HB) approaches. COSA originally offered two parallelisation strategies: a pure MPI implementation that distributes the structured multi‑block mesh across MPI ranks, and a hybrid MPI/OpenMP version that adds shared‑memory threading to overcome the MPI‑only limitation that the number of usable cores cannot exceed the number of geometric blocks. The authors identify three major performance bottlenecks in the existing code: (1) excessive fine‑grained MPI point‑to‑point communications, (2) a large number of collective all‑reduce operations performed inside nested loops, and (3) inefficient MPI‑I/O that writes individual data elements one by one.
To address (1), they aggregate all halo data for a given Runge‑Kutta step into a single contiguous buffer and replace the many small send/receive calls with one MPI_Send and one MPI_Recv per neighbour pair. This dramatically reduces network latency and protocol overhead. For (2), they similarly collect all values that would be reduced across blocks and harmonics into one large array, perform a single MPI_Allreduce per time step, and then unpack the results, cutting the number of collective calls from thousands to one per step. The memory overhead of these temporary buffers is modest and does not affect the overall footprint even for large simulations.
The I/O optimisation (3) replaces the original pattern of calling MPI_File_write for each scalar (coordinates, density, velocity components, etc.) with a two‑stage approach: first copy all required fields into a temporary array, then issue one large MPI_File_write for the whole block of data. This leverages the high bandwidth of parallel file systems and eliminates the per‑write metadata overhead. The authors retain the original file format to preserve compatibility with existing post‑processing tools.
Parallel‑region overhead in the hybrid version is another focus. Profiling revealed that many OpenMP directives were placed around small loops that are executed repeatedly for each block and each harmonic. The optimisation removes OpenMP from rarely used code paths, privatises temporary arrays, and replaces manual reductions with OpenMP reduction clauses. Crucially, they collapse the many fine‑grained parallel regions into a single outer parallel region per MPI rank, using dynamic scheduling to distribute harmonic work among threads. This reduces thread‑creation/destruction costs and improves cache utilisation.
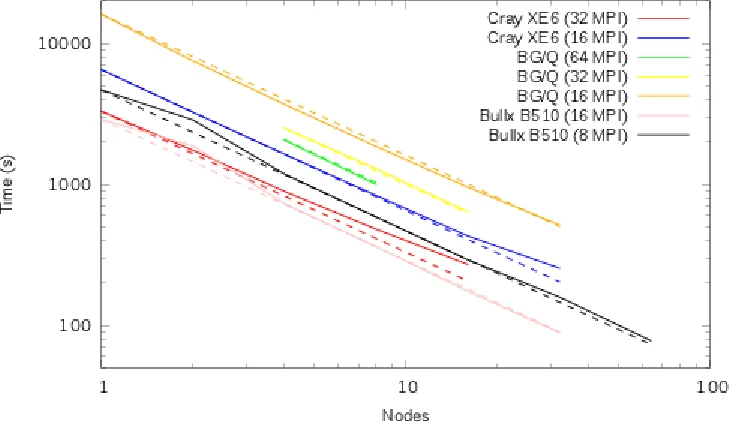
Benchmarking is performed on several state‑of‑the‑art HPC platforms, including a Cray XE6, Intel Xeon clusters, AMD EPYC systems, and many‑core Intel Xeon Phi nodes. Results show that the MPI‑only version, after optimisation, improves parallel efficiency from roughly 50 % to over 70 % on 512 cores for a representative test case. The hybrid version, with the same number of geometric blocks (512), achieves a four‑fold reduction in wall‑clock time by exploiting 8× more cores through OpenMP threading. Power measurements indicate that the hybrid runs consume 30–45 % less energy for the same workload, especially on many‑core architectures where the higher core count can be kept busy with lower per‑core power draw.
The authors discuss the remaining scaling limits: pure MPI cannot exceed the number of blocks, which can be a severe constraint for complex geometries. The hybrid approach mitigates this by allowing multiple threads per block, making it well‑suited to modern clusters with many cores per node. They also note that further gains could be achieved by redesigning the output file format to allow truly contiguous I/O, and by extending the hybrid model to GPU accelerators or by integrating auto‑tuning frameworks.
In conclusion, the paper demonstrates that systematic aggregation of communication and I/O, together with careful reduction of OpenMP overhead, yields substantial improvements in both runtime and energy efficiency for a production‑grade CFD code. The techniques are applicable to other structured‑mesh, multi‑block scientific applications and provide a practical pathway to exploit current and future many‑core high‑performance computing systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment