A new compressive video sensing framework for mobile broadcast
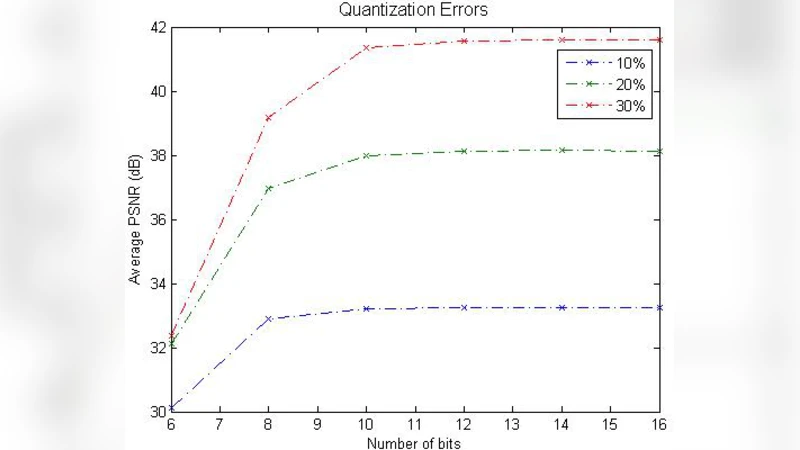
A new video coding method based on compressive sampling is proposed. In this method, a video is coded using compressive measurements on video cubes. Video reconstruction is performed by minimization of total variation (TV) of the pixelwise DCT coefficients along the temporal direction. A new reconstruction algorithm is developed from TVAL3, an efficient TV minimization algorithm based on the alternating minimization and augmented Lagrangian methods. Video coding with this method is inherently scalable, and has applications in mobile broadcast.
💡 Research Summary
The paper proposes a novel video coding and transmission framework tailored for mobile broadcast scenarios, where a single encoded stream must serve receivers with heterogeneous channel capacities and processing capabilities. Traditional scalable video coding (SVC) approaches such as MPEG‑2/4, H.264/SVC, or Motion‑JPEG2000 rely on ordered layers; loss of a lower layer renders higher layers unusable, leading to the well‑known “cliff effect.” To overcome this limitation, the authors adopt compressive sensing (CS) principles and design a system that encodes video in cubes—three‑dimensional blocks consisting of a small number of consecutive frames (temporal dimension) and a spatial sub‑region.
Encoding stage:
Each cube is vectorized into a signal (x \in \mathbb{R}^n) (where (n = r \times q \times p)). A random measurement matrix (A) (implemented as a permuted Walsh‑Hadamard transform) multiplies (x) to produce (m) compressive measurements (y = A x). Because the rows of (A) are incoherent with typical sparsifying bases, the measurements are of equal importance; any subset of the received measurements can be used for reconstruction. Consequently, a receiver that obtains more measurements (thanks to a higher‑capacity channel) can reconstruct a higher‑quality video, while a receiver with fewer measurements still obtains a usable, albeit lower‑quality, version. This property eliminates the cliff effect and provides graceful degradation with channel quality.
Reconstruction stage:
The authors formulate reconstruction as either a constrained problem (noise‑free) or an unconstrained L2‑penalized problem (noisy). The key contribution is the TV‑DCT regularization. First, a 1‑D discrete cosine transform (DCT) is applied along the temporal axis of each pixel location, converting temporal redundancy into frequency coefficients. Then, a spatial total variation (TV) norm is computed on each DCT coefficient map (i.e., on each column of the DCT‑transformed cube). The regularizer thus minimizes the spatial TV of the temporal‑frequency components:
\
Comments & Academic Discussion
Loading comments...
Leave a Comment