A Linear Time Active Learning Algorithm for Link Classification -- Full Version --
We present very efficient active learning algorithms for link classification in signed networks. Our algorithms are motivated by a stochastic model in which edge labels are obtained through perturbations of a initial sign assignment consistent with a…
Authors: Nicolo Cesa-Bianchi, Claudio Gentile, Fabio Vitale
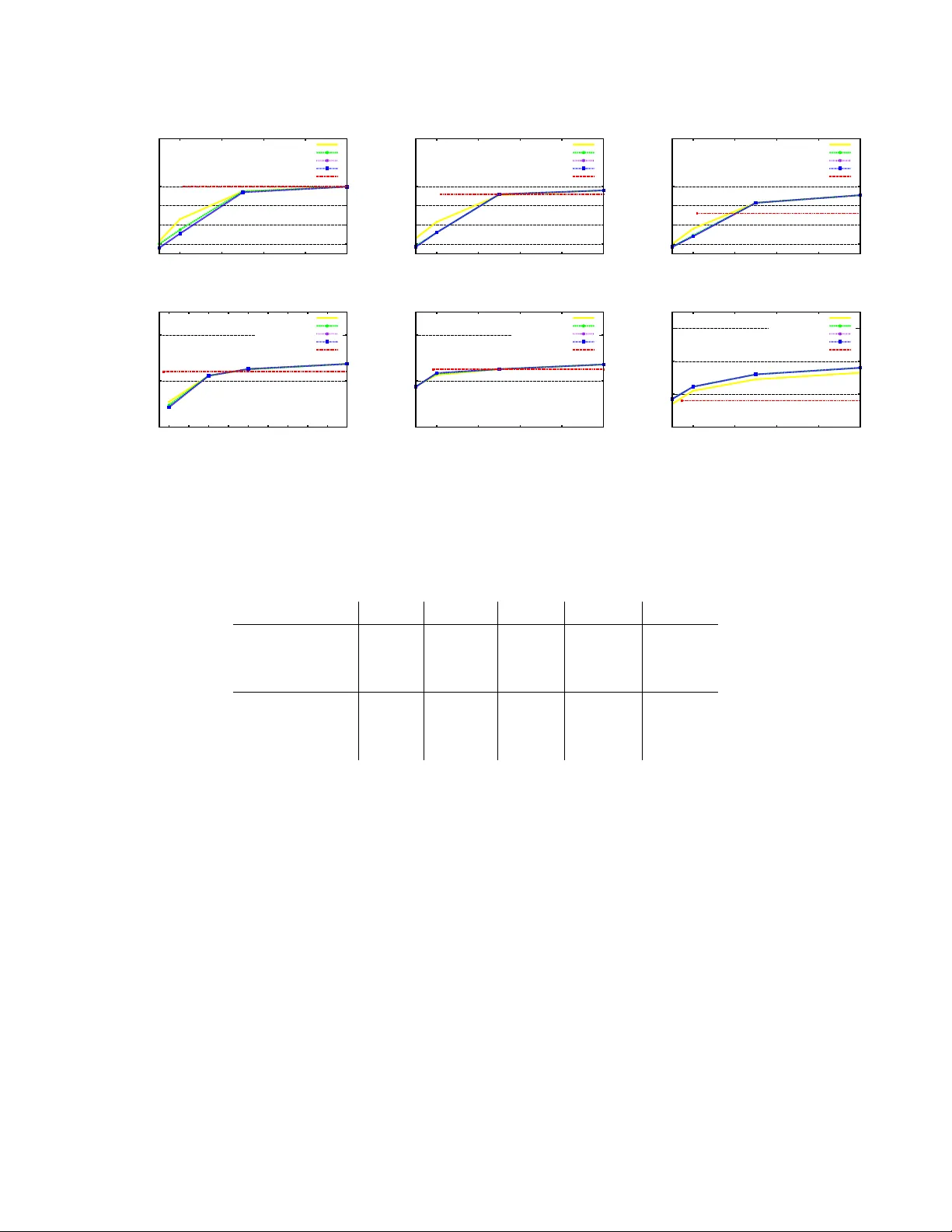
A Linear T ime Acti ve Learning Algorithm for Link Classification – Full V ersion – ∗ Nicol ` o Cesa-Bianchi Dipartimento di Informatica, Uni versit ` a degli Studi di Milano, Italy nicolo.cesa-bianchi@unimi.it Claudio Gentile DiST A, Uni versit ` a dell’Insubria, Italy claudio.gentile@uninsubria.it Fabio V itale Dipartimento di Informatica, Uni versit ` a degli Studi di Milano, Italy fabio.vitale@unimi.it Giov anni Zappella Dipartimento di Matematica, Uni versit ` a degli Studi di Milano, Italy giovanni.zappella@unimi.it June 15, 2021 Abstract W e present v ery ef ficient activ e learning algorithms for link classification in signed net- works. Our algorithms are moti vated by a stochastic model in which edge labels are ob- tained through perturbations of a initial sign assignment consistent with a two-clustering of the nodes. W e provide a theoretical analysis within this model, sho wing that we can achie ve an optimal (to whithin a constant factor) number of mistakes on any graph G = ( V , E ) such that | E | = Ω( | V | 3 / 2 ) by querying O ( | V | 3 / 2 ) edge labels. More generally , we show an algorithm that achie ves optimality to within a factor of O ( k ) by querying at most order of | V | + ( | V | /k ) 3 / 2 edge labels. The running time of this algorithm is at most of order | E | + | V | log | V | . ∗ This work was supported in part by the P ASCAL2 Network of Excellence under EC grant 216886 and by “Dote Ricerca”, FSE, Regione Lombardia. This publication only reflects the authors’ vie ws. 1 1 Intr oduction A rapidly emerging theme in the analysis of networked data is the study of signed networks. From a mathematical point of vie w , signed networks are graphs whose edges carry a sign representing the positi ve or negati ve nature of the relationship between the incident nodes. For example, in a protein network two proteins may interact in an excitatory or inhibitory fashion. The domain of social networks and e-commerce of fers sev eral examples of signed relationships: Slashdot users can tag other users as friends or foes, Epinions users can rate other users positiv ely or negati vely , Ebay users dev elop trust and distrust tow ards sellers in the network. More generally , two individuals that are related because they rate similar products in a recommendation website may agree or disagree in their ratings. The av ailability of signed networks has stimulated the design of link classification algorithms, especially in the domain of social networks. Early studies of signed social networks are from the Fifties. E.g., [13] and [1] model dislike and distrust relationships among indi viduals as (signed) weighted edges in a graph. The conceptual underpinning is provided by the theory of social bal- ance , formulated as a way to understand the structure of conflicts in a network of indi viduals whose mutual relationships can be classified as friendship or hostility [14]. The advent of online social networks has re v amped the interest in these theories, and spurred a significant amount of recent work —see, e.g., [12, 16, 19, 8, 10, 7], and references therein. Many heuristics for link classification in social networks are based on a form of social balance summarized by the motto “the enemy of my enemy is my friend”. This is equi valent to saying that the signs on the edges of a social graph tend to be consistent with some two-clustering of the nodes. By consistenc y we mean the follo wing: The nodes of the graph can be partitioned into two sets (the tw o clusters) in such a way that edges connecting nodes from the same set are positi ve, and edges connecting nodes from dif ferent sets are negati ve. Although two-clustering heuristics do not require strict consistenc y to work, this is admittely a rather strong inductiv e bias. Despite that, social network theorists and practitioners found this to be a reasonable bias in man y social contexts, and recent experiments with online social netw orks reported a good predicti ve po wer for algorithms based on the two-clustering assumption [16, 18, 19, 8]. Finally , this assumption is also fairly con venient from the vie wpoint of algorithmic design. In the case of undirected signed graphs G = ( V , E ) , the best performing heuristics exploit- ing the tw o-clustering bias are based on spectral decompositions of the signed adiacency matrix. Noticeably , these heuristics run in time Ω | V | 2 , and often require a similar amount of memory storage e ven on sparse networks, which mak es them impractical on large graphs. In order to obtain scalable algorithms with formal performance guarantees, we focus on the acti ve learning protocol, where training labels are obtained by querying a desired subset of edges. Since the allocation of queries can match the graph topology , a wide range of graph-theoretic techniques can be applied to the analysis of acti ve learning algorithms. In the recent work [7], a simple stochastic model for generating edge labels by perturbing some unknown two-clustering of the graph nodes was introduced. For this model, the authors prov ed that querying the edges of a low-stretch spanning tree of the input graph G = ( V , E ) is sufficient to predict the remain- ing edge labels making a number of mistakes within a factor of order (log | V | ) 2 log log | V | from the theoretical optimum. The o verall running time is O ( | E | ln | V | ) . This result leav es two main problems open: First, low-stretch trees are a po werful structure, but the algorithm to construct 2 them is not easy to implement. Second, the tree-based analysis of [7] does not generalize to query budgets lar ger than | V | − 1 (the edge set size of a spanning tree). In this paper we introduce a dif ferent activ e learning approach for link classification that can accomodate a lar ge spectrum of query b udgets. W e show that on any graph with Ω( | V | 3 / 2 ) edges, a query budget of O ( | V | 3 / 2 ) is suf ficient to predict the remaining edge labels within a constant factor from the optimum. More in general, we sho w that a budget of at most order of | V | + | V | k 3 / 2 queries is suf ficient to make a number of mistakes within a factor of O ( k ) from the optimum with a running time of order | E | + ( | V | /k ) log( | V | /k ) . Hence, a query b udget of Θ( | V | ) , of the same order as the algorithm based on lo w-strech trees, achiev es an optimality factor O ( | V | 1 / 3 ) with a running time of just O ( | E | ) . At the end of the paper we also report on a preliminary set of experiments on medium-sized synthetic and real-world datasets, where a simplified algorithm suggested by our theoretical find- ings is compared against the best performing spectral heuristics based on the same inductiv e bias. Our algorithm seems to perform similarly or better than these heuristics. 2 Pr eliminaries and notation W e consider undirected and connected graphs G = ( V , E ) with unknown edge labeling Y i,j ∈ {− 1 , +1 } for each ( i, j ) ∈ E . Edge labels can collecti vely be represented by the associated signed adjacency matrix Y , where Y i,j = 0 whene ver ( i, j ) 6∈ E . In the sequel, the edge-labeled graph G will be denoted by ( G, Y ) . W e define a simple stochastic model for assigning binary labels Y to the edges of G . This is used as a basis and moti v ation for the design of our link classification strategies. As we men- tioned in the introduction, a good trade-off between accurac y and efficienc y in link classification is achiev ed by assuming that the labeling is well approximated by a two-clustering of the nodes. Hence, our stochastic labeling model assumes that edge labels are obtained by perturbing an under - lying labeling which is initially consistent with an arbitrary (and unkno wn) two-clustering. More formally , gi ven an undirected and connected graph G = ( V , E ) , the labels Y i,j ∈ {− 1 , +1 } , for ( i, j ) ∈ E , are assigned as follows. First, the nodes in V are arbitrarily partitioned into two sets, and labels Y i,j are initially assigned consistently with this partition (within-cluster edges are positi ve and between-cluster edges are negati ve). Note that the consistency is equiv alent to the follo wing multiplicative rule : For any ( i, j ) ∈ E , the label Y i,j is equal to the product of signs on the edges of an y path connecting i to j in G . This is in turn equi valent to say that an y simple c ycle within the graph contains an even number of negati ve edges. Then, gi ven a nonnegati ve constant p < 1 2 , labels are randomly flipped in such a way that P Y i,j is flipped ≤ p for each ( i, j ) ∈ E . W e call this a p -stochastic assignment. Note that this model allo ws for correlations between flipped labels. A learning algorithm in the link classification setting recei ves a training set of signed edges and, out of this information, builds a prediction model for the labels of the remaining edges. It is quite easy to prov e a lo wer bound on the number of mistak es that an y learning algorithm mak es in this model. F act 1. F or any undir ected gr aph G = ( V , E ) , any training set E 0 ⊂ E of edg es, and any learning algorithm that is given the labels of the edges in E 0 , the number M of mistakes made by A on the 3 r emaining E \ E 0 edges satisfies E M ≥ p E \ E 0 , where the expectation is with r espect to a p -stochastic assignment of the labels Y . Pr oof. Let Y be the following randomized labeling: first, edge labels are set consistently with an arbitrary two-clustering of V . Then, a set of 2 p | E | edges is selected uniformly at random and the labels of these edges are set randomly (i.e., flipped or not flipped with equal probability). Clearly , P ( Y i,j is flipped ) = p for each ( i, j ) ∈ E . Hence this is a p -stochastic assignment of the labels. Moreov er , E \ E 0 contains in expectation 2 p E \ E 0 randomly labeled edges, on which A makes p E \ E 0 mistakes in e xpectation. In this paper we focus on active learning algorithms. An acti ve learner for link classification first constructs a query set E 0 of edges, and then receiv es the labels of all edges in the query set. Based on this training information, the learner builds a prediction model for the labels of the remaining edges E \ E 0 . W e assume that the only labels ev er re vealed to the learner are those in the query set. In particular , no labels are re vealed during the prediction phase. It is clear from Fact 1 that any activ e learning algorithm that queries the labels of at most a constant fraction of the total number of edges will make on a verage Ω( p | E | ) mistakes. W e often write V G and E G to denote, respectiv ely , the node set and the edge set of some underlying graph G . For any two nodes i, j ∈ V G , P ath( i, j ) is any path in G having i and j as terminals, and | P ath( i, j ) | is its length (number of edges). The diameter D G of a graph G is the maximum over pairs i, j ∈ V G of the shortest path between i and j . Giv en a tree T = ( V T , E T ) in G , and two nodes i, j ∈ V T , we denote by d T ( i, j ) the distance of i and j within T , i.e., the length of the (unique) path P ath T ( i, j ) connecting the two nodes in T . Moreov er , π T ( i, j ) denotes the parity of this path, i.e., the product of edge signs along it. When T is a rooted tree, we denote by Children T ( i ) the set of children of i in T . Finally , giv en two disjoint subtrees T 0 , T 00 ⊆ G such that V T 0 ∩ V T 00 ≡ ∅ , we let E G ( T 0 , T 00 ) ≡ ( i, j ) ∈ E G : i ∈ V T 0 , j ∈ V T 00 . 3 Algorithms and their analysis In this section, we introduce and analyze a family of acti ve learning algorithms for link classifi- cation. The analysis is carried out under the p -stochastic assumption. As a warm up, we start of f recalling the connection to the theory of lo w-stretch spanning trees (e.g., [9]), which turns out to be useful in the important special case when the activ e learner is afforded to query only | V | − 1 labels. Let E flip ⊂ E denote the (random) subset of edges whose labels hav e been flipped in a p - stochastic assignment, and consider the following class of activ e learning algorithms parameterized by an arbitrary spanning tree T = ( V T , E T ) of G . The algorithms in this class use E 0 = E T as query set. The label of an y test edge e 0 = ( i, j ) 6∈ E T is predicted as the parity π T ( e 0 ) . Clearly enough, if a test edge e 0 is predicted wrongly , then either e 0 ∈ E flip or P ath T ( e 0 ) contains at least one flipped edge. Hence, the number of mistakes M T made by our activ e learner on the set of test edges E \ E T can be deterministically bounded by M T ≤ | E flip | + X e 0 ∈ E \ E T X e ∈ E I e ∈ Path T ( e 0 ) I e ∈ E flip (1) 4 where I · denotes the indicator of the Boolean predicate at argument. A quantity which can be related to M T is the avera ge str etch of a spanning tree T which, for our purposes, reduces to 1 | E | h | V | − 1 + P e 0 ∈ E \ E T P ath T ( e 0 ) i . A stunning result of [9] sho ws that e very connected, undirected and unweighted graph has a spanning tree with an av erage stretch of just O log 2 | V | log log | V | . If our activ e learner uses a spanning tree with the same lo w stretch, then the following result holds. Theorem 1 ([7]) . Let ( G, Y ) = (( V , E ) , Y ) be a labeled graph with p -stochastic assigned labels Y . If the active learner queries the edges of a spanning tr ee T = ( V T , E T ) with aver age str etch O log 2 | V | log log | V | , then E M T ≤ p | E | × O log 2 | V | log log | V | . W e call the quantity multiplying p | E | in the upper bound the optimality factor of the algorithm. Recall that Fact 1 implies that this f actor cannot be smaller than a constant when the query set size is a constant fraction of | E | . Although low-stretch trees can be constructed in time O | E | ln | V | , the algorithms are fairly complicated (we are not aw are of av ailable implementations), and the constants hidden in the asymptotics can be high. Another disadvantage is that we are forced to use a query set of small and fixed size | V | − 1 . In what follo ws we introduce algorithms that ov ercome both limitations. A k ey aspect in the analysis of prediction performance is the ability to select a query set so that each test edge creates a short circuit with a training path. This is quantified by P e ∈ E I e ∈ Path T ( e 0 ) in (1). W e make this e xplicit as follows. Gi ven a test edge ( i, j ) and a path P ath( i, j ) whose edges are queried edges, we say that we are predicting label Y i,j using path P ath( i, j ) Since ( i, j ) closes P ath( i, j ) into a circuit, in this case we also say that ( i, j ) is predicted using the circuit. F act 2. Let ( G, Y ) = (( V , E ) , Y ) be a labeled graph with p -stochastic assigned labels Y . Given query set E 0 ⊆ E , the number M of mistakes made when pr edicting test edges ( i, j ) ∈ E \ E 0 using training paths P ath( i, j ) whose length is uniformly bounded by ` satisfies E M ≤ ` p | E \ E 0 | . Pr oof. W e hav e the chain of inequalities E M ≤ X ( i,j ) ∈ E \ E 0 1 − (1 − p ) | Path( i,j ) | ≤ X ( i,j ) ∈ E \ E 0 1 − (1 − p ) ` ≤ X ( i,j ) ∈ E \ E 0 ` p ≤ ` p | E \ E 0 | . For instance, if the input graph G = ( V , E ) has diameter D G and the queried edges are those of a breadth-first spanning tree, which can be generated in O ( | E | ) time, then the abo ve fact holds with | E 0 | = | V | − 1 , and ` = 2 D G . Comparing to F act 1 sho ws that this simple breadth-first strate gy 5 is optimal up to constants f actors whenev er G has a constant diameter . This simple observation is especially relev ant in the light of the typical graph topologies encountered in practice, whose diameters are often small. This argument is at the basis of our experimental comparison —see Section 4 . Y et, this mistake bound can be vacuous on graph ha ving a lar ger diameter . Hence, one may think of adding to the training spanning tree new edges so as to reduce the length of the circuits used for prediction, at the cost of increasing the size of the query set. A similar technique based on short circuits has been used in [7], the goal there being to solve the link classification problem in a harder adversarial en vironment. The precise tradeoff between prediction accuracy (as measured by the expected number of mistak es) and fraction of queried edges is the main theoretical concern of this paper . W e no w introduce an intermediate (and simpler) algorithm, called T R E E C U T T E R , which im- prov es on the optimality factor when the diameter D G is not small. In particular , we demonstrate that T R E E C U T T E R achiev es a good upper bound on the number of mistakes on any graph such that | E | ≥ 3 | V | + p | V | . This algorithm is especially effecti ve when the input graph is dense, with an optimality factor between O (1) and O ( p | V | ) . Moreover , the total time for predicting the test edges scales linearly with the number of such edges, i.e., T R E E C U T T E R predicts edges in constant amortized time. Also, the space is linear in the size of the input graph. The algorithm (pseudocode giv en in Figure 1) is parametrized by a positi ve integer k ranging from 2 to | V | . The actual setting of k depends on the graph topology and the desired fraction of query set edges, and plays a crucial role in determining the prediction performance. Setting k ≤ D G makes T R E E C U T T E R reduce to querying only the edges of a breadth-first spanning tree of G , otherwise it operates in a more in v olved way by splitting G into smaller node-disjoint subtrees. In a preliminary step (Line 1 in Figure 1), T R E E C U T T E R draws an arbitrary breadth-first span- ning tree T = ( V T , E T ) . Then subroutine E X T R A C T T R E E L E T ( T , k ) is used in a do-while loop to split T into vertex-disjoint subtrees T 0 whose height is k (one of them might hav e a smaller height). E X T R AC T T R E E L E T ( T , k ) is a very simple procedure that performs a depth-first visit of the tree T at argument. During this visit, each internal node may be visited sev eral times (during backtracking steps). W e assign each node i a tag h T ( i ) representing the height of the subtree of T rooted at i . h T ( i ) can be recursively computed during the visit. After this assignment, if we have h T ( i ) = k (or i is the root of T ) we return the subtree T i of T rooted at i . Then T R E E C U T T E R remov es (Line 6) T i from T along with all edges of E T which are incident to nodes of T i , and then iterates until V T gets empty . By construction, the diameter of the generated subtrees will not be larger than 2 k . Let T denote the set of these subtrees. For each T 0 ∈ T , the algorithm queries all the labels of E T 0 , each edge ( i, j ) ∈ E G \ E T 0 such that i, j ∈ V T 0 is set to be a test edge, and label Y i,j is predicted using P ath T 0 ( i, j ) (note that this coincides with P ath T 0 ( i, j ) , since T 0 ⊆ T ), that is, ˆ Y i,j = π T ( i, j ) . Finally , for each pair of distinct subtrees T 0 , T 00 ∈ T such that there exists a node of V T 0 adjacent to a node of V T 00 , i.e., such that E G ( T 0 , T 00 ) is not empty , we query the label of an arbitrarily selected edge ( i 0 , i 00 ) ∈ E G ( T 0 , T 00 ) (Lines 8 and 9 in Figure 1). Each edge ( u, v ) ∈ E G ( T 0 , T 00 ) whose label has not been pre viously queried is then part of the test set, and its label will be predicted as ˆ Y u,v ← π T ( u, i 0 ) · Y i 0 ,i 00 · π T ( i 00 , v ) (Line 11 ). That is, using the path obtained by concatenating P ath T 0 ( u, i 0 ) to edge ( i 0 , i 00 ) to P ath T 0 ( i 00 , v ) . 6 T R E E C U T T E R ( k ) Parameter: k ≥ 2 Initialization: T ← ∅ . 1. Draw an arbitrary breadth-first spanning tree T of G 2. Do 3. T 0 ← E X T R AC T T R E E L E T ( T , k ) , and query all labels in E T 0 4. T ← T ∪ { T 0 } 5. F or each i, j ∈ V T 0 , set predict ˆ Y i,j ← π T ( i, j ) 6. T ← T \ T 0 7. While ( V T 6≡ ∅ ) 8. F or each T 0 , T 00 ∈ T : T 0 6≡ T 00 9. If E G ( T 0 , T 00 ) 6≡ ∅ query the label of an arbitrary edge ( i 0 , i 00 ) ∈ E G ( T 0 , T 00 ) 10. F or each ( u, v ) ∈ E G ( T 0 , T 00 ) \ { ( i 0 , i 00 ) } , with i 0 , u ∈ V T 0 and v , i 00 ∈ V T 00 11. predict ˆ Y u,v ← π T 0 ( u, i 0 ) · Y i 0 ,i 00 · π T 00 ( i 00 , v ) Figure 1: T R E E C U T T E R pseudocode. E X T R A C T T R E E L E T ( T , k ) Parameters: tree T , k ≥ 2 . 1. Perform a depth-first visit of T starting from the root. 2. During the visit 3. F or each i ∈ V T visited for the | 1 + Children T ( i ) | -th time (i.e., the last visit of i ) 4. If i is a leaf set h T ( i ) ← 0 5. Else set h T ( i ) ← 1 + max { h T ( j ) : j ∈ Children T ( i ) } 6. If h T ( i ) = k or i ≡ T ’ s root retur n subtree rooted at i Figure 2: E X T R AC T T R E E L E T pseudocode. The following theorem 1 quantifies the number of mistakes made by T R E E C U T T E R . The re- quirement on the graph density in the statement, i.e., | V | − 1 + | V | 2 2 k 2 + | V | 2 k ≤ | E | 2 implies that the test set is not larger than the query set. This is a plausible assumption in activ e learning scenarios, and a way of adding meaning to the bounds. Theorem 2. F or any inte ger k ≥ 2 , the number M of mistakes made by T R E E C U T T E R on any graph G ( V , E ) with | E | ≥ 2 | V | − 2 + | V | 2 k 2 + | V | k satisfies E M ≤ min { 4 k + 1 , 2 D G } p | E | , while the query set size is bounded by | V | − 1 + | V | 2 2 k 2 + | V | 2 k ≤ | E | 2 . 3.1 Refinements W e no w refine the simple ar gument leading to T R E E C U T T E R , and present our activ e link classifier . The pseudocode of our refined algorithm, called S T A R M A K E R , follo ws that of Figure 1 with the follo wing differences: Line 1 is dropped (i.e., S T A R M A K E R does not draw an initial spanning tree), and the call to E X T R A C T T R E E L E T in Line 3 is replaced by a call to E X T R AC T S T A R . This 1 Due to space limitations long proofs are presented in the supplementary material. 7 ne w subroutine just selects the star T 0 centered on the node of G having largest degree, and queries all labels of the edges in E T 0 . The next result sho ws that this algorithm gets a constant optimality factor while using a query set of size O ( | V | 3 / 2 ) . Theorem 3. The number M of mistakes made by S TA R M A K E R on any given graph G ( V , E ) with | E | ≥ 2 | V | − 2 + 2 | V | 3 2 satisfies E M ≤ 5 p | E | , while the query set size is upper bounded by | V | − 1 + | V | 3 2 ≤ | E | 2 . Finally , we combine S T A R M A K E R with T R E E C U T T E R so as to obtain an algorithm, called T R E E L E T S TA R , that can work with query sets smaller than | V | − 1 + | V | 3 2 labels. T R E E L E T S T A R is parameterized by an integer k and follo ws Lines 1–6 of Figure 1 creating a set T of trees through repeated calls to E X T R AC T T R E E L E T . Lines 7–11 are instead replaced by the follo wing procedure: a graph G 0 = ( V G 0 , E G 0 ) is created such that: (1) each node in V G 0 corresponds to a tree in T , (2) there exists an edge in E G 0 if and only if the two corresponding trees of T are connected by at least one edge of E G . Then, E X T R AC T S T A R is used to generate a set S of stars of vertices of G 0 , i.e., stars of trees of T . Finally , for each pair of distinct stars S 0 , S 00 ∈ S connected by at least one edge in E G , the label of an arbitrary edge in E G ( S 0 , S 00 ) is queried. The remaining edges are all predicted. Theorem 4. F or any inte ger k ≥ 2 and for any graph G = ( V , E ) with | E | ≥ 2 | V | − 2 + 2 | V |− 1 k + 1 3 2 , the number M of mistakes made by T R E E L E T S T A R ( k ) on G satisfies E M = O (min { k , D G } ) p | E | , while the query set size is bounded by | V | − 1 + | V |− 1 k + 1 3 2 ≤ | E | 2 . Hence, ev en if D G is large, setting k = | V | 1 / 3 yields a O ( | V | 1 / 3 ) optimality factor just by querying O ( | V | ) edges. On the other hand, a truly constant optimality f actor is obtained by query- ing as few as O ( | V | 3 / 2 ) edges (provided the graph has suf ficiently many edges). As a direct consequence (and surprisingly enough), on graphs which are only moderately dense we need not observe too many edges in order to achie ve a constant optimality factor . It is instructi ve to compare the bounds obtained by T R E E L E T S TA R to the ones we can achiev e by using the C C C C algorithm of [7], or the lo w-stretch spanning trees giv en in Theorem 1. Because C C C C operates within a harder adversarial setting, it is easy to sho w that Theorem 9 in [7] e xtends to the p -stochastic assignment model by replacing ∆ 2 ( Y ) with p | E | therein. 2 The re- sulting optimality factor is of order 1 − α α 3 2 p | V | , where α ∈ (0 , 1] is the fraction of queried edges out of the total number of edges. A quick comparison to Theorem 4 rev eals that T R E E L E T S TA R achie ves a sharper mistake bound for an y v alue of α . For instance, in order to obtain an optimality factor which is lo wer than p | V | , C C C C has to query in the worst case a fraction of edges that goes to one as | V | → ∞ . On top of this, our algorithms are faster and easier to implement —see Section 3.2. Next, we compare to query sets produced by lo w-stretch spanning trees. A lo w-stretch spanning tree achie ves a polylogarithmic optimality factor by querying | V | − 1 edge labels. The results in [9] sho w that we cannot hope to get a better optimality factor using a single low-stretch spanning tree combined by the analysis in (1). For a comparable amount Θ( | V | ) of queried labels, Theorem 2 This theoretical comparison is admittedly unfair , as C C C C has been designed to work in a harder setting than p -stochastic. Unfortunately , we are not aware of any other general activ e learning scheme for link classification to compare with. 8 4 offers the lar ger optimality factor | V | 1 / 3 . Ho wev er , we can get a constant optimality f actor by increasing the query set size to O ( | V | 3 / 2 ) . It is not clear how multiple low-stretch trees could be combined to get a similar scaling. 3.2 Complexity analysis and implementation W e now compute bounds on time and space requirements for our three algorithms. Recall the dif ferent lower bound conditions on the graph density that must hold to ensure that the query set size is not larger than the test set size. These were | E | ≥ 2 | V | − 2 + | V | 2 k 2 + | V | k for T R E E C U T T E R ( k ) in Theorem 2, | E | ≥ 2 | V | − 2 + 2 | V | 3 2 for S T A R M A K E R in Theorem 3, and | E | ≥ 2 | V | − 2 + 2 | V |− 1 k + 1 3 2 for T R E E L E T S T A R ( k ) in Theorem 4. Theorem 5. F or any input graph G = ( V , E ) which is dense enough to ensur e that the query set size is no lar ger than the test set size , the total time needed for pr edicting all test labels is: O ( | E | ) for T R E E C U T T E R ( k ) and for all k O | E | + | V | log | V | for S TA R M A K E R O | E | + | V | k log | V | k for T R E E L E T S T A R ( k ) and for all k . In particular , whenever k | E | = Ω( | V | log | V | ) we have that T R E E L E T S T A R ( k ) works in constant amortized time. F or all thr ee algorithms, the space r equired is always linear in the input gr aph size | E | . 4 Experiments In this preliminary set of experiments we only tested the predictiv e performance of T R E E C U T T E R ( | V | ) . This corresponds to querying only the edges of the initial spanning tree T and predicting all re- maining edges ( i, j ) via the parity of P ath T ( i, j ) . The spanning tree T used by T R E E C U T T E R is a shortest-path spanning tree generated by a breadth-first visit of the graph (assuming all edges ha ve unit length). As the choice of the starting node in the visit is arbitrary , we picked the highest degree node in the graph. Finally , we run through the adiacency list of each node in random order , which we empirically observed to impro ve performance. Our baseline is the heuristic ASymExp from [16] which, among the many spectral heuris- tics proposed there, turned out to perform best on all our datasets. W ith integer parameter z , ASymExp ( z ) predicts using a spectral transformation of the training sign matrix Y train , whose only non-zero entries are the signs of the training edges. The label of edge ( i, j ) is predicted using exp( Y train ( z )) i,j . Here exp Y train ( z ) = U z exp( D z ) U > z , where U z D z U > z is the spectral decom- position of Y train containing only the z largest eigen v alues and their corresponding eigen vectors. Follo wing [16], we ran ASymExp ( z ) with the v alues z = 1 , 5 , 10 , 15 . This heuristic uses the two- clustering bias as follows : expand exp( Y train ) in a series of powers Y n train . Then each Y n train ) i,j is a sum of values of paths of length n between i and j . Each path has value 0 if it contains at least 9 one test edge, otherwise its v alue equals the product of queried labels on the path edges. Hence, the sign of exp( Y train ) is the sign of a linear combination of path values, each corresponding to a prediction consistent with the tw o-clustering bias —compare this to the multiplicati ve rule used by T R E E C U T T E R . Note that ASymExp and the other spectral heuristics from [16] have all running times of order Ω | V | 2 . W e performed a first set of experiments on synthetic signed graphs created from a subset of the USPS digit recognition dataset. W e randomly selected 500 examples labeled “1” and 500 e xamples labeled “7” (these two classes are not straightforward to tell apart). Then, we created a graph using a k -NN rule with k = 100 . The edges were labeled as follows: all edges incident to nodes with the same USPS label were labeled +1 ; all edges incident to nodes with dif ferent USPS labels were labeled − 1 . Finally , we randomly pruned the positiv e edges so to achie ve an unbalance of about 20% between the two classes. 3 Starting from this edge label assignment, which is consistent with the two-clustering associated with the USPS labels, we generated a p -stochastic label assignment by flipping the labels of a random subset of the edges. Specifically , we used the three follo wing synthetic datasets: DEL T A0: No flippings ( p = 0 ), 1 , 000 nodes and 9 , 138 edges; DEL T A100: 100 randomly chosen labels of DEL T A0 are flipped; DEL T A250: 250 randomly chosen labels of DEL T A0 are flipped. W e also used three real-world datasets: MO VIELENS: A signed graph we created using Movielens ratings. 4 W e first normalized the ratings by subtracting from each user rating the av erage rating of that user . Then, we created a user-user matrix of cosine distance similarities. This matrix was sparsified by zeroing each entry smaller than 0 . 1 and removing all self-loops. Finally , we took the sign of each non-zero entry . The resulting graph has 6 , 040 nodes and 824 , 818 edges ( 12 . 6% of which are neg ativ e). SLASHDO T : The biggest strongly connected component of a snapshot of the Slashdot social network, 5 similar to the one used in [16]. This graph has 26 , 996 nodes and 290 , 509 edges ( 24 . 7% of which are negati ve). EPINIONS: The biggest strongly connected component of a snapshot of the Epinions signed network, 6 similar to the one used in [18, 17]. This graph has 41 , 441 nodes and 565 , 900 edges ( 26 . 2% of which are ne gati ve). Slashdot and Epinions are originally directed graphs. W e remov ed the reciprocal edges with mismatching labels (which turned out to be only a fe w), and considered the remaining edges as undirected. The following table summarizes the key statistics of each dataset: Neg. is the fraction of neg- ati ve edges, | V | / | E | is the fraction of edges queried by T R E E C U T T E R ( | V | ), and A vgdeg is the av erage degree of the nodes of the netw ork. 3 This is similar to the class unbalance of real-world signed networks —see belo w . 4 www.grouplens.org/system/files/ml-1m.zip . 5 snap.stanford.edu/data/soc-sign-Slashdot081106.html . 6 snap.stanford.edu/data/soc-sign-epinions.html . 10 0.4 0.6 0.8 1 10 20 30 40 50 F-MEASURE (%) TRAINING SET SIZE (%) DELTA0 ASymExp z=1 ASymExp z=5 ASymExp z=10 ASymExp z=15 TreeCutter 0.4 0.6 0.8 1 10 20 30 40 50 F-MEASURE (%) TRAINING SET SIZE (%) DELTA100 ASymExp z=1 ASymExp z=5 ASymExp z=10 ASymExp z=15 TreeCutter 0.4 0.6 0.8 1 10 20 30 40 50 F-MEASURE (%) TRAINING SET SIZE (%) DELTA250 ASymExp z=1 ASymExp z=5 ASymExp z=10 ASymExp z=15 TreeCutter 0.2 0.4 0.6 1 2 3 4 5 6 7 8 9 10 F-MEASURE (%) TRAINING SET SIZE (%) MOVIELENS ASymExp z=1 ASymExp z=5 ASymExp z=10 ASymExp z=15 TreeCutter 0.2 0.4 0.6 10 20 30 40 50 F-MEASURE (%) TRAINING SET SIZE (%) SLASHDOT ASymExp z=1 ASymExp z=5 ASymExp z=10 ASymExp z=15 TreeCutter 0.2 0.4 0.6 0.8 10 20 30 40 50 F-MEASURE (%) TRAINING SET SIZE (%) EPINIONS ASymExp z=1 ASymExp z=5 ASymExp z=10 ASymExp z=15 TreeCutter Figure 3: F-measure against training set size for T R E E C U T T E R ( | V | ) and ASymExp ( z ) with different v alues of z on both synthetic and real-world datasets. By construction, TR E E C U T T ER never makes a mistake when the labeling is consistent with a two-clustering. So on DEL T A0 TR E E C U T T E R does not make mistakes whenev er the training set contains at least one spanning tree. W ith the exception of EPINIONS, TR E E C U T T E R outperforms ASymExp using a much smaller training set. W e conjecture that ASymExp responds to the bias not as well as T R E E C U T T E R , which on the other hand is less robust than ASymExp to bias violations (supposedly , the labeling of EPINIONS). Dataset | V | | E | Neg. | V | / | E | A vgdeg DEL T A0 1000 9138 21.9% 10.9% 18.2 DEL T A100 1000 9138 22.7% 10.9% 18.2 DEL T A250 1000 9138 23.5% 10.9% 18.2 SLASHDO T 26996 290509 24.7% 9.2% 21.6 EPINIONS 41441 565900 26.2% 7.3% 27.4 MO VIELENS 6040 824818 12.6% 0.7% 273.2 Our results are summarized in Figure 3, where we plot F-measure (preferable to accuracy due to the class unbalance) against the fraction of training (or query) set size. On all datasets, but MO VIELENS, the training set size for ASymExp ranges across the values 5%, 10%, 25%, and 50%. Since MO VIELENS has a higher density , we decided to reduce those fractions to 1%, 3%, 5% and 10%. T R E E C U T T E R ( | V | ) uses a single spanning tree, and thus we only hav e a single query set size value. All results are av eraged ov er ten runs of the algorithms. The randomness in ASymExp is due to the random dra w of the training set. The randomness in T R E E C U T T E R ( | V | ) is caused by the randomized breadth-first visit. 5 Conclusions and work in pr ogress W e hav e built on the recent work [7], so as to generalize the results contained therein to query budgets larger than | V | − 1 (the edge set size of a spanning tree). W e also provided algorithms which are easier to implement than lo w-stretch spanning trees. A research a venue we are currently 11 exploring is whether we can combine the edge information with information possibly contained in the nodes of a network. The suite of papers [2, 4, 5, 3, 6] is a good starting for this in vestigation. Refer ences [1] Cartwright, D. and Harary , F . Structure balance: A generalization of Heider’ s theory . Psy- cholo gical r evie w , 63(5):277–293, 1956. [2] Cesa-Bianchi, N., Gentile, C., V itale, F . Fast and optimal prediction of a labeled tree. Proc. of of the 22nd Conference on Learning Theory (COL T 2009). [3] Cesa-Bianchi, N., Gentile, C., V itale, F . Predicting the labels of an unknown graph via adap- ti ve e xploration. Theoretical Computer Science , special issue on Algorithmic Learning The- ory , 412/19 (2011), pp. 1791–1804. [4] Cesa-Bianchi, N., Gentile, C., V itale, F ., Zappella, G. Activ e learning on trees and graphs. Proc. of the 23rd Conference on Learning Theory (COL T 2010). [5] Cesa-Bianchi, N., Gentile, C., V itale, F ., Zappella, G. Random spanning trees and the pre- diction of weighted graphs. Proc. of the 27th International Conference on Machine Learning (ICML 2010). [6] Cesa-Bianchi, N., Gentile, C., V itale, F ., Zappella, G. See the tree through the lines: the Shazoo algorithm Proc. of the 25th conference on Neural Information processing Systems (NIPS 2011). [7] Cesa-Bianchi, N., Gentile, C., V itale, F ., Zappella, G. A correlation clustering approach to link classification in signed networks. In Pr oceedings of the 25th confer ence on learning theory (COLT 2012) . [8] Chiang, K., Natarajan, N., T ew ari, A., and Dhillon, I. Exploiting longer cycles for link prediction in signed networks. In Pr oceedings of the 20th A CM Confer ence on Information and Knowledge Manag ement (CIKM) . A CM, 2011. [9] Elkin, M., Emek, Y ., Spielman, D.A., and T eng, S.-H. Lo wer -stretch spanning trees. SIAM J ournal on Computing , 38(2):608–628, 2010. [10] Facchetti, G., Iacono, G., and Altafini, C. Computing global structural balance in large-scale signed social networks. PN AS , 2011. [11] Giotis, I. and Guruswami, V . Correlation clustering with a fixed number of clusters. In Pr oceedings of the Seventeenth Annual ACM-SIAM Symposium on Discr ete Algorithms , pp. 1167–1176. A CM, 2006. [12] Guha, R., Kumar , R., Raghav an, P ., and T omkins, A. Propagation of trust and distrust. In Pr oceedings of the 13th international confer ence on W orld W ide W eb , pp. 403–412. A CM, 2004. 12 [13] Harary , F . On the notion of balance of a signed graph. Michigan Mathematical J ournal , 2 (2):143–146, 1953. [14] Heider , F . Attitude and cognitiv e org anization. J. Psychol , 21:107–122, 1946. [15] Hou, Y .P . Bounds for the least Laplacian eigen value of a signed graph. Acta Mathematica Sinica , 21(4):955–960, 2005. [16] Kunegis, J., Lommatzsch, A., and Bauckhage, C. The Slashdot Zoo: Mining a social netw ork with negati ve edges. In Pr oceedings of the 18th International Conference on W orld W ide W eb , pp. 741–750. A CM, 2009. [17] Leskov ec, J., Huttenlocher , D., and Kleinberg, J. T rust-aware bootstrapping of recommender systems. In Pr oceedings of ECAI 2006 W orkshop on Recommender Systems , pp. 29–33. ECAI, 2006. [18] Leskov ec, J., Huttenlocher , D., and Kleinberg, J. Signed networks in social media. In Pr o- ceedings of the 28th International Confer ence on Human F actors in Computing Systems , pp. 1361–1370. A CM, 2010a. [19] Leskov ec, J., Huttenlocher , D., and Kleinberg, J. Predicting positi ve and negati ve links in online social networks. In Pr oceedings of the 19th International Conference on W orld W ide W eb , pp. 641–650. ACM, 2010b . [20] V on Luxb urg, U. A tutorial on spectral clustering. Statistics and Computing , 17(4):395–416, 2007. 6 A ppendix with missing pr oofs Pr oof of Theor em 2. By Fact 2, it suffices to show that the length of each path used for predicting the test edges is bounded by 4 k + 1 . For each T 0 ∈ T , we ha ve D T 0 ≤ 2 k , since the height of each subree is not bigger than k . Hence, any test edge incident to vertices of the same subtree T 0 ∈ T is predicted (Line 5 in Figure 1) using a path whose length is bounded by 2 k < 4 k + 1 . Any test edge ( u, v ) incident to vertices belonging to two dif ferent subtrees T 0 , T 00 ∈ T is predicted (Line 11 in Figure 1) using a path whose length is bounded by D T 0 + D T 00 + 1 ≤ 2 k + 2 k + 1 = 4 k + 1 , where the extra +1 is due to the query edge ( i 0 , i 00 ) connecting T 0 to T 00 (Line 9 in Figure 1). In order to prov e that | V | − 1 + | V | 2 2 k 2 + | V | 2 k is an upper bound on the query set size, observe that each query edge either belongs to T or connects a pair of distinct subtrees contained in T . The number of edges in T is | V | − 1 , and the number of the remaining query edges is bounded by the number of distinct pairs of subtrees contained in |T | , which can be calculated as follo ws. First of all, note that only the last subtree returned by E X T R AC T T R E E L E T may hav e a height smaller than k , all the others must ha ve height k . Note also that each subtree of height k must contain at least k + 1 v ertices of V T , while the subtree of T having height smaller than k (if present) must contain at least one v ertex. Hence, the number of distinct pairs of subtrees contained in T can be upper bounded by |T | ( |T | − 1) 2 ≤ 1 2 | V | − 1 k + 1 + 1 | V | − 1 k + 1 ≤ | V | 2 k 2 + | V | k . 13 This sho ws that the query set size cannot be larger than | V | − 1 + | V | 2 2 k 2 + | V | 2 k . Finally , observ e that D T ≤ 2 D G because of the breadth-first visit generating T . If D T ≤ k , the subroutine E X T R A C T T R E E L E T is in voked only once, and the algorithm does not ask for any additional label of E G \ E T (the query set size equals | V | − 1 ). In this case E M is clearly upper bounded by 2 D G p | E | . Pr oof of Theor em 3. In order to prov e the claimed mistake bound, it suffices to sho w that each test edge is predicted with a path whose length is at most 5 . This is easily seen by the fact that summing the diameter of two stars plus the query edge ( i 0 , i 00 ) that connects them is equal to 2 + 2 + 1 = 5 , which is therefore the diameter of the tree made up by two stars connected by the additional query edge. W e continue by bounding from the abo ve the query set size. Let S j be the j -th star returned by the j -th call to E X T R A C T S T A R . The ov erall number of query edges can be bounded by | V | − 1 + z , where | V | − 1 serv es as an upper bound on the number of edges forming all the stars output by E X T R A C T S TA R , and z is the sum ov er j = 1 , 2 , . . . of the number of stars S j 0 with j 0 > j (i.e., j 0 is created later than j ) connected to S j by at least one edge. No w , for any giv en j , the number of stars S j 0 with j 0 > j connected to S j by at least one edge cannot be larger that min {| V | , | V S j | 2 } . T o see this, note that if there were a leaf q of S j connected to more than | V S j | − 1 vertices not pre viously included in any star , then E X T R AC T S TA R would have returned a star centered in q instead. The repeated ex ecution of E X T R A C T S T A R can indeed be seen as partitioning V . Let P be the set of all partitions of V . W ith this notation in hand, we can bound z as follows: z ≤ max P ∈P | P | X j =1 min z 2 j ( P ) , | V | (2) where z j ( P ) is the number of nodes contained in the the j -th element of the partition P , corre- sponding to the number of nodes in S j . Since P | P | j =1 z j ( P ) = | V | for any P ∈ P , it is easy to see that the partition P ∗ maximizing the abo ve expression is such that z j ( P ∗ ) = p | V | for all j , implying | P ∗ | = p | V | . W e conclude that the query set size is bounded by | V | − 1 + | V | 3 2 , as claimed. Pr oof of Theor em 4. If the height of T is not larger than k , then E X T R A C T T R E E L E T is in v oked only once and T contains the single tree T . The statement then trivially follo ws from the fact that the length of the longest path in T cannot be larger than twice the diameter of G . Observe that in this case | V G 0 | = 1 . W e continue with the case when the height of T is larger than k . W e ha ve that the length of each path used in the prediction phase is bounded by 1 plus the sum of the diameters of two trees of T . Since these two trees are not higher than k , the mistak e bound follows from F act 2. Finally , we combine the upper bound on the query set size in the statement of Theorem 3 with the fact that each verte x of V G 0 corresponds to a tree of T containing at least k + 1 v ertices of G . This implies | V G 0 | ≤ | V | k +1 , and the claim on the query set size of T R E E L E T S T A R follows. Pr oof of Theor em 5. A common tool shared by all three implementations is a preprocessing step. Gi ven a subtree T 0 of the input graph G we preliminarily perform a visit of all its v ertices (e.g., a depth-first visit) tagging each node by a binary label y i as follo ws. W e start off from an arbitrary 14 node i ∈ V T 0 , and tag it y i = +1 . Then, each adjacent v ertex j in T 0 is tagged by y j = y i · Y i,j . The ke y observ ation is that, after all nodes in T 0 hav e been labeled this way , for any pair of v ertices u, v ∈ V T 0 we ha ve π T 0 ( i, j ) = y i · y j , i.e., we can easily compute the parity of P ath T 0 ( u, v ) in constant time. The total time tak en for labeling all vertices in V T 0 is therefore O ( | V T 0 | ) . W ith the above fast tagging tool in hand, we are ready to sketch the implementation details of the three algorithms. Part 1. W e dra w the spanning tree T of G and tag as described abo ve all its v ertices in time O ( | V | ) . W e can e xecute the first 6 lines of the pseudocode in Figure 5 in time O ( | E | ) as follo ws. For each subtree T i ⊂ T rooted at i returned by E X T R AC T T R E E L E T , we assign to each of its nodes a pointer to its root i . This w ay , giv en any pair of vertices, we can no w determine whether they belong to same subtree in constant time. W e also mark node i and all the leav es of each subtree. This operation is useful when visiting each subtree starting from its root. Then the set T contains just the roots of all the subtree returned by E X T R AC T T R E E L E T . This takes O ( | V T | ) time. For each T 0 ∈ T we also mark each edge in E T 0 so as to determine in constant time whether or not it is part of T 0 . W e visit the nodes of each subtree T 0 whose root is in T , and for any edge ( i, j ) connecting two v ertices of T 0 , we predict in constant time Y i,j by y i · y j . It is then easy to see that the total time it takes to compute these predictions on all subtrees returned by E X T R AC T T R E E L E T is O ( | E | ) . T o finish up the rest, we allocate a v ector v of | V | records, each record v i storing only one edge in E G and its label. For each verte x r ∈ T we repeat the follo wing steps. W e visit the subtree T 0 rooted at r . F or brevity , denote by ro ot( i ) the root of the subtree which i belongs to. For an y edge connecting the currently visited node i to a node j 6∈ V T 0 , we perform the following operations: if v root( j ) is empty , we query the label Y i,j and insert edge ( i, j ) together with Y i,j in v root( j ) . If instead v root( j ) is not empty , we set ( i, j ) to be part of the test set and predict its label as ˆ Y i,j ← π T ( i, z 0 ) · Y z 0 ,z 00 · π T ( z 00 , j ) = y i · y z 0 · Y z 0 ,z 00 · y z 00 · y j , where ( z 0 , z 00 ) is the edge contained in v root( j ) . W e mark each predicted edge so as to av oid to predict its label twice. W e finally dispose the content of vector v . The e xecution of all these operations takes time overall linear in | E | , thereby concluding the proof of Part 1. Part 2. W e rely on the notation just introduced. W e exploit an additional data structure, which takes extra O ( | V | ) space. This is a heap H whose records h i contain references to vertices i ∈ V . Furthermore, we also create a link connecting i to record h i . The priority k ey ruling heap H is the degree of each verte x referred to by its rec ords. W ith this data structure in hand, we are able to find the vertex having the highest degree (i.e., the top element of the heap) in constant time. The heap also allo ws us to execute in logarithmic time a pop operation, which eliminates the top element from the heap. In order to mimic the execution of the algorithm, we perform the following operations. W e create a star S centered at the vertex referred to by the top element of H connecting it with all the adjacent vertices in G . W e mark as “not-in-use” each leaf of S . Finally , we eliminate the element pointing to the center of S from H (via a pop operation) and create a pointer from each leaf of S to its central vertex. W e keep creating such star graphs until H becomes empty . Compared to the creation of the first star , all subsequent stars essentially require the same sequence of operations. The only difference with the former is that when the top element of H is marked as not-in-use, we simply pop it a way . This is because any ne w star that we create is centered at a node that is 15 not part of any previously generated star . The time it takes to perform the above operations is O ( | V | log | V | ) . Once we ha ve created all the stars, we predict all the test edges the very same way as we described for T R E E C U T T E R (labeling the v ertices of each star , using a set T containing all the star centers and the vector v for computing the predictions). Since for each edge we perform only a constant number of operations, the proof of Part 2 is concluded. Part 3. T R E E L E T S TA R (k) can be implemented by combining the implementation of T R E E - C U T T E R with the implementation of S T A R M A K E R . In a first phase, the algorithm works as T R E E - C U T T E R , creating a set T containing the roots of all the subtrees with diameter bounded by k . W e label all the vertices of each subtree and create a pointer from each node i to ro ot( i ) . Then, we visit all these subtrees and create a graph G 0 = ( V 0 , E 0 ) ha ving the following properties: V 0 coincides with T , and there exists an edge ( i, j ) ∈ E 0 if and only if there exists at least one edge connecting the subtree rooted at i to the subtree rooted at j . W e also use two vectors u and u 0 , both having | V | components, mapping each vertex in V to a vertex in V 0 , and vicev ersa. Using H on G 0 , the algorithm splits the whole set of subtrees into stars of subtrees. The root of the subtree which is the center of each star is stored in a set S ⊆ T . In addition to these operations, we create a pointer from each vertex of S to r . F or each r ∈ S , the algorithm predicts the labels of all edges connecting pairs of vertices belonging to S using a vector v as for T R E E C U T T E R . Then, it performs a visit of S for the purpose of relabeling all its vertices according to the query set edges that connect the subtree in the center of S with all its other subtrees. Finally , for each vertex of S , we use v ector v as in T R E E C U T T E R and S TA R M A K E R for selecting the query set edges connecting the stars of subtrees so created and for predicting all the remaining test edges. No w , G 0 is a graph that can be created in O ( | E | ) time. The time it takes for operating with H on G 0 is O ( | V 0 | log | V 0 | ) = O | V | k log | V | k , the equality deriving from the fact that each subtree with diameter equal to k contains at least k + 1 vertices, thereby making | V 0 | ≤ | V | k . Since the remaining operations need constant time per edge in E , this concludes the proof. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment