Identification of Literary Movements Using Complex Networks to Represent Texts
The use of statistical methods to analyze large databases of text has been useful to unveil patterns of human behavior and establish historical links between cultures and languages. In this study, we identify literary movements by treating books published from 1590 to 1922 as complex networks, whose metrics were analyzed with multivariate techniques to generate six clusters of books. The latter correspond to time periods coinciding with relevant literary movements over the last 5 centuries. The most important factor contributing to the distinction between different literary styles was {the average shortest path length (particularly, the asymmetry of the distribution)}. Furthermore, over time there has been a trend toward larger average shortest path lengths, which is correlated with increased syntactic complexity, and a more uniform use of the words reflected in a smaller power-law coefficient for the distribution of word frequency. Changes in literary style were also found to be driven by opposition to earlier writing styles, as revealed by the analysis performed with geometrical concepts. The approaches adopted here are generic and may be extended to analyze a number of features of languages and cultures.
💡 Research Summary
The paper presents a novel methodology for identifying literary movements by modeling texts as complex networks and analyzing network metrics with multivariate statistical techniques. The authors compiled a corpus of 77 books published between 1590 and 1922 from the Gutenberg Project. After removing punctuation and low‑content function words, they lemmatized the remaining tokens using the MXPOST part‑of‑speech tagger, thereby collapsing inflected forms into canonical lemmas. Adjacent words in the original reading order were linked to form a directed word‑co‑occurrence network, where each node represents a unique lemma and each edge represents a sequential adjacency in the text.
From each network, a set of eleven measurements was extracted: the number of nodes (vocabulary size N), the power‑law exponent γ of the degree (frequency) distribution, assortativity Γ (degree‑degree correlation), clustering coefficient C (and its weighted version C^w), average shortest‑path length l_i for each node, and derived statistics of the l_i distribution—average h_l, standard deviation Δl, weighted average h_l^w, and the third moment (asymmetry) ς(l). These metrics capture both lexical richness and structural complexity of the texts.
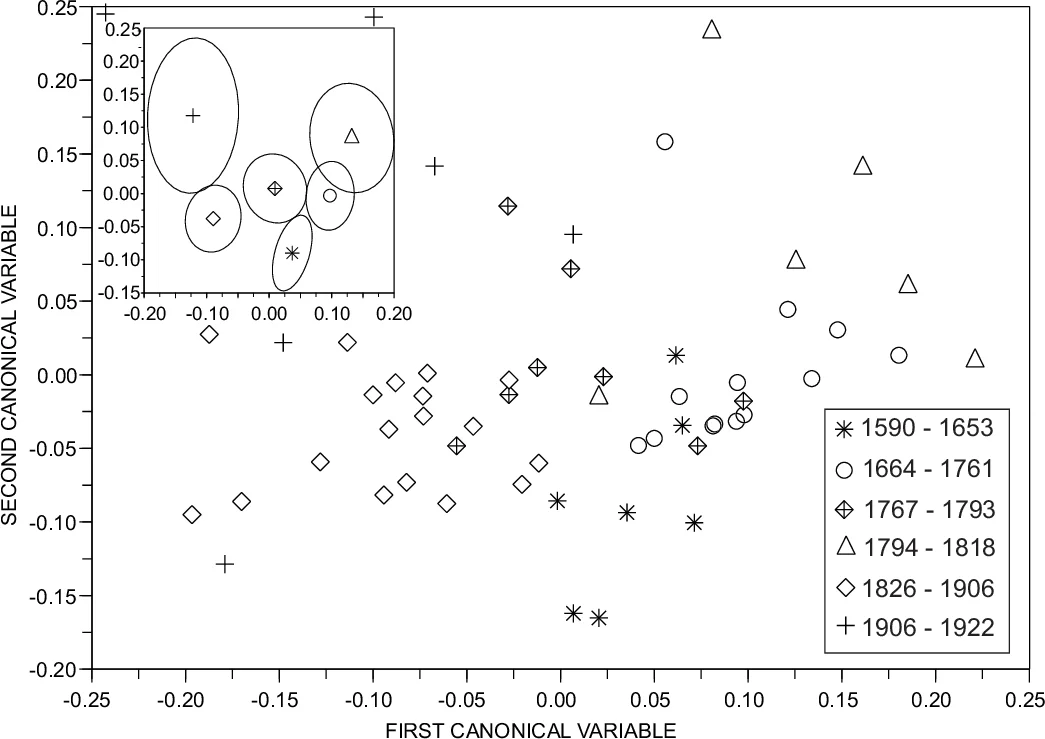
To uncover temporal patterns, the authors first performed an arbitrary division of the corpus into six 50‑year intervals and visualized the data using Canonical Variate Analysis (CVA) and Principal Component Analysis (PCA). Overlap among clusters indicated that simple chronological binning was insufficient. Consequently, they optimized the number and boundaries of clusters by maximizing two cluster‑quality indices: the simplified silhouette (SWC) and the Dunn index (DN). The optimal solution, supported by statistical significance testing, yielded six well‑separated clusters with virtually no overlap.
Mapping these clusters onto historical periods revealed a striking correspondence with established literary movements: (1) 1590‑1653 aligns with the Elizabethan era, (2) 1664‑1761 and 1767‑1793 correspond to Enlightenment/Neoclassicism, (3) 1794‑1818 matches Gothic fiction, (4) 1826‑1906 covers Realism and Naturalism, and (5) 1906‑1922 matches Modernism. Hierarchical clustering based on the “Words” distance further confirmed the smooth progression of styles, except for a pronounced shift between the Gothic and Realist periods, which the authors attribute to the cultural upheaval of the French Revolution.
Feature‑importance analysis identified the asymmetry of the average shortest‑path length distribution (ς(l)) and vocabulary size N as the most discriminative variables across clusters. In a second analysis that accounted for inter‑feature dependencies, the clustering coefficient (both C and its weighted version C^w) emerged as the primary driver of separation. The authors interpret C as reflecting the degree to which words are confined to specific contexts versus being generic; thus, changes in C indicate evolving lexical specificity over time.
Temporal trends show a gradual increase in average shortest‑path length (h_l), suggesting growing syntactic complexity in later works, while the power‑law exponent γ declines, indicating a more uniform word‑frequency distribution. The latter implies that the gap between high‑frequency and low‑frequency words narrows as literature evolves. The authors also demonstrate that stylistic transitions between consecutive clusters are often driven by “opposition” to preceding styles, a concept quantified through geometric analysis of cluster centroids (see Appendix A).
Overall, the study demonstrates that complex‑network representations of texts, combined with multivariate clustering, can objectively recover known literary periods and uncover quantitative signatures of stylistic evolution. The methodology is generic and can be extended to other linguistic or cultural analyses, such as authorship attribution, sentiment dynamics, or thematic evolution across corpora.
Comments & Academic Discussion
Loading comments...
Leave a Comment