An alternative text representation to TF-IDF and Bag-of-Words
In text mining, information retrieval, and machine learning, text documents are commonly represented through variants of sparse Bag of Words (sBoW) vectors (e.g. TF-IDF). Although simple and intuitive, sBoW style representations suffer from their inh…
Authors: Zhixiang (Eddie) Xu, Minmin Chen, Kilian Q. Weinberger
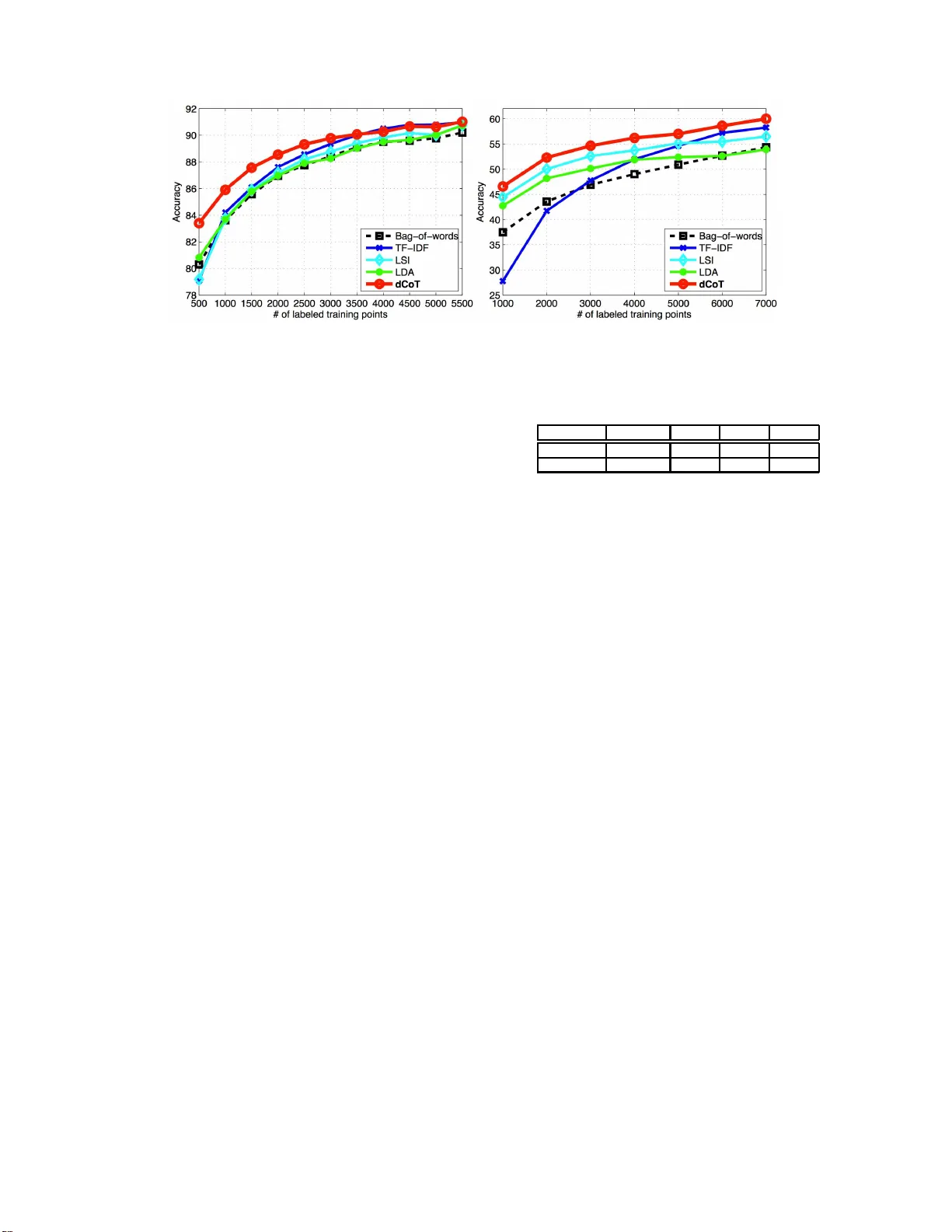
An alternative text r epresentation to TF-IDF and Bag-of-W or ds ∗ Zhixiang (Eddie ) Xu W ashington Univ ersity in St. Louis One Brookings Dr . St. Loui s, MO , USA zhixiang.xu@wustl.edu Minmin Chen W ashington Univ ersity in St. Louis One Brookings Dr . St. Loui s, MO , USA chenm@wustl.edu Kilian Q. W einb erger W ashington Univ ersity in St. Louis One Brookings Dr . St. Loui s, MO , USA kilian@wustl.edu F ei Sha Unive rsity of Southern Calif ornia 941 W est 37th Place Los Angel es, CA, USA f eisha@u sc.edu ABSTRA CT In text mining, informa tion retriev al , and mac hine l earning, text docu ments are co mmonly represented through v ariants of sp arse Bag of Wor ds (sBoW) vectors ( e.g. TF-IDF [1]). Although simple and intuitiv e, sBoW style rep resentations suffer from their inherent over-sparsi ty and fail to capture w ord-level synonym y and p olysemy . Esp ecially when lab eled data is limited ( e.g. in document classification), or the tex t docu ments are short ( e.g. emails or abstracts), many fea- tures are rarely observed within the training corpus. This leads to ov erfitting and reduced generalization accuracy . In this pap er we prop ose Dense Cohort of T erms (dCoT), an unsup ervised algori thm to learn impro v ed sBoW do cument features. dCoT exp licitly mo dels ab sent wo rds by remo ving and reconstructing ra ndom sub -sets of words in th e unla- b eled corpus. With this approach, dCoT learns t o recon- struct frequent w ords from co-occurring i nfrequent words and maps the high dimensional sparse sBoW vectors in to a lo w-dimensional dense representatio n. W e show that the feature remov al can b e marginal ized out and that the re con- struction can b e solved f or in closed-form. W e demonstrate empirically , on several b enchmark datasets, that dCoT fea- tures significan tly imp rove the classification accuracy a cross sever al d o cument classification tasks. ∗ A modified vers ion of our CIKM 20 12 paper: F r om sBoW to dCoT, Mar ginal i ze d Enc o ders for T ext R ep r esentation Permission to make digital or hard copies of all or part of this work for personal or classroom use is grant ed without fee provide d that copies are not made or distrib uted for profit or commercial adv antage and that copies bear this notice and the full cita tion on the firs t pag e. T o cop y otherwise, to republi sh, to post on serve rs or to redistrib ute to lists, requir es prior speci fic permission and/or a fee. CIKM’12, October 29–Nov ember 2, 2012, Maui, HI, USA. Copyri ght 2012 A CM 978-1-4503-1156-4/12 /10 .. .$15.00. Categories and Subject Descriptors H.3 [ Information Storage and Retriev al ]: Miscella- neous; I.5.2 [ P attern Recognition ]: Design Metho d ol- ogy— F e atur e evaluation and sele ction General T erms Mac hine L earning for IR Keyw ords Denoising Autoenco der, Marginalized, Stac k ed, T ext f ea- tures 1. INTR ODUCTION The feature representation of text do cuments pla ys a criti- cal role in many applications of data-mining and information retriev a l. The sp arse Bag of Wor ds (sBoW) representatio n is arguably one of the most commonly u sed and effective approac hes. Eac h d ocument is represented by a high di- mensional sparse v ector, where eac h dimension co rrespon d s to the term frequency of a unique w ord within a dictionary or hash-table [2]. A natural extension is TF-IDF [1], where the term frequency counts are discounted by t h e inverse- docu ment-frequencies. D espite its wide-spread use with text and image data [3], sBoW does hav e some severe limita tions, mainly due to its often excessive sparsity . Although the Oxford English Dictionary contains approx- imately 6 00 , 000 unique words, it is fair to s a y that the essence of most written text can b e exp ressed with a far smaller vocabulary ( e.g. 5000 − 10000 unique wo rds). F or ex- ample the w ords splendid, sp e ctac ular, terrific, glorious, r e- splendent are all to some degree synonymous with the w ord go o d . How ever, as sBoW does not capt u re s ynonym y , a doc- ument that uses “splendid” will be considered dissimilar from a d ocument th at uses the w ord “terrific” . A classifier, trained to predict the sentimen t of a d ocum ent, w ould hav e to b e exp osed to a ve ry large set of lab eled examples to learn that all these w ords are predictive to w ards a positive sentimen t. In th is paper, we prop ose a no v el feature learning algo- rithm that directly a ddresses the p rob lems of excess ive spar- sit y in sBoW represen tations. Our algorithm, w hich we refer to as Dense Cohort of T erms (dCoT), maps high- dimensional (o verly) sp arse vectors into a lo w-dimensional dense repre- senta tion. The mapp ing is trained to reconstruct frequent from in frequent w ords. The training process is en tirely un - sup ervised, as we generate training instances by rand omly and rep eatedly removing common w ords from text do cu- ments. These remo v ed words are then reconstructed from the remaining text. In this pap er we show that the fea ture remo v al p rocess ca n b e marginalized out and the reconstruc- tion can be solve d for in closed form. The resulting algo- rithm is a closed-form transformation of the orig inal sBoW features, which is extremely fast to t rain (on t h e ord er of seconds) and apply ( milliseco nds). Our emp irical results indicate t hat dCoT is u seful for sev- eral reasons. First, it p ro vides researc hers with an efficient and con venien t metho d to learn b etter feature representa- tion for sBoW do cuments, and can b e used in a large v a- riet y of data-mining, learning and retriev al t asks. Second, w e demonstrate that it clearly outp erforms existing do cu- ment represen tations [1, 4, 5 ] on several classificatio n tasks. Finally , it is much faster than most comp eting alg orithms. 2. RELA TED WORK Over the years, a great number of mo dels hav e b een de- velo p ed to describ e textual corp ora, including vector space mod els [6, 7, 8, 9, 10 ], and topic models [4, 11, 12, 13]. V ec- tor space mo dels reduce each do cument in the corpu s to a vector of real numbers, eac h of whic h reflects the counts of an unordered collec tion of w ords. Among them, the most p opular one is the TF-I DF scheme [8], where eac h dimen- sion of the feature vector computes the term frequency count factored by the inverse do cument frequency coun t. By do wn- w eigh ting terms t h at are common in the e ntire corpus, it ef- fectiv ely iden tifies a subset of terms that are discriminativ e for do cuments in the corpus. Though simple and efficient, TF-IDF reveals little of the correlations betw een terms, t hus fails to capture some basic linguistic notions such as syn- onym y and p olysem y . Latent Semantic Index (LSI) [5] at- tempts to o verco me this. It applies Singular V al ue Decom- p osition (SVD) [14] to th e TF-IDF (or sBoW) features t o find a so-called laten t semantic space th at retains most of the vari ances in the corpus. Each feature in the new space is a linear combinatio n of the original TF-IDF features, which naturally handles the syn onym y problem. T opic mo deling d evelo ps generativ e statistical mo dels t o disco ver the hidden “topic” t h at o ccur in the corpus. Proba- bilistic LSI [11], whic h is proposed as an alternative to LSI, mod els each docu ment as a mixture of a fixed set of topics, and eac h w ord as a sample generated from a single top ic. The limitation of probabilistic LS I is th at th e mix t ure of topics is modeled explicitly for each training data using a large set of individual parameters, h en ce, there is no nat- ural wa y to assig n probabilities to u nseen do cuments. La- tent D irichlet Allocation (LDA) [4] solves the problem by introducing a D iric hlet prior on th e topic distribution, and treating the mixing w eigh ts as multinomia l distributed ran- dom va riables. It is probably the most co mmonly used topic mod els now ada ys, and the p osterior Diric hlet parameters are often used as the low dimensional represen tation f or v a rious tasks [4]. [15] use n on-linear dimensionality red uction [16] to embed text data into a l o w dimensional space, while pre- serving p air-wise distances betw een do cuments. It is fair to sa y that their approac h is computationally most demanding. Similarly to LSI, pLSI and LDA, our algorithm also maps the sparse sBo W features into a low dimensional dense rep - resen tation. Ho w ever it is fas ter to train and addresses the problem of synonym y more ex plicitly . 3. dCoT First, we introduce n otations that will b e used through- out the pap er. Let D = { w 1 , · · · , w d } b e the dictionary of w ords th at app ear in the tex t corpus, with size d = | D | . Eac h in p ut d o cument is represented as a vector x ∈ R d , where eac h dimension x j counts th e app earance of w ord w j in this do cu ment. Let X = [ x 1 , · · · , x n ] denote the corpus. Assume that the first n l ≪ n do cuments are accompanied by corresp onding labels { y 1 , · · · , y n l } ∈ Y , drawn from some join t d istribution D . In th is section w e introduce the algorithm dCoT, which translates sparse sBoW vectors x ∈ R d into denser and low er dimensional prototype vectors. W e first d efi ne the concept of pr ototyp e terms and then d erive the algori thm step- by- step. Protot ype fe atures. Let P = { w p 1 , · · · , w p r } ⊂ D , with | P | = r and r ≪ d , denote a strict subset of th e vo- cabulary D , whic h w e refer to a s pr ototyp e terms. Our algo- rithm aims to “translate” eac h term in D in to one or more of these prototype wo rds with similar meaning. Several c hoices are p ossible to iden tify P , but a typical heuristic is to pic k the r most frequent terms in D . The most frequ ent terms can be thought of as represen tativ e ex pressions for sets of synonyms — e. g. the frequent word go o d represents the rare w ords splendid, sp e ctacular, terrific, glorious . F or this choi ce of P , dCoT translates r ar e w ords into fr e quent w ords. Corruption. The goal of dCoT is to learn a mapping W : R d → R r , which “ translates” t he original sBoW vec- tors in R d into a combination of prototyp e terms in R r . Our t raining of W is based on one crucial insight: If a pro- totype t erm already exists in some input x , W should be able to predict it from the remaining t erms in x . W e there- fore artificially create a sup erv ised dataset from u nlab eled data b y r emoving ( i .e. setting to zero) eac h term in x with some p robab ility (1 − p ) . W e perform this m times and ref er to t h e resulting corrupted vectors as ˆ x 1 , . . . , ˆ x m . W e not only remov e protot ype features but all features, to generate more diverse input samples. (In the subsequent section w e will show th at in fact w e nev er actually h a ve to create this corrupted d ataset, as its creation can b e marginalized out entirel y — but for now let us pretend it actually exists.) Reconstruction. In addition to the corruptions, for eac h input x i w e create a sub -vector ¯ x i = [ x p 1 , · · · , x p r ] ⊤ ∈ R r whic h only co ntai ns its protot ype features. A mapp in g W ∈ R r × d is then learned to reconstructs the protot yp e features from the corrupted ver sion ˆ x i , by minimizing the squ ared reconstruction erro r, 1 2 nm n X i =1 m X j =1 k ¯ x i − W ˆ x j i k 2 . (1) T o simplify notatio n, w e assume that a constan t feature i s added to the corrupted input, ˆ x i = [ ˆ x i ; 1], and an appropri- ate b ias is incorp orated within the mapping W = [ W , b ]. Note that the constant feature is never corrupted. The bias term has t he imp ortan t task of reconstruct in g the av erage occurren ce of th e prototype features. Let us define a design matrix X = [ ¯ x 1 , · · · , ¯ x 1 | {z } m , · · · , ¯ x n , · · · , ¯ x n | {z } m ] ∈ R r × nm as th e m copies of the prototype features of the input s. Sim- ilarly , we denote the m corruptions of the original inputs as b X = [ ˆ x 1 1 , · · · , ˆ x m 1 | {z } m , · · · , ˆ x 1 n , · · · , ˆ x m n | {z } m ] ∈ R d × nm . With this n o- tation, th e loss in eq. (1) redu ces to 1 2 nm k X − W b X k 2 F , (2) where k · k 2 F denotes the s quared F robenius norm. The solu- tion to (2) can b e obtained under closed-form as the solution to the w ell-know n ordinary least squ are. W = RQ − 1 with Q = b X b X ⊤ and R = X b X ⊤ . (3) Marginalized corruption. Ideally , w e w ould like the num ber of corrupted versions b ecome very large, i.e. m → ∞ . By the w eak law of large numbers, R and Q then conv erge to their exp ectations and (3) b ecomes W = E [ R ] E [ Q ] − 1 , ( 4) with the exp ectations of R and Q defi n ed as E [ Q ] = n X i =1 E [ ˆ x i ˆ x ⊤ i ] , E [ R ] = n X i =1 E [ ¯ x i ˆ x ⊤ i ] . (5) The uniform corruption allo ws us to compute th e exp ec- tations in (5) in closed form. Let us define a vector q = [ p, . . . , p, 1] ⊤ ∈ R d +1 , where q α indicates if feature α survive a corruption (the constan t feature is nev er co rrupted, hence q d +1 = 1). If w e denote t he scatter matrix of the uncorrupted input as S = XX ⊤ , we obtain E [ R ] αβ = S αβ q α and E [ Q ] αβ = S αβ q α q β if α 6 = β S αβ q α if α = β . (6) The d iagonal en tries of E [ Q ] are the prod uct of tw o identi- cal features, and the p robabilit y of a feature surviving cor- ruption is p . The exp ected v alue of the d iagonal entries is therefore the scatter matrix m ultiplied by p . The off- diagonal entries are the produ ct of t w o differen t features α and β , whic h are corrup t ed indep end ently . The probabilit y of both fea tures surviving the cor ruption is p 2 . Squashing function. The output of the linear mapping W : R d → R r approximates the ex p ected val ue [17] of a prototype term. It can be b enefi cial to hav e more bag- of-w ord like features th at are either present or not. F or this purp ose, w e apply the tanh() squashing-funct ion t o t h e output z = tanh( Wx ) , (7) whic h has the effect of amplifying or dampen in g the fe ature v alues of the reconstructed prototyp e wo rds. W e refer to our feature learning algorithm as dCoT (Dense Cohort of T erms). 3.1 Recursiv e re-app lication The linear mapping in eq.(7) is trained by reconstruct- ing prototype w ords from partially corrupted input vectors. This linear approach w orks well for prototype words that commonly app ear together with wo rds of similar meaning splendid spectacular glorious sBoW input prototype terms higher-order prototype terms mapping from sparse to dense mapping from dense to dense good good nice tanh( W 1 x i ) tanh( W 2 z 1 i ) x i z 1 i z 2 i Figure 1: Schematic lay out of dCoT. The left part illustrates th at dCoT learns a mapping from the o v erly sparse BoW represen tation to a dense one. The right part illustrates the recursive re- application to reconstruct protot yp e features from the context. ( e.g. “president” and “obama” ), as the mapping captures the correlation b etw een the t w o. It can h o w ev er b e the case that tw o synonyms never app ear t ogether because the input doc- uments are short and the authors use one term or t he other but rarely both together ( e.g. “ tast y” and its rarer synonym “delicious” ). I n these cases it can help to recursively re-apply dCoT to its own output. Here, th e first mapp ing recon- structs a common context b etw een synonyms ( i. e. w ords that co-o ccur with all synonyms) and subsequent applica- tions of dCoT reconstruct the synon ym-prototypes fro m this context. In the p revious example, one could imagine that the first application of dCoT constructs context prototyp e w ords like “fo od” , “exp en sive” , “dinner” , “w onderful” from the original term “deli cious” . The re-application of dCoT reconstructs “tasty” from these context w ords. Let the mapping from eq.(7) b e W 1 ∈ R r × d and z 1 i = tanh W 1 x i , for an input x i . W e n o w compute a second mapping W 2 ∈ R r × r , ex actly as defined in the previous sec- tion, except that we consider the vector s z 1 1 , . . . , z 1 n ∈ R r as input. The mapp ing W 2 is an affine transformation which sta ys wi thin the prototype space spanned b y P . This pro cess can b e rep eated many times and because the input dimen- sionalit y is low the computation of (7) is c heap. Figure 1 illustrates this process in a sc hematic lay out. If d CoT is app lied l times , the final representation z i is the concatenated vector of all outp uts and the original inp ut, z i = ( x i , z 1 i , · · · , z l i ) ⊤ . (8) 4. CONNECTION dCoT shares some common elemen ts with previously pro- p osed feature learning algori thms. In this section, we discuss their simi larities and differences. Stac k ed Denoising Autoenco der (SDA). In the fi eld of image recog nition, the Auto enco der [18] and the Stack ed Denoising Auto enco der ( SDA) [1 9] are widely used to lea rn b etter feature representation from raw pixels inp ut. dCoT shares several core similarities with SDA, whic h in fact in- spired its ori ginal dev elopmen t. Similar to dCoT, SD A first corrupts the raw input, and learns to re-construct it. SDA also stacks several la y ers together by feeding the output of previous lay ers as input into sub-sequ ent la ye rs. H o w eve r, reagan nasdaq bush union budapest year billion dlrs mln share market bank interest price debt nasdaq national nasd system exchange association stock securities trading common president george reagan house white secretary vice political chief senate union soviet workers strike contract united employees wage members moscow currency talks finance hungary central bank senior newspaper contracts financial zero vector reproduction crop areas weather corn dry moisture normal good agriculture winter rescues banking insurance loan deposit deposits federal bill institutions mortgage reserve prototype terms non-prototype terms constant reagon house administration white president congress senate bill states united colorado colorado service states texas kansas agreement association federal oklahoma approval Figure 2: T erm reconstruction from the Reuters dataset. Each column shows a di fferent input term ( e. g. “reagan” , “nasdaq” ), along with the protot yp e terms reconstruct ed from this particular i nput in decreasing order of feature v alues (top to b ottom). T he v ery left column shows the prototype terms generated by an all-empty input do cument. the tw o algorithms also have substan tial differences. The mapping in dCoT is a linear mapping fro m input to output (with a sub- sequent ap p lication of tanh()), which is solved in closed form. In contrast, SDA emplo ys non-linear map- ping from the input to a hidden la y er and then to the out- put. Instead of a closed-form solution, it requires ext ensive gradien t-descent-t yp e hill-clim bing. F urth er, SDA actually corrupts th e input and is trained with multiple ep ochs ov er the dataset, whereas dCoT ma rginalizes out the corruption. In terms of running time, dCoT is orders of magnitud es faster than SDA and scales to much higher dimensional in- puts [20, 21]. Principle Component Analysis (PCA). S imilar to dCoT, Principle Comp on ent Analysis (PCA) [22] learns a lo w er dimensional linear space b y minimizing the reconstruc- tion error of the original input. F or text do cuments, PCA is widely known through its v arian t as latent semantic in- dexing (LSI) [5]. Although b oth dCoT and LSI minimize reconstruction errors, the exact optimization is quite d if- feren t. dCoT explicitly reconstructs prototype words from corruption, whereas LS I minimizes the reconstruction erro r after dimensionali ty reduction. 5. RESUL TS W e ev aluate our algorithm on Re uters and Dmoz datasets together with severa l oth er algorithms for feature learning. Datasets. The R euters-21578 dataset is a collectio n of docu ments that a pp eared on Reuters newswire in 1987. W e follo w the conv entio n of [23], which remo v es docu ments wi th multiple category lab els. The dataset contains 65 ca tegories, and consists of 5946 training and 2347 testing d ocuments. Eac h document is represented by s BoW represen tation w ith 18933 distinct terms. The Dmoz dataset is a hierarchical collection of w ebpage links. The top level of the hierarch y consists of 16 categories. F ollo wing th e conven tion of [24], w e labeled eac h input by its top-level category , and remov e some low -frequent terms. As a result, t h e dataset contains 7184 and 1796 training and testing p oints resp ectively , and eac h inpu t is represented b y the sBoW representation that conta ins 16 498 distinct terms. Reconstruction. Figure 2 sho ws ex amp le input terms (essen tially one- w ord d ocu ments) and th e prototype w ords that are reconstructed with dCoT on the Reuters dataset. n o i se & l a ye rs o n R e u t e rs noise & layers on Reuters Figure 3: Classification accuracy trend on Reuters dataset with di ff erent la y ers and nois e l evels. Eac h column rep resen ts a different input term ( e.g. a d oc- ument consisting of only the term “n asdaq” ) and show s the reconstructed prototyp e terms in decreasing order of their feature v alues (top to b ottom). The v ery left column shows the p rotot yp e features generated b y an all-empty inp ut d oc- ument. These features are completely determined by th e constant bias, and coincide with the most frequent proto- type terms in the whole corp ora. F or all other columns, we subtract this bias-generated ve ctor to h ighligh t the p roto- type wo rds generated by th e actual w ord and not the bias. As shown in the figure, tw o trends can b e observed. First, prototype terms are reconstructed b y other less common and more sp ecific terms. F or example, pr esident is reconstructed by r e agan and bush , and sto ck is reconstructed by nasdaq . Both r e agan and bush are sp ecific terms describing pr es - ident . This trend indicates that dCoT learns the mapping from rare terms to common terms. Second, c ontext and top- ics are reconstructed from rarer terms through the re cursive re-application. F or example, agr icultur e is reconstructed by r epr o duction , indicating that d o cuments containing r epr o- duction typically discuss topics related to agr icultur e . This connection indicates that dCoT also learns t h e higher order correlations b etw een terms and topics. Semi-supervised Learning on Reuters dataset Semi-supervised Learning on Dmoz dataset Figure 4: Semi-sup ervise d lea rning results on the Reuters (left) and Dm oz (right) datasets. On both datasets, dCoT out-p erforms all other algorithms, esp ecially when the num be r of lab eled i nputs i s rela ti vely small. P arameter sensiti v ity . W e also eva luate the effect of different noise lev el and num ber of lay ers ( i.e. th e n umber of recursive re-applicatio ns). Fig ure 3 shows t he classificatio n results on Reut ers d ataset as a function of la yers l and nois e leve l 1 − p . After training of dCoT (on the whole dataset), w e randomly select 1 , 000 labeled training inputs, train an SVM classifier [17] on the n ew feature representation, and test on the full testing set. Two trends emerge: 1. deep la ye rs l > 1 imp rove o ver a single lay ered transformation — supp orting our hypothesis th at as w e recursively re-apply dCoT, not only th e feature rep resentation is enriched, but also t he higher order correlations b etw een terms and topics are learned. 2. b est results are obtained with a surprisingly high level of noise. W e exp lain this trend by the fact that more corruption helps disco v er more subtle relationships be- tw een fe atures and as we operate in the limit, and i ntegra te out all p ossible corruptions, w e can still learn even from substantial ly shortened do cuments. Semi-sup ervised Experime n ts. In many real-wo rld applications, the lab eled training inputs are limited, b ecause labeling usually inv olv es human intera ction and is exp ensive and time-consuming. H ow ev er, unlab eled data is u sually large and av ailable. In this ex p erimen t we ev aluate the suit- abilit y of dCoT to tak e adv antage of semi-sup erv ised learn- ing settings. W e learn the new feature representation with dCoT on the full training set (without lab els), bu t train a linear SV M classifier on a small subset of labeled examples. W e gradually i ncrease the size o f the l ab eled subset and ev al uate on t h e whol e testing set. F or any given n um ber of labeled training inputs, we a v erage over five ru ns (of ran- domly pick ed labeled examples). W e u se the v alidation set to select th e best com bination of noise level and the n umber of la y ers. As baselines, we compare against several alternativ e fea- ture representations, whic h are all obtained from the full training set, simi larly a pplied to a linear SVM classifier. The mo st bas ic baselines are the s BoW represen tation (with term fr equency counts) and TF-I DF [1]. W e compute the TF for eac h docu ment separately , and obtain the IDF from th e whole training set (including labeled and unlab eled d ata). W e then apply the same IDF to the testing set. W e also com- pare against latent semantic indexing (LSI) [5], for which w e further split the training set into training and v alida- tion. W e use t he v alidatio n set to fin d the b est parameter Datasets TF-IDF LSI LDA dCoT Reuters 1s 51m 3h10m 2m Dmoz 1 s 1 h38m 9h1m 3m T able 1: Running tim e required for unsup ervised feature le arning with different algorithms. (num bers of leading Eig env ectors), and retrain o n the whole training set with the b est parameter. The new representa- tion is obtained b y pro jecting th e sBoW feature space onto the LSI eigen ve ctors. Finally , we also compare against La- tent Diric hlet Allocation (LDA) [4 ]. Similar to LSI , w e use a v ali dation se t to find the b est parameters, whic h includ e the Diric hlet hyper-parameter and th e number of topics. The new representati on learned fro m LDA are the topic mixture probabilities. The classification results are presented in figure 4 . The graph sho ws that on both Dmoz and Reuters datasets, dCoT generally out-p erforms all other algorithms. This trend is particularly prominent in settings with relatively little la- b eled trai ning data. Running time . T able 1 compares the running times fo r feature learning with different algorithms. All timings are p erformed on a d esktop with dual Intel T M Six Core Xeon X5650 2. 66GHz processors. Compared to LDA and LSI, t h e timing results sh o w a th ree orders of magnitude speed-u p on tw o d atasets, reducing the fea ture learning time fro m severa l hours to a few minutes. 6. CONCLUSION In this paper w e prese nt dCoT, an al gorithm that ef - ficiently le arns a bett er feature represen tation for sBo W docu ment data. Sp ecifically , dCoT learns a mapping from high dimensional sparse to lo w dimensional dense represen- tations by t ran slating rare to common terms. Recursive re- application of dCo T on i ts o wn o utput results in the disco v- ery of higher o rder topics from ra w terms. O n t w o standard b enchmark d ocument clas sification datasets we demonstrate that our algorithm achiev es state-of-the-art results with v ery high reliability in semi-supervised settings. Acknowledgmen t This ma terial is based up on w ork supp orted b y the Na- tional Science F oun dation un der Grant No. 1149882. A ny opinions, findings, and conclusions or recommendations ex- pressed in this material are t hose of the author(s) and do not necessarily reflect the v iews of the National Science F oun- dation. 7. REFERENCES [1] K . Jones, “A statistical interpretation of term sp ecificity and its application in retriev al,” Journal of do cumentation , vo l. 28, no. 1, pp. 11–21, 1972 . [2] K . W einberger, A. Dasgupta, J. Langford, A. Smola, and J. A ttenberg, “F eature hashing for large scale multita sk learning,” in Pr o c e e dings of the 26th Ann ual International Confer enc e on Machine L e arning . ACM , 2009, pp. 1113–1120. [3] G. Csurk a , C. Dance, L. F an, J. Willa mo wski, and C. Bray , “Visual categorization with bags of keypoints,” in W orkshop on stat istic al le arning in c omputer vision, ECCV , vol. 1, 2004 , p. 22. [4] D . Blei, A. Ng, and M. Jordan, “Latent dirichlet allocation,” The Journal of Machine Le arning R es e ar ch , v ol. 3, pp. 993–1022, 2003. [5] S . Deerwester, S. Dumais, G. F u rnas, T. Landauer, and R . Harshman, “In dexing by latent semanti c analysis,” Journal of the Amer ic an so ciety for information scienc e , vol. 41, no. 6, pp. 391– 407, 1990 . [6] H . Luhn , “A statistical approach to mec hanized encod ing and searc hing of literary information,” IBM Journal of r ese ar ch and development , vol. 1, no. 4, pp. 309–317 , 1957. [7] G. Salton, A . W ong, and C. Y ang, “A v ector space mod el for automatic indexing,” Communic ations of the ACM , vo l. 18, no. 11, pp. 613–620, 1975 . [8] G. Salton and C. Buckley , “T erm-weigh ting approac hes in automatic text retriev al,” Inf ormation pr o c essing & management , vol. 24, no. 5, pp. 513–523, 19 88. [9] A . Singhal, C. Buckley , and M. Mitra, “Pivoted docu ment length normalization,” in Pr o c e e dings of the 19th annual international A CM SIGIR c onfer enc e on R es e ar ch and development in information r et rieval . ACM , 1996, pp. 21–29. [10] K. W einb erger and O. Chap elle, “Large margin taxonomy em b edding for document categorization,” in A dv anc es in Neur al Information Pr o c essing Systems 21 , D. Koller, D. Sch uurmans, Y. Bengio, and L. Bottou, Eds., 2009, pp. 1737–1744. [11] T. H ofmann, “Probabilistic la tent seman tic ind exing,” in Pr o c e e dings of the 22nd annual international ACM SIGIR c onf er enc e on R es e ar ch and development in information r etrieval . ACM , 1999, pp. 50–57. [12] K. N igam, A . McCallum, S. Thrun, and T. Mi tchell , “T ext classification from lab eled and unlab eled docu ments using em,” in Machine L e arning , 1999, pp. 103–134 . [13] B. Ba i, J. W eston, D. Grangier, R. Coll ob ert, K. Sadamasa, Y. Qi, O. Chap elle, and K. W ein berger, “Sup ervised semantic indexing,” in Pr o c e e ding of the 18th A CM c onfer enc e on Information and know le dge management , ser. CIKM ’09. New Y ork, NY, USA: ACM , 2009, pp. 187–196. [14] G. Go lub and C. Reinsc h, “Singular v alue decomp osition and least squares solutions, ” Numerische Mathematik , vol. 14, no. 5, pp. 403–420, 1970. [15] J. Blitzer, K. W einberger, L. K. Saul, and F. C. N. P ereira, “Hierarchica l d istributed representations for statistical language modeling,” in A dvanc es in Neur al and Information Pr o c essing Systems , vol. 17. Cam bridge, MA: MIT Press, 2005. [16] K. W einb erger, F. Sha, and L. K. Saul, “Learning a kernel matrix for nonlinear dimensionality reduction,” in Pr o c e e dings of the Twenty First International Confer enc e on Machine L e arning (ICML-04) , Banff, Canada, 2004, pp. 839–846. [17] C. Bishop, Pattern R e c o gnition and Machine L e arning . Springer, 2006. [18] G. Hin ton and R. Zemel, “Auto enco ders, minimum description length, and helmholtz free energy ,” A dv anc es in neur al i nformation pr o c essing systems , pp. 3–3, 1994. [19] P . Vincent, H. Larochelle, Y. Bengio, and P . Manzagol, “Ext racting and composing robust features with denoising auto enco ders,” in Pr o c e e dings of the 25th internat ional c onfer enc e on Machine le ar ning . A CM, 2008, pp . 1096–1103. [20] M. C hen, Z. Xu, K. Q. W einberger, and F. Sha, “Marginali zed denoising auto enco ders for domain adaptation,” in Pr o c e e dings of the 29th International Confer enc e on Machine L e arning (ICML-12) , ser. ICML ’12, J. Langford and J. Pineau, Eds. New Y ork, N Y , USA : ACM , July 2012, p p. 767–774. [21] Z. E. Xu, K. Q. W ei nberger, and F. Sha, “Rapid feature learning with stack ed linear denoisers,” CoRR , vol . abs/1105.0972, 2011. [22] I. Jolliffe and MyiLibrary , Princip al c omp onent analysis . Wiley Online Library , 2002, v ol. 2. [23] D. Cai, X. W an g, and X. He, “Probabilistic dya dic data analysis with lo cal and global consis tency ,” in Pr o c e e dings of the 26th Ann ual International Confer enc e on Machine L e arning (ICML 2009) , 20 09, pp. 105–112. [24] C. D o and A. Ng, “T ransfer lea rning fo r text classification,” in A dvanc es in Neur al Inf ormation Pr o c essing Systems 18 , Y . W eiss, B. Sch ¨ olk opf, and J. Platt, Eds. Cambridge, MA: MIT Press, 2006 , pp. 299–306 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment