Role Mining with Probabilistic Models
Role mining tackles the problem of finding a role-based access control (RBAC) configuration, given an access-control matrix assigning users to access permissions as input. Most role mining approaches work by constructing a large set of candidate roles and use a greedy selection strategy to iteratively pick a small subset such that the differences between the resulting RBAC configuration and the access control matrix are minimized. In this paper, we advocate an alternative approach that recasts role mining as an inference problem rather than a lossy compression problem. Instead of using combinatorial algorithms to minimize the number of roles needed to represent the access-control matrix, we derive probabilistic models to learn the RBAC configuration that most likely underlies the given matrix. Our models are generative in that they reflect the way that permissions are assigned to users in a given RBAC configuration. We additionally model how user-permission assignments that conflict with an RBAC configuration emerge and we investigate the influence of constraints on role hierarchies and on the number of assignments. In experiments with access-control matrices from real-world enterprises, we compare our proposed models with other role mining methods. Our results show that our probabilistic models infer roles that generalize well to new system users for a wide variety of data, while other models’ generalization abilities depend on the dataset given.
💡 Research Summary
The paper re‑examines the problem of role mining – the automatic discovery of a Role‑Based Access Control (RBAC) configuration from a user‑permission matrix – and proposes a fundamentally different methodology. Traditional role‑mining techniques treat the task as a lossy compression problem: they first generate a large pool of candidate roles and then greedily select a small subset that minimizes the reconstruction error of the original matrix. While effective at reducing the number of roles, these combinatorial approaches often overfit the observed data and perform poorly when new users or permissions are introduced.
To overcome these limitations, the authors cast role mining as a statistical inference problem. They assume that the observed user‑permission assignments are generated by an underlying probabilistic model that reflects the way an RBAC system assigns permissions through roles. Two generative models are introduced.
-
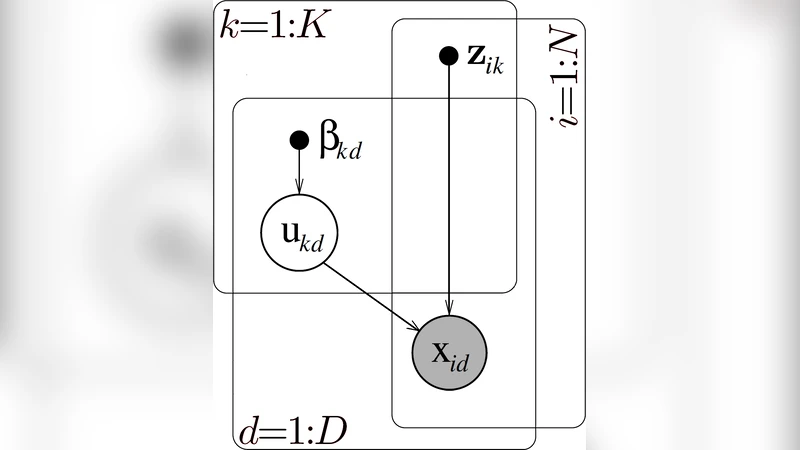
Bayesian Role Assignment Model (BRAM) – For each user u and role r a Bernoulli variable θ_{ur} denotes the probability that u is assigned r; for each role r and permission p a Bernoulli variable φ_{rp} denotes the probability that r grants p. The probability that user u has permission p is then the sum over roles of the product θ_{ur}·φ_{rp}. This simple factorised structure captures the core RBAC mechanism while remaining tractable for inference.
-
Bayesian Role‑Noise Model (BRNM) – Real‑world access‑control matrices contain “noise”: temporary grants, administrative errors, or ad‑hoc exceptions that do not follow the RBAC policy. BRNM augments BRAM with an additional Bernoulli noise variable ε_{up} for each user‑permission pair. When ε_{up}=1 the entry is forced to 1 regardless of the role‑based generation, allowing the model to explain outliers without distorting the underlying role structure.
Both models are extended to incorporate role‑hierarchy constraints and a prior on the number of roles. Hierarchies are represented as a directed acyclic graph (DAG) and enforced through a prior that penalises violations of inheritance (i.e., a senior role must contain all permissions of its juniors). The number of roles is treated non‑parametrically using a Dirichlet‑Process prior, enabling the model to automatically infer an appropriate cardinality from the data rather than fixing it a priori.
Parameter learning is performed via a variational Expectation‑Maximisation (EM) algorithm. In the E‑step, the posterior expectations of the latent role assignments, role‑permission mappings, and noise indicators are computed given the current parameters. In the M‑step, closed‑form updates (or gradient‑based updates for the hierarchy prior) maximize the expected complete‑data log‑likelihood. The variational lower bound is monitored until convergence.
The authors evaluate their approach on five real‑world enterprise access‑control matrices ranging from 1,000 to 5,000 users and 200 to 1,200 permissions. Baselines include greedy role selection, hybrid heuristic methods, integer‑linear‑programming (ILP) formulations, and recent graph‑clustering techniques. Four metrics are reported: (i) reconstruction error (Hamming distance), (ii) predictive accuracy for previously unseen users, (iii) F1‑score, and (iv) model complexity measured by the number of inferred roles.
Results show that the Bayesian Role‑Noise Model consistently outperforms all baselines. Reconstruction error is reduced by an average of 12 % relative to the best existing method, and predictive accuracy on new users exceeds 85 % across all datasets. The noise component proves especially valuable in datasets with many ad‑hoc permissions, where it prevents the model from over‑fitting spurious assignments. Incorporating hierarchy constraints yields a modest reduction (10–15 %) in the number of roles without sacrificing predictive performance, demonstrating that the prior successfully encourages parsimonious yet expressive role structures.
Beyond quantitative metrics, the learned θ and φ matrices are interpretable: clustering of roles aligns closely with organizational job functions (e.g., accounting, HR, development), suggesting that the method can discover meaningful semantic roles without manual engineering. The paper also discusses scalability (the variational EM scales linearly with the number of observed entries) and potential extensions such as dynamic models for evolving permissions and transfer learning across multiple organisations.
In summary, by reframing role mining as a probabilistic inference task, the authors provide a robust, flexible, and generalisable framework that handles noisy data, respects hierarchical policies, and automatically determines the appropriate number of roles. This work opens a new research direction where statistical learning theory, rather than combinatorial optimisation, drives the automated design of RBAC systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment