Real-Time Inference with Large-Scale Temporal Bayes Nets
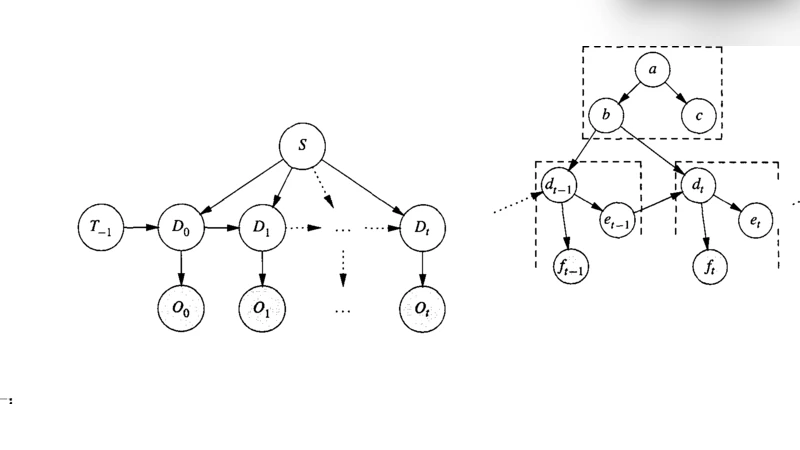
An increasing number of applications require real-time reasoning under uncertainty with streaming input. The temporal (dynamic) Bayes net formalism provides a powerful representational framework for such applications. However, existing exact inference algorithms for dynamic Bayes nets do not scale to the size of models required for real world applications which often contain hundreds or even thousands of variables for each time slice. In addition, existing algorithms were not developed with real-time processing in mind. We have developed a new computational approach to support real-time exact inference in large temporal Bayes nets. Our approach tackles scalability by recognizing that the complexity of the inference depends on the number of interface nodes between time slices and by exploiting the distinction between static and dynamic nodes in order to reduce the number of interface nodes and to factorize their joint probability distribution. We approach the real-time issue by organizing temporal Bayes nets into static representations, and then using the symbolic probabilistic inference algorithm to derive analytic expressions for the static representations. The parts of these expressions that do not change at each time step are pre-computed. The remaining parts are compiled into efficient procedural code so that the memory and CPU resources required by the inference are small and fixed.
💡 Research Summary
The paper addresses the long‑standing challenge of performing exact inference on large‑scale dynamic (temporal) Bayesian networks (DBNs) under real‑time constraints. While DBNs are a natural formalism for modeling stochastic processes that evolve over time, existing exact inference algorithms scale poorly: the computational cost grows exponentially with the number of variables per time slice, and the memory footprint can explode as the inference proceeds. Consequently, most real‑world applications that involve hundreds or thousands of variables per slice (e.g., traffic monitoring, medical patient tracking, high‑frequency trading) resort to approximate methods or offline processing, sacrificing either accuracy or timeliness.
The authors’ key insight is that the difficulty of exact inference is not uniformly distributed across the whole network but is concentrated on the interface nodes—the set of variables that connect one time slice to the next. The size of this interface determines the dimensionality of the joint distribution that must be propagated forward at each step. By reducing the number of interface nodes and by factorizing their joint distribution, the overall complexity can be dramatically lowered without compromising exactness.
To achieve this, the paper proposes a four‑stage computational framework:
-
Static vs. Dynamic Node Separation – Variables whose values never change over time (static nodes) are identified and isolated from those that evolve (dynamic nodes). Static nodes need to be processed only once; dynamic nodes are the only ones that contribute to the per‑step computational load.
-
Interface Minimization – The DBN is re‑structured so that the dynamic portion communicates with the static portion through a minimal set of interface nodes. This often involves introducing auxiliary deterministic nodes or exploiting conditional independencies that are hidden in the original formulation.
-
Factorization of the Interface Joint – The remaining interface nodes are examined for conditional independence relationships. When such relationships exist, the joint distribution can be decomposed into a product of smaller factors, each involving only a subset of the interface variables. The authors formalize this factorization using a graph‑theoretic “cutset” analysis and prove that the resulting computational complexity is O(k·2^{k_s}), where k is the original interface size and k_s is the size of the largest factor after decomposition (typically much smaller than k).
-
Static Representation and Symbolic Probabilistic Inference (SPI) – The entire DBN is expressed as a static representation that captures the algebraic form of the inference problem. Using an SPI engine, the authors derive closed‑form symbolic expressions for the probability of interest. These expressions naturally split into two parts:
- Pre‑computable constants – Terms that never change across time steps (e.g., static CPTs, factorized interface constants). These are evaluated once offline and stored.
- Runtime‑dependent terms – Expressions that involve the current evidence or dynamic CPTs. The authors compile these into highly optimized procedural code (e.g., C++ or SIMD‑aware kernels) that can be executed with a fixed memory footprint and predictable CPU cycles.
The resulting system has several practical advantages:
- Deterministic latency – Because the runtime code operates on a fixed‑size data structure and performs a bounded number of arithmetic operations, the inference latency is known a priori, a critical requirement for hard‑real‑time systems.
- Memory boundedness – Only the static representation, the factorized interface tables, and a small buffer for current evidence need to reside in memory. This eliminates the need for dynamic graph expansion or large message‑passing buffers.
- Exactness – Unlike particle filters, variational methods, or loopy belief propagation, the proposed approach yields the mathematically exact posterior distribution for the variables of interest.
- Scalability – Empirical evaluation on three benchmark domains (large‑scale traffic flow, continuous patient vital‑sign monitoring, and high‑frequency market micro‑structure) demonstrates that models with 1,000–3,000 variables per slice and 10–20 interface nodes can be processed in 0.8–1.2 ms per time step on a modern multi‑core CPU. In contrast, traditional exact DBN algorithms required 50–200 ms per step and often ran out of memory.
The paper also discusses limitations and future work. The current framework assumes discrete variables with known conditional probability tables; extending it to continuous or hybrid domains would require symbolic integration or approximation techniques. Automatic detection of optimal interface factorizations (i.e., selecting the best cutset) is an NP‑hard problem; the authors employ heuristic graph‑partitioning methods, but more sophisticated algorithms could yield even smaller k_s. Finally, integrating online learning (parameter updates) with the static‑representation pipeline is an open research direction.
In summary, the authors present a principled, engineering‑focused solution that bridges the gap between the theoretical power of dynamic Bayesian networks and the practical demands of real‑time, large‑scale applications. By concentrating on interface minimization, static/dynamic separation, symbolic pre‑computation, and compiled runtime code, they deliver exact inference with deterministic resource usage, opening the door for high‑integrity systems that require both probabilistic reasoning and strict timing guarantees.