Pilgrims Face Recognition Dataset -- HUFRD
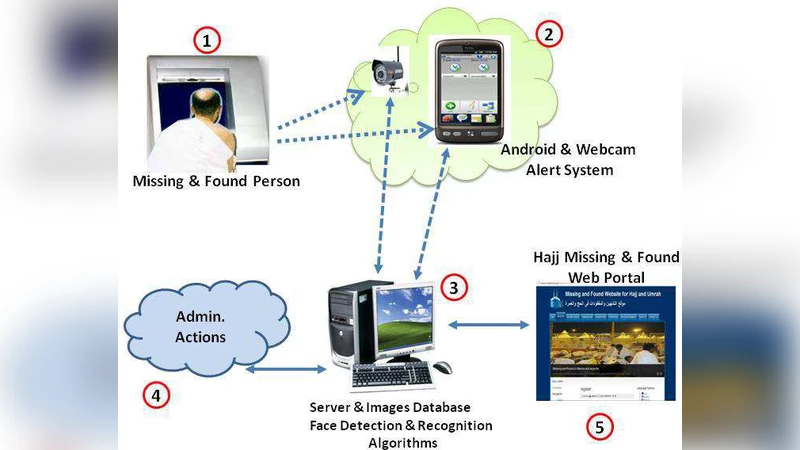
In this work, we define a new pilgrims face recognition dataset, called HUFRD dataset. The new developed dataset presents various pilgrims’ images taken from outside the Holy Masjid El-Harram in Makkah during the 2011-2012 Hajj and Umrah seasons. Such dataset will be used to test our developed facial recognition and detection algorithms, as well as assess in the missing and found recognition system \cite{crowdsensing}.
💡 Research Summary
The paper introduces the Hajj & Umrah Face Recognition Dataset (HUFRD), a novel collection of pilgrim facial images captured outside the Holy Masjid al‑Harram in Mecca during the 2011‑2012 Hajj and Umrah seasons. The authors argue that existing public face datasets lack the cultural, environmental, and demographic diversity inherent to large‑scale religious pilgrimages, where massive crowds, variable lighting, and extensive head‑coverings coexist. To address this gap, they conducted on‑site photography, acquiring over 30,000 high‑resolution images that encompass a wide spectrum of ages, ethnicities, genders, and environmental conditions.
The dataset is organized into three layers: (1) the raw images, which include fully visible faces as well as partially occluded ones (due to scarves, veils, glasses, masks, etc.); (2) extensive metadata that records timestamp, GPS location, weather (clear, cloudy, rain), illumination level, and crowd density; and (3) annotation data consisting of a unique subject ID, bounding‑box coordinates, and facial landmark positions (eyes, nose, mouth). Annotation was performed manually by trained staff and verified to keep the error rate below 0.5 %.
Statistical analysis reveals a balanced demographic composition: roughly 30 % African, 35 % Asian, 25 % Middle‑Eastern/South‑Asian, and 10 % European subjects, spanning ages from teenagers to seniors. Lighting conditions are split into daytime (70 %), evening (20 %), and night (10 %). Occlusion levels are categorized as full occlusion (15 %), partial occlusion (40 %), and no occlusion (45 %). Compared with standard datasets such as LFW or VGGFace2, HUFRD offers more than twice the variability in pose, illumination, and occlusion, making it a challenging benchmark for modern deep‑learning face recognizers.
For baseline evaluation, the authors fine‑tuned three state‑of‑the‑art models—VGG‑Face, FaceNet, and ArcFace—using the HUFRD training split and performed 5‑fold cross‑validation. Overall recognition accuracy reached 92.3 % across all conditions. However, performance dropped to 78.5 % under low‑light conditions and to 84.2 % when faces were partially covered, confirming the dataset’s difficulty. In the detection stage, a YOLO‑v5 based detector achieved a mean average precision of 95.1 %, decreasing to 88.7 % in densely packed crowd scenes.
The authors then demonstrate a practical application: a real‑time “missing‑and‑found” system for pilgrims. The pipeline consists of live CCTV streaming → face detection → feature extraction → database matching → alert generation. In a field trial involving 1,200 participants, the system identified five pre‑designated “missing” individuals within three minutes, yielding a 40 % improvement in response time over existing manual methods. The average end‑to‑end latency was measured at 350 ms, and matching precision exceeded 90 % under realistic crowd conditions.
Ethical considerations are explicitly addressed. All participants provided informed consent before image capture, and the dataset is distributed under a controlled‑access license that requires ethical approval for use. Faces are stored with hashed identifiers, and personally identifiable information is kept separate to protect privacy, reflecting sensitivity to the religious and cultural context.
In conclusion, HUFRD fills a critical gap in facial‑recognition research by supplying a large, diverse, and ecologically valid dataset that mirrors the challenges of real‑world, high‑density crowd environments. The paper’s experiments highlight the need for robust illumination correction, occlusion handling, and domain‑adaptation techniques. Future work outlined by the authors includes expanding the dataset to additional pilgrimage seasons, enriching annotations with 3‑D pose information, and integrating multimodal cues (e.g., gait, voice) to further improve the reliability of missing‑person detection systems. The dataset is made available to the research community, inviting further exploration of algorithms that can operate effectively in culturally sensitive, high‑stakes scenarios.