Beamforming Techniques for Multichannel audio Signal Separation
Beamforming is a signal processing technique. It has been studied in many areas such as radar, sonar, seismology and wireless communications, to name but a few. It can be used for a myriad of purposes, such as detecting the presence of a signal, estimating the direction of arrival, and enhancing a desired signal from its measurements corrupted by noise, competing sources and reverberation. Actually, Beamforming has been adopted by the audio research society, mostly to separate or extract speech for noisy environment. Beamforming techniques basically approach the problem from a spatial point of view. A microphone array is used to form a spatial filter which can extract a signal from a specific direction and reduce the contamination of signals from other directions. In this paper we survey some Beamforming techniques used for multichannel audio signal separation.
💡 Research Summary
This paper presents a comprehensive survey of beamforming techniques applied to multichannel audio signal separation, focusing on how spatial filtering with microphone arrays can isolate a desired speech source while suppressing noise, interfering speakers, and reverberation. The authors begin by outlining the fundamental signal model for an array of microphones, describing how each sensor captures a mixture of the target source, competing sources, diffuse background noise, and room reflections. They then categorize beamforming methods into three broad families: conventional fixed beamformers, optimal linear beamformers, and adaptive structures, and discuss the mathematical foundations, practical implementations, and performance trade‑offs of each.
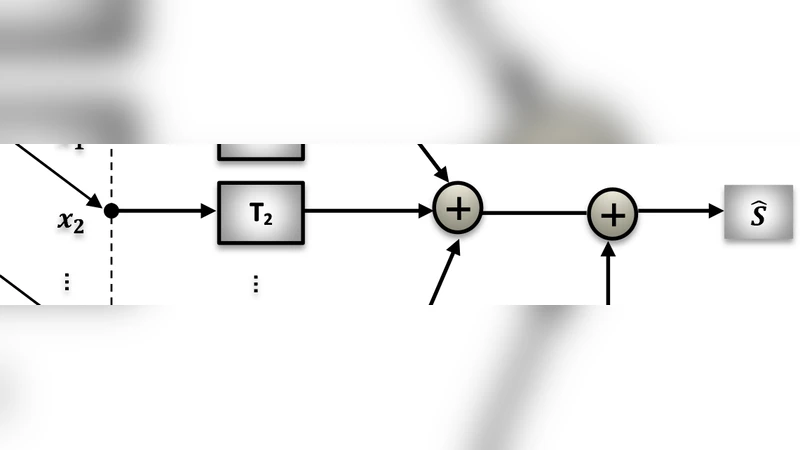
The simplest approach, Delay‑and‑Sum (DS), aligns the signals from each microphone according to the presumed direction of arrival (DOA) and sums them with equal weights. While DS is computationally cheap and suitable for real‑time processing, its wide main‑lobe limits noise suppression, especially in highly reverberant or multi‑interferer scenarios. To overcome these limitations, the paper reviews Minimum‑Variance Distortionless Response (MVDR) beamforming, which minimizes output noise power under a distortionless constraint for the target direction. MVDR requires an accurate estimate of the noise covariance matrix; errors in this estimate can distort the beampattern and degrade speech quality. Linear Constraint Minimum Variance (LCMV) extends MVDR by allowing multiple linear constraints, enabling simultaneous extraction of several sources or null‑steering toward specific interferers. However, each added constraint reduces the degrees of freedom, thereby limiting achievable interference attenuation.
Adaptive beamformers are represented by the Generalized Sidelobe Canceller (GSC). GSC splits the system into a fixed pre‑steering stage and an adaptive noise canceller that uses algorithms such as LMS or RLS to suppress residual sidelobes. This architecture is attractive because it separates the distortionless constraint from the adaptation process, but its convergence speed and stability are highly dependent on array geometry, signal‑to‑noise ratio, and the choice of step‑size.
The survey also covers super‑directive beamforming, which seeks high directivity even when microphone spacing is less than half a wavelength. Although super‑directive designs can theoretically achieve very narrow beams, they amplify sensor noise and are extremely sensitive to array mismatches. Regularized MVDR, multi‑spectrum techniques, and Wiener‑filter‑based extensions are discussed as practical ways to mitigate these issues.
A significant portion of the paper is devoted to data‑driven and hybrid methods. Modern DOA estimators (MUSIC, ESPRIT, SRP‑PHAT) can be integrated into adaptive beamformers to track moving speakers, but their performance hinges on accurate angle estimation. More recently, deep‑learning approaches have been introduced either to learn spatial filters directly from raw multichannel waveforms or to provide better initializations for traditional adaptive algorithms. Convolutional, recurrent, and transformer networks have demonstrated impressive gains in highly non‑stationary noise and reverberant environments, yet they demand large labeled datasets and substantial computational resources, raising concerns about real‑time deployment on embedded platforms.
The authors evaluate all techniques using standard objective metrics such as PESQ, STOI, and SDR, as well as practical considerations like algorithmic latency, computational complexity, and robustness to array perturbations. Experiments on synthetic mixtures, the CHiME‑3 dataset, and the REVERB Challenge corpus reveal that no single method dominates across all conditions; instead, performance varies with reverberation time, number of interferers, and microphone geometry.
In conclusion, the paper identifies current challenges—array calibration errors, reverberation modeling, and low‑power real‑time implementation—and points to promising research directions. These include hybrid schemes that combine the interpretability and low‑complexity of classical beamformers with the expressive power of deep neural networks, robust covariance‑matrix estimation techniques, and lightweight model compression for on‑device processing. By systematically organizing the state‑of‑the‑art, this survey serves as a valuable reference for researchers and engineers seeking to design or improve multichannel audio separation systems based on beamforming.