Data Life Cycle Labs, A New Concept to Support Data-Intensive Science
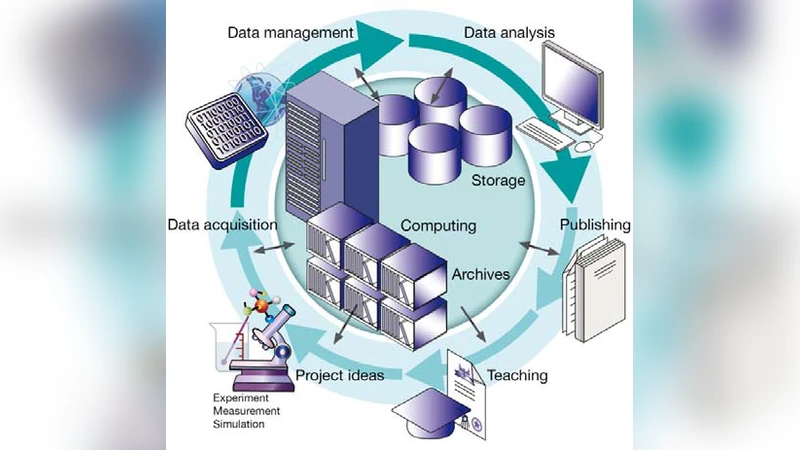
In many sciences the increasing amounts of data are reaching the limit of established data handling and processing. With four large research centers of the German Helmholtz association the Large Scale Data Management and Analysis (LSDMA) project supports an initial set of scientific projects, initiatives and instruments to organize and efficiently analyze the increasing amount of data produced in modern science. LSDMA bridges the gap between data production and data analysis using a novel approach by combining specific community support and generic, cross community development. In the Data Life Cycle Labs (DLCL) experts from the data domain work closely with scientific groups of selected research domains in joint R&D where community-specific data life cycles are iteratively optimized, data and meta-data formats are defined and standardized, simple access and use is established as well as data and scientific insights are preserved in long-term and open accessible archives.
💡 Research Summary
The paper introduces Data Life Cycle Labs (DLCL), a novel organizational concept designed to bridge the widening gap between data generation and data analysis in today’s data‑intensive sciences. DLCL is embedded within the Large Scale Data Management and Analysis (LSDMA) project of the German Helmholtz Association, which unites four major research centers to provide a coordinated response to the exponential growth of scientific data. The authors argue that traditional data‑handling pipelines—often built in an ad‑hoc fashion—are no longer sufficient because they lack standardized formats, robust metadata capture, scalable storage, and reproducible analysis environments.
DLCL addresses these shortcomings through a two‑pronged strategy: (1) community‑specific support and (2) cross‑community generic infrastructure. In the first pillar, DLCL staff—data engineers, software developers, and metadata specialists—embed themselves within selected scientific domains (e.g., high‑energy physics, climate modeling, genomics). By working side‑by‑side with domain scientists, they map the unique data life cycle of each community, define optimal acquisition protocols, and co‑design processing pipelines that respect the particularities of the data (such as real‑time streaming, multi‑dimensional gridded fields, or massive image archives).
The second pillar creates a shared backbone that all communities can leverage. This includes a hierarchical storage architecture (fast SSD tier, high‑capacity HDD tier, and long‑term tape archive), automated data deduplication and compression, and a unified metadata registry compliant with ISO 19115, the FAIR principles, and other international standards. Metadata is captured automatically at the point of data creation, enriched with provenance information, and assigned persistent identifiers and version tags to guarantee reproducibility.
A key operational concept of DLCL is the iterative “R&D cycle.” After an initial joint modeling of the community’s data life cycle, a pilot implementation is deployed, feedback is collected, and the workflow is refined. This loop continues until the data handling procedures are mature, standardized, and fully automated. The authors emphasize the importance of providing a self‑service portal and container‑based analysis environments (Docker, Singularity) that allow researchers to launch pre‑validated workflows with minimal coding effort. By abstracting the underlying complexity, DLCL lowers the technical barrier for scientists to exploit large datasets, thereby accelerating discovery.
Long‑term preservation and open accessibility are treated as first‑class requirements. Data and metadata are stored redundantly across geographically separated repositories, subject to regular integrity checks, and governed by fine‑grained access‑control policies. This design ensures that datasets remain usable for decades, supporting future re‑analysis and cross‑disciplinary studies.
From a governance perspective, LSDMA coordinates the four research centers, aligning funding, infrastructure investment, staffing, and performance metrics. Each center acts as a “core infrastructure provider,” while the scientific groups serve as “domain experts.” This symbiotic relationship creates a sustainable ecosystem where data‑centric research can thrive without the traditional bottlenecks of siloed IT support or fragmented data policies.
In conclusion, DLCL represents a comprehensive, scalable model for managing the entire data life cycle—from acquisition through analysis, archiving, and reuse. By coupling community‑tailored assistance with a robust, shared technical platform, DLCL not only mitigates current data‑handling challenges but also establishes a blueprint for future data‑intensive research infrastructures worldwide. The authors anticipate that the DLCL approach will evolve into an international standard, fostering reproducible, open, and collaborative science across diverse disciplines.