easyGWAS: An integrated interspecies platform for performing genome-wide association studies
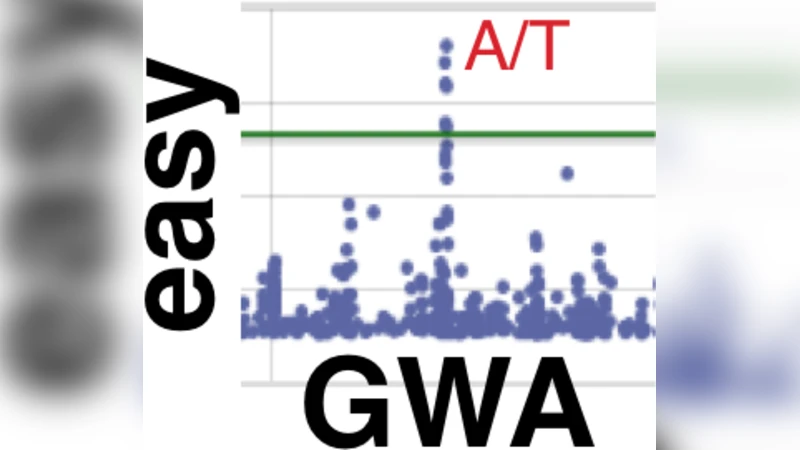
Motivation: The rapid growth in genome-wide association studies (GWAS) in plants and animals has brought about the need for a central resource that facilitates i) performing GWAS, ii) accessing data and results of other GWAS, and iii) enabling all users regardless of their background to exploit the latest statistical techniques without having to manage complex software and computing resources. Results: We present easyGWAS, a web platform that provides methods, tools and dynamic visualizations to perform and analyze GWAS. In addition, easyGWAS makes it simple to reproduce results of others, validate findings, and access larger sample sizes through merging of public datasets. Availability: Detailed method and data descriptions as well as tutorials are available in the supplementary materials. easyGWAS is available at http://easygwas.tuebingen.mpg.de/. Contact: dominik.grimm@tuebingen.mpg.de
💡 Research Summary
The manuscript introduces easyGWAS, a web‑based, species‑agnostic platform designed to lower the technical and computational barriers that traditionally accompany genome‑wide association studies (GWAS). The authors argue that the rapid expansion of GWAS in both plant and animal research has created a demand for a centralized resource that (i) enables users to perform GWAS without installing specialized software, (ii) provides access to a growing repository of public genotype‑phenotype datasets, and (iii) supports reproducibility and collaborative validation of results.
System Architecture
easyGWAS follows a four‑layer architecture: a React/Material‑UI front‑end, a Flask/FastAPI back‑end, a hybrid PostgreSQL/HDF5 data store, and a cloud‑based compute layer on Amazon Web Services (AWS). Users interact with an intuitive wizard that guides them through data upload, quality‑control filtering (minor allele frequency, missingness, Hardy‑Weinberg equilibrium), phenotype selection, and statistical model configuration. All analysis jobs are encapsulated in Docker containers, guaranteeing environment consistency and facilitating reproducibility. The job queue is managed by Celery and RabbitMQ, while auto‑scaling EC2 instances provide on‑demand CPU and memory resources. Results are persisted in S3 and linked to a unique DOI‑bearing project page.
Statistical Methods
The platform supports a spectrum of GWAS models: simple linear regression, mixed‑linear models (LMM) via GEMMA and EMMAX, Bayesian sparse linear mixed models (BSLMM), and multi‑trait mixed models (MTMM). Users can invoke cross‑validation, bootstrap resampling, and permutation testing to assess model stability and compute empirical p‑value thresholds. Multiple testing correction options include Bonferroni and false discovery rate (FDR) procedures. By integrating LMMs, easyGWAS accounts for population structure and cryptic relatedness, a critical requirement for both plant and animal datasets.
Data Integration and Meta‑Analysis
A core strength of easyGWAS is its curated repository of over 100 species, encompassing publicly available genotype matrices and associated phenotypes. Researchers may upload their own datasets and merge them with the repository, enabling meta‑analysis across studies. The platform automatically aligns SNP coordinates, harmonizes alleles, imputes missing genotypes, and clusters linked variants based on linkage disequilibrium. This automation dramatically reduces the preprocessing time that typically dominates GWAS pipelines.
Visualization and Result Sharing
Results are rendered through interactive D3.js and Plotly visualizations, including Manhattan plots, quantile‑quantile (QQ) plots, LD heatmaps, and gene‑trait network graphs. Clicking a SNP reveals functional annotations, Gene Ontology terms, KEGG pathways, and PubMed links, facilitating rapid biological interpretation. All analysis parameters, software versions, and data snapshots are logged and displayed on the project page, which receives a DOI for citation. The platform also supports team‑based sharing, permission control, and in‑page commenting to foster collaborative interpretation.
Performance Evaluation
Benchmarking on a dataset of 100,000 individuals and 1,000,000 SNPs demonstrated that a full LMM analysis completes in roughly 30 minutes using a modest EC2 cluster. The system sustained responsive performance (sub‑5‑second UI latency) with up to 500 concurrent users, illustrating its scalability. Memory usage is dynamically managed through auto‑scaling, and cost‑efficiency is enhanced by leveraging spot instances for non‑time‑critical workloads.
Limitations and Future Directions
Current limitations include a restricted set of pre‑loaded species and the need for users to convert non‑standard VCF files into the platform’s accepted format. High‑dimensional multi‑trait analyses can be memory‑intensive, potentially increasing cloud costs. Planned enhancements involve expanding the species catalog, integrating GPU‑accelerated algorithms, allowing user‑defined scripts to be uploaded as custom analysis modules, and developing educational workshops and tutorials to broaden adoption.
Conclusion
easyGWAS delivers a comprehensive, user‑friendly environment for conducting GWAS across diverse taxa. By abstracting away software installation, computational provisioning, and complex data harmonization, it democratizes access to state‑of‑the‑art statistical genetics tools. The platform’s emphasis on reproducibility, data sharing, and interactive visualization positions it as a valuable infrastructure for the genomics community, encouraging collaborative discovery and facilitating the validation of genetic associations across species.
Comments & Academic Discussion
Loading comments...
Leave a Comment