Application of Symmetric Uncertainty and Mutual Information to Dimensionality Reduction and Classification of Hyperspectral Images
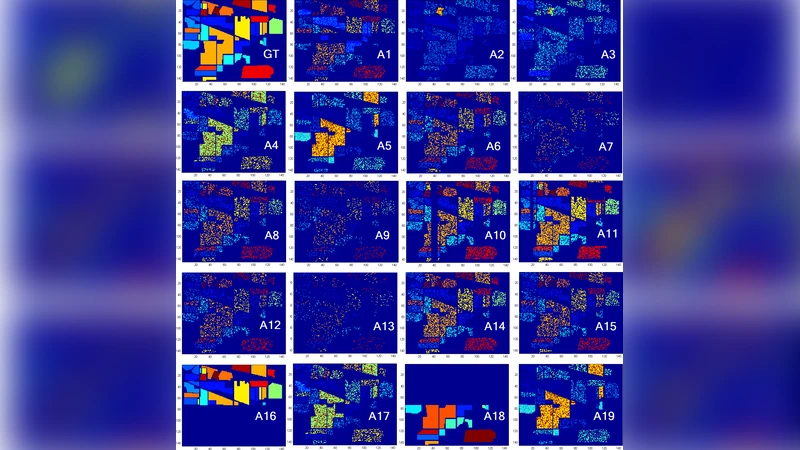
Remote sensing is a technology to acquire data for disatant substances, necessary to construct a model knowledge for applications as classification. Recently Hyperspectral Images (HSI) becomes a high technical tool that the main goal is to classify the point of a region. The HIS is more than a hundred bidirectional measures, called bands (or simply images), of the same region called Ground Truth Map (GT). But some bands are not relevant because they are affected by different atmospheric effects; others contain redundant information; and high dimensionality of HSI features make the accuracy of classification lower. All these bands can be important for some applications; but for the classification a small subset of these is relevant. The problematic related to HSI is the dimensionality reduction. Many studies use mutual information (MI) to select the relevant bands. Others studies use the MI normalized forms, like Symmetric Uncertainty, in medical imagery applications. In this paper we introduce an algorithm based also on MI to select relevant bands and it apply the Symmetric Uncertainty coefficient to control redundancy and increase the accuracy of classification. This algorithm is feature selection tool and a Filter strategy. We establish this study on HSI AVIRIS 92AV3C. This is an effectiveness, and fast scheme to control redundancy.
💡 Research Summary
The paper addresses the well‑known problem of high dimensionality in hyperspectral imaging (HSI), where hundreds of spectral bands often contain redundant or noisy information that degrades classification performance. To select a compact yet informative subset of bands, the authors propose a two‑stage filter‑based feature selection framework that leverages two information‑theoretic measures: Mutual Information (MI) and Symmetric Uncertainty (SU).
In the first stage, the MI between each individual band and the class labels is computed. MI quantifies how much knowledge of a band reduces the uncertainty about the class, thus serving as a relevance score. Bands whose MI exceeds a user‑defined threshold (threshold_MI) are retained as candidates. This step eliminates bands that contribute little discriminative information, reducing the search space dramatically.
The second stage tackles redundancy among the candidate bands. For every pair of candidate bands, the SU is calculated. SU is a normalized version of MI that ranges from 0 (completely independent) to 1 (identical information). A second threshold (threshold_SU) is set; a candidate band is added to the final selected set only if its SU with every already‑selected band is below this threshold. Consequently, the algorithm keeps bands that are both highly relevant (high MI) and mutually non‑redundant (low SU).
The overall algorithm can be summarized as:
- Compute MI(band_i, class) for all bands i.
- Form candidate set C = {i | MI_i ≥ threshold_MI}.
- Initialize selected set S = ∅.
- For each band i in C, compute SU(i, j) for all j ∈ S.
- If all SU(i, j) ≤ threshold_SU, add i to S; otherwise discard i.
- Return S as the reduced feature set for downstream classifiers.
Complexity analysis shows that MI computation is O(N·M) (N = number of bands, M = number of samples), while the pairwise SU evaluation is O(K²·M) where K is the size of the candidate set. Because the method is a filter, it operates independently of any classifier and can be performed as a preprocessing step.
Experimental validation uses the AVIRIS 92AV3C dataset, which contains 224 spectral bands and 16 land‑cover classes. The authors evaluate the selected subsets with several classifiers (Support Vector Machine, k‑Nearest Neighbors, Random Forest) and compare against baseline approaches: simple MI‑based selection, Principal Component Analysis (PCA), and other entropy‑based methods. Results indicate that the proposed MI+SU scheme consistently yields higher overall accuracy—typically 3–5 percentage points improvement—while reducing the number of bands to roughly 10–15. Moreover, classification runtime drops by more than 30 % because of the smaller feature vector.
A key contribution of the work is the explicit combination of a relevance metric (MI) with a redundancy metric (SU) within a lightweight filter framework. This dual‑criterion approach ensures that the final band set is both informative and compact, making it suitable for real‑time or resource‑constrained applications. The paper also discusses the sensitivity of the two thresholds: lowering threshold_MI enlarges the candidate pool but yields diminishing returns, whereas tightening threshold_SU aggressively prunes redundant bands at the risk of discarding useful complementary information.
Limitations are acknowledged. The thresholds are set empirically and may need tuning for different sensors or scenes. The pairwise SU computation can become costly when the candidate set is large, suggesting future work on approximate SU calculations, adaptive threshold selection, or parallel implementations.
In summary, the study presents a practical, theoretically grounded method for hyperspectral band selection that improves classification accuracy and computational efficiency. By integrating mutual information and symmetric uncertainty, it offers a balanced solution to the relevance‑redundancy trade‑off that is central to high‑dimensional remote sensing data analysis.