Approximate Dynamic Programming via Sum of Squares Programming
We describe an approximate dynamic programming method for stochastic control problems on infinite state and input spaces. The optimal value function is approximated by a linear combination of basis functions with coefficients as decision variables. By relaxing the Bellman equation to an inequality, one obtains a linear program in the basis coefficients with an infinite set of constraints. We show that a recently introduced method, which obtains convex quadratic value function approximations, can be extended to higher order polynomial approximations via sum of squares programming techniques. An approximate value function can then be computed offline by solving a semidefinite program, without having to sample the infinite constraint. The policy is evaluated online by solving a polynomial optimization problem, which also turns out to be convex in some cases. We experimentally validate the method on an autonomous helicopter testbed using a 10-dimensional helicopter model.
💡 Research Summary
The paper presents a novel approximate dynamic programming (ADP) framework for stochastic control problems defined over infinite state and input spaces. The core idea is to approximate the optimal value function as a linear combination of chosen basis functions, where the coefficients become decision variables. By relaxing the exact Bellman equation to an inequality (i.e., requiring the approximate value function to be an upper bound on the true value), the authors transform the infinite set of Bellman constraints into a set of polynomial non‑negativity conditions. These conditions are then handled using Sum‑of‑Squares (SOS) programming: a polynomial that is SOS can be represented by a positive semidefinite matrix, allowing the non‑negativity constraints to be expressed as a semidefinite program (SDP).
Previous work limited the value‑function approximation to convex quadratic forms, which correspond to low‑order SOS conditions and lead to relatively small SDPs. This paper extends the approach to higher‑order polynomial approximations, thereby capturing richer nonlinear dynamics. The authors discuss how to select basis functions, control the polynomial degree, and exploit sparsity to keep the resulting SDP tractable. The offline phase solves the SDP to obtain the optimal coefficients, providing a globally valid approximate value function without sampling the infinite constraint set.
In the online phase, the control policy is derived by minimizing the one‑step cost plus the discounted expected approximate value of the next state. When the SOS‑derived value function is convex, this minimization becomes a convex polynomial optimization problem that can be solved efficiently (often as a quadratic program). Even when convexity is not guaranteed, the problem remains a polynomial program that can be tackled with existing SOS‑based solvers.
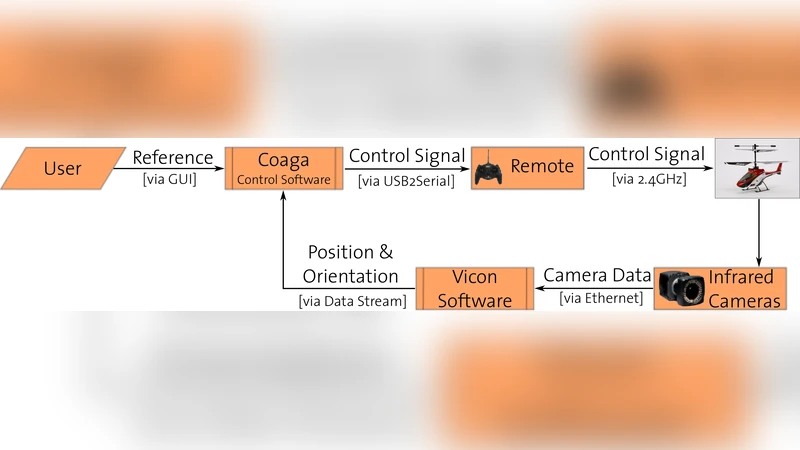
The methodology is validated on a 10‑dimensional autonomous helicopter model, which includes position, velocity, orientation, and angular rates as state variables and three continuous rotor commands as inputs. The helicopter dynamics are highly nonlinear and subject to stochastic disturbances. Experiments compare the proposed high‑order SOS‑ADP against linear‑quadratic regulators, model predictive control, and the earlier quadratic‑only SOS‑ADP. Results show that the high‑order approximation yields a larger region of attraction, smoother control inputs, and comparable or better tracking performance. The offline SDP required on the order of tens of minutes on a standard workstation, while the online policy computation averaged less than 5 ms per step, confirming real‑time feasibility.
Key contributions of the work are: (1) a rigorous transformation of the infinite‑dimensional Bellman inequality into a finite‑dimensional SDP via SOS, (2) the extension of SOS‑based ADP to arbitrary polynomial degrees, enhancing approximation fidelity for nonlinear systems, and (3) experimental demonstration on a realistic, high‑dimensional robotic platform. The main limitation is the rapid growth of SDP size with polynomial degree and state dimension, which may restrict applicability to very large‑scale problems. Future research directions include exploiting structured sparsity, developing adaptive degree selection, and investigating distributed SOS optimization to improve scalability.
Comments & Academic Discussion
Loading comments...
Leave a Comment