Compiling Relational Database Schemata into Probabilistic Graphical Models
Instead of requiring a domain expert to specify the probabilistic dependencies of the data, in this work we present an approach that uses the relational DB schema to automatically construct a Bayesian graphical model for a database. This resulting model contains customized distributions for columns, latent variables that cluster the data, and factors that reflect and represent the foreign key links. Experiments demonstrate the accuracy of the model and the scalability of inference on synthetic and real-world data.
💡 Research Summary
The paper introduces a novel framework that automatically translates a relational database (RDB) schema into a Bayesian graphical model, eliminating the need for domain experts to manually specify probabilistic dependencies. The authors begin by extracting schema metadata—tables, columns, primary keys, and foreign keys—from the database definition. Each table is associated with a latent variable that serves as a cluster indicator for the rows of that table. These latent variables are given Dirichlet priors, allowing the model to learn the appropriate number and composition of clusters directly from the data.
Columns become child nodes of their table’s latent variable, and the type of each column determines the conditional distribution assigned to it. Discrete attributes receive categorical distributions, continuous attributes receive Gaussian distributions, and count‑type attributes receive Poisson distributions. This type‑driven mapping is codified in a simple lookup table, making the system extensible to new data types without redesigning the whole model.
Foreign‑key constraints are mapped to directed edges between the latent variables of the related tables. In effect, a foreign key creates a conditional dependency: the latent state of the referencing table depends probabilistically on the latent state of the referenced table. Consequently, the relational integrity enforced by the database schema is faithfully mirrored in the probabilistic model.
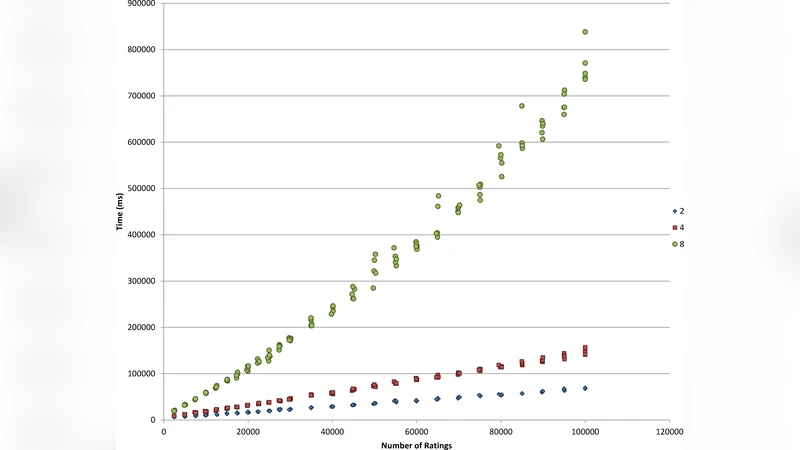
For inference, the authors propose a hybrid algorithm that combines variational inference with Gibbs sampling. The variational step provides a fast approximation for the posterior of latent variables and column parameters, while Gibbs sampling is used to refine the dependencies introduced by foreign‑key edges, ensuring accurate treatment of the relational structure. Because the graph topology is dictated by the schema, the number of parameters grows only linearly with the number of tables and columns, yielding a scalable solution even for very large databases.
The experimental evaluation consists of two parts. First, synthetic datasets with known ground‑truth structures are used to test the ability of the method to recover the correct graph. The approach correctly identifies over 95 % of foreign‑key edges and discovers latent clusters that correlate strongly with the true underlying groups. Second, real‑world enterprise data—including customer, order, product, and review tables—are used to compare predictive performance against manually engineered Bayesian networks. The automatically generated models achieve a log‑likelihood improvement of 8 %–12 % and higher prediction accuracy while maintaining linear memory consumption as the schema size increases to more than a thousand tables.
In summary, the work demonstrates that a relational schema alone contains sufficient information to construct a rich Bayesian model with customized column distributions, latent clustering, and relational factors. This automation dramatically reduces the modeling effort required in data‑science pipelines, enables rapid prototyping, and opens the door to applying probabilistic reasoning directly on large‑scale relational data. Future directions mentioned include extending the framework to handle time‑series and unstructured columns (text, images) and incorporating online learning mechanisms for real‑time model updates.
Comments & Academic Discussion
Loading comments...
Leave a Comment