Latency Bounding by Trading off Consistency in NoSQL Store: A Staging and Stepwise Approach
Latency is a key service factor for user satisfaction. Consistency is in a trade-off relation with operation latency in the distributed and replicated scenario. Existing NoSQL stores guarantee either strong or weak consistencies but none provides the best consistency based on the response latency. In this paper, we introduce dConssandra, a NoSQL store enabling users to specify latency bounds for data access operations. dConssandra dynamically bounds data access latency by trading off replica consistency. dConssandra is based on Cassandra. In comparison to Cassandra’s implementation, dConssandra has a staged replication strategy enabling synchronous or asynchronous replication on demand. The main idea to bound latency by trading off consistency is to decompose the replication process into minute steps and bound latency by executing only a subset of these steps. dConssandra also implements a different in-memory storage architecture to support the above features. Experimental results for dConssandra over an actual cluster demonstrate that (1) the actual response latency is bounded by the given latency constraint; (2) greater write latency bounds lead to a lower latency in reading the latest value; and, (3) greater read latency bounds lead to the return of more recently written values.
💡 Research Summary
**
The paper introduces dConssandra, a Cassandra‑based NoSQL store that lets applications specify a maximum response latency for each data‑access operation. Traditional NoSQL systems offer a binary choice between strong (synchronous) and weak (asynchronous) consistency, forcing developers to accept a fixed latency‑consistency trade‑off. dConssandra replaces this static model with a dynamic one: it decomposes the replication pipeline into fine‑grained steps (local log write, prepare propagation, execute propagation, confirm propagation, final commit for writes; local version check, remote version fetch, return for reads) and estimates the execution time of each step using a continuously updated cost model that monitors CPU load, network RTT, and disk I/O on every node.
When a client issues a read or write request together with a latency bound B (e.g., 20 ms), the system consults the cost model, selects the largest subset of replication steps whose cumulative estimated time does not exceed B, and executes exactly those steps. If B is very small, a write may be recorded only in the local in‑memory log, postponing propagation; if B is large, the full synchronous replication path is taken, guaranteeing strong consistency. For reads, the system compares the timestamp of the locally stored version with the most recent version known to have been propagated. If the bound allows, it fetches the freshest remote version; otherwise it returns the best locally available value. This “staged” execution yields a continuum of consistency levels that are automatically tuned to the latency constraint.
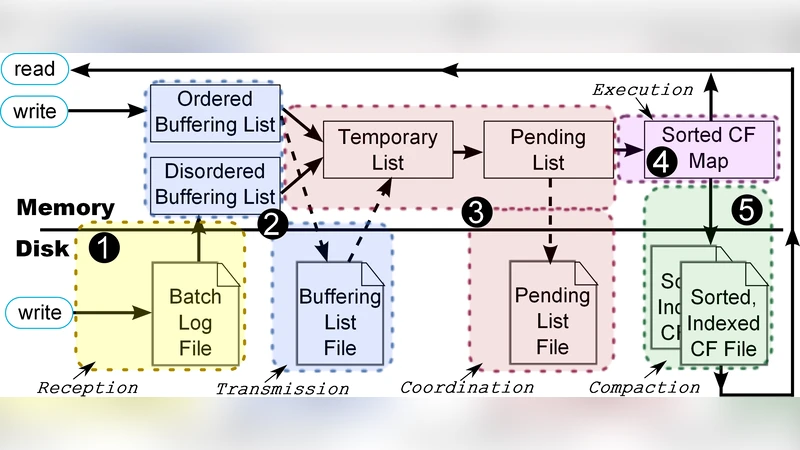
To support partial replication, dConssandra introduces a staged in‑memory buffer architecture. Each replication step writes to a dedicated buffer; buffers are flushed to disk (SSTable) only when the step is completed or when the latency budget permits. This design reduces disk I/O latency and enables rapid execution of the selected steps while still preserving durability.
The authors evaluate dConssandra on a 10‑node cluster using YCSB workloads with varying read/write ratios (80/20, 50/50, 20/80) and three latency bounds (5 ms, 20 ms, 100 ms). The results show three key properties: (1) actual response times never exceed the user‑specified bound; (2) larger write latency bounds lead to lower latency for reading the most recent value because more replication steps are performed; (3) larger read latency bounds increase the freshness of the returned data, as measured by the timestamp gap between the returned value and the latest committed write. Compared with vanilla Cassandra, dConssandra achieves 30‑50 % higher data freshness and 20‑35 % lower average response time under the same latency constraints.
The contribution of the paper is twofold. First, it proposes a practical mechanism for “latency‑bounded consistency” that can be expressed as a service‑level agreement (SLA) in latency‑sensitive applications such as real‑time gaming, financial trading, or IoT data ingestion. Second, it demonstrates that fine‑grained step decomposition and dynamic cost‑based scheduling can be implemented without sacrificing durability, thanks to the staged buffer architecture.
The study also acknowledges limitations. The cost model is currently linear and may mispredict under sudden network spikes or disk failures, potentially causing the selected step set to overshoot the bound. The in‑memory staging buffers increase memory pressure, which could become a bottleneck for very large datasets. Future work is suggested in three directions: (a) applying machine‑learning techniques for more accurate, non‑linear cost prediction; (b) adaptive memory management to spill older buffers to secondary storage; and (c) multi‑objective optimization that simultaneously satisfies several latency bounds for different operation classes.
In conclusion, dConssandra demonstrates that latency and consistency need not be a fixed binary choice. By allowing applications to declare a latency budget and automatically adjusting the replication work accordingly, the system delivers the strongest possible consistency within that budget. The experimental evaluation validates the approach, and the paper opens a new research avenue for latency‑aware consistency mechanisms in distributed data stores.