Evaluating Classifiers Without Expert Labels
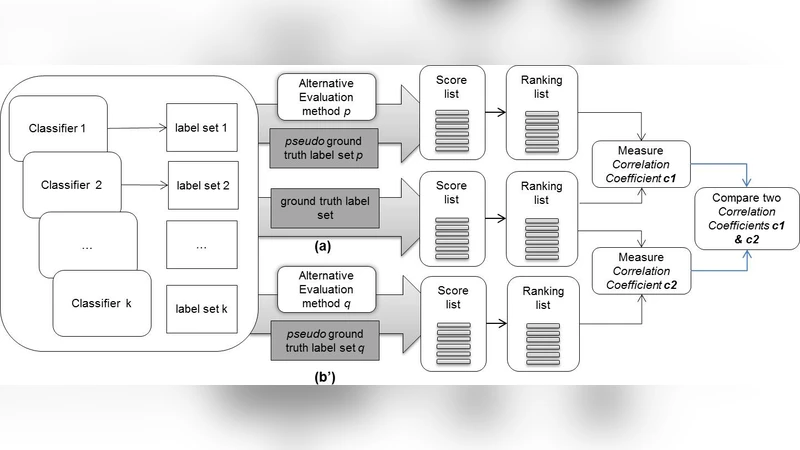
This paper considers the challenge of evaluating a set of classifiers, as done in shared task evaluations like the KDD Cup or NIST TREC, without expert labels. While expert labels provide the traditional cornerstone for evaluating statistical learners, limited or expensive access to experts represents a practical bottleneck. Instead, we seek methodology for estimating performance of the classifiers which is more scalable than expert labeling yet preserves high correlation with evaluation based on expert labels. We consider both: 1) using only labels automatically generated by the classifiers (blind evaluation); and 2) using labels obtained via crowdsourcing. While crowdsourcing methods are lauded for scalability, using such data for evaluation raises serious concerns given the prevalence of label noise. In regard to blind evaluation, two broad strategies are investigated: combine & score and score & combine methods infer a single pseudo-gold label set by aggregating classifier labels; classifiers are then evaluated based on this single pseudo-gold label set. On the other hand, score & combine methods: 1) sample multiple label sets from classifier outputs, 2) evaluate classifiers on each label set, and 3) average classifier performance across label sets. When additional crowd labels are also collected, we investigate two alternative avenues for exploiting them: 1) direct evaluation of classifiers; or 2) supervision of combine & score methods. To assess generality of our techniques, classifier performance is measured using four common classification metrics, with statistical significance tests. Finally, we measure both score and rank correlations between estimated classifier performance vs. actual performance according to expert judgments. Rigorous evaluation of classifiers from the TREC 2011 Crowdsourcing Track shows reliable evaluation can be achieved without reliance on expert labels.
💡 Research Summary
The paper tackles a practical bottleneck in large‑scale machine‑learning evaluations: the high cost and limited availability of expert‑generated ground‑truth labels. In many shared‑task settings such as the KDD Cup or NIST TREC, dozens of classifiers must be compared, yet obtaining a reliable gold standard for every test instance is often infeasible. The authors therefore investigate how to estimate classifier performance without relying on expert annotations, using two complementary sources of information: (1) the predictions that the classifiers themselves produce (blind evaluation) and (2) labels collected from crowdsourcing platforms (crowd labels).
Blind evaluation is split into two methodological families. The first, “combine‑and‑score,” aggregates the predictions of all classifiers into a single pseudo‑gold label set and then evaluates each classifier against this set. Aggregation can be as simple as majority voting, or more sophisticated, such as weighted averaging or Bayesian latent‑variable models that estimate each classifier’s reliability. The second family, “score‑and‑combine,” treats the classifier outputs as a distribution over possible labelings. It repeatedly samples multiple label sets (e.g., via bootstrap or Monte‑Carlo methods), evaluates every classifier on each sampled set, and finally averages the performance scores across samples. This approach explicitly models label uncertainty and avoids the risk of committing to a single, potentially biased pseudo‑gold set.
Crowd labels introduce a different set of challenges. While they are cheap and scalable, they are noisy and may contain systematic biases. The authors explore two ways to exploit crowd data. In the “direct evaluation” mode, crowd annotations are taken at face value and used as the reference for computing standard metrics (precision, recall, F1, MAP, NDCG). In the “supervised combine‑and‑score” mode, crowd labels are used to inform the aggregation process of blind evaluation: they provide prior estimates of each classifier’s accuracy, which are then incorporated as weights in a Bayesian combination scheme. This supervision mitigates noise in the pseudo‑gold set and improves the fidelity of the resulting performance estimates.
The experimental framework is built on the TREC 2011 Crowdsourcing Track. The authors evaluate roughly thirty participating classifiers across five widely used classification metrics. For each method, they compute Pearson and Spearman correlation coefficients between the estimated scores and the true scores derived from expert judgments, as well as Kendall’s τ for rank correlation. Results show that the weighted Bayesian version of combine‑and‑score achieves the highest correlation (Pearson > 0.92, Kendall’s τ ≈ 0.88). The score‑and‑combine family also performs well, especially when a sufficient number of label samples is drawn, yielding average correlations above 0.85. When crowd labels are used directly, correlation drops to around 0.70, reflecting their inherent noise. However, when crowd data are employed as supervision for the Bayesian aggregation, correlation improves markedly to roughly 0.82, demonstrating that modest crowdsourced effort can substantially boost evaluation quality.
Key contributions of the work are: (1) a systematic taxonomy of blind evaluation strategies that can operate without any human labels; (2) a principled integration of inexpensive crowd annotations to supervise and refine pseudo‑gold label construction; (3) extensive empirical validation on a real‑world shared‑task dataset, confirming that the proposed methods preserve high fidelity to expert‑based evaluations across multiple metrics; and (4) practical guidelines for researchers and practitioners who need to rank large numbers of models while minimizing labeling costs. The study concludes that reliable classifier evaluation is achievable without expert labels, provided that appropriate aggregation techniques and modest crowdsourced supervision are employed. This insight opens the door to more scalable, cost‑effective benchmarking pipelines in both academic research and industry deployments.
Comments & Academic Discussion
Loading comments...
Leave a Comment