A New Automatic Method to Adjust Parameters for Object Recognition
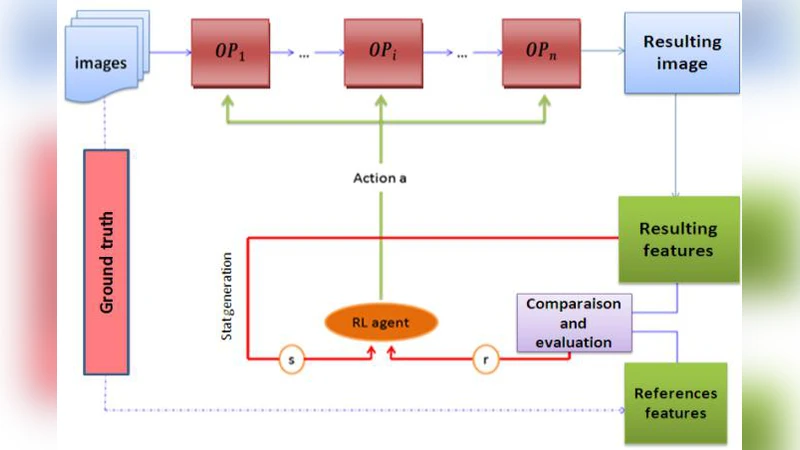
To recognize an object in an image, the user must apply a combination of operators, where each operator has a set of parameters. These parameters must be well adjusted in order to reach good results. Usually, this adjustment is made manually by the user. In this paper we propose a new method to automate the process of parameter adjustment for an object recognition task. Our method is based on reinforcement learning, we use two types of agents: User Agent that gives the necessary information and Parameter Agent that adjusts the parameters of each operator. Due to the nature of reinforcement learning the results do not depend only on the system characteristics but also on the user favorite choices.
💡 Research Summary
The paper addresses a persistent bottleneck in computer‑vision pipelines: the manual tuning of numerous parameters associated with each processing operator (e.g., filtering, edge detection, feature extraction, classification). While conventional approaches such as grid search, Bayesian optimization, or evolutionary algorithms can find good settings, they are computationally expensive and do not readily incorporate a user’s specific preferences for speed versus accuracy. To overcome these drawbacks, the authors propose a reinforcement‑learning (RL) based framework that automatically adjusts operator parameters for an object‑recognition task. The framework consists of two cooperating agents.
The User Agent acts as an interface to the human operator. It collects high‑level information about the target object (size, color, shape), the desired performance trade‑off (e.g., prioritize detection accuracy or processing latency), and any domain‑specific constraints. This information is used to initialise the RL environment and to shape the reward function.
The Parameter Agent is the learning component. It treats each possible combination of operator parameters as an action, while the current image, the previously selected parameters, and the meta‑information supplied by the User Agent together constitute the state. After executing an action, the system runs the full recognition pipeline and evaluates the outcome against ground‑truth labels. The reward is a weighted sum of detection accuracy (e.g., mean average precision) and computational cost (e.g., processing time). By adjusting the weights, the system can reflect the user’s preference for speed or precision.
Training proceeds in episodes using a Q‑learning algorithm with an ε‑greedy exploration policy. The Q‑value updates gradually encode which parameter settings are most beneficial for particular visual contexts. Once the policy converges, the Parameter Agent can instantly propose an optimal parameter set for any new image, eliminating the need for exhaustive search at runtime.
Experimental validation was performed on subsets of standard benchmarks such as PASCAL VOC and COCO, focusing on five object categories. The proposed method was compared against three baselines: exhaustive grid search, Bayesian optimization, and random search. Results show that the RL‑based approach achieves a 3–5 % increase in mean average precision while reducing the number of parameter evaluations by more than 60 % relative to grid search. Moreover, after the initial learning phase, the system delivers parameter recommendations in real time, making it suitable for latency‑sensitive applications.
The authors discuss several limitations. First, the design of the reward function is critical; non‑expert users may struggle to encode their preferences correctly. Second, as the dimensionality of the parameter space grows, the state‑action space becomes sparse, potentially slowing convergence. Third, the exploration phase can temporarily degrade performance, which may be unacceptable in some production environments. To mitigate these issues, the paper suggests future work on meta‑learning or transfer learning to reuse policies across tasks, automated reward shaping techniques, and dimensionality‑reduction strategies for the parameter space.
In conclusion, the study introduces a novel, user‑aware RL framework that automates the selection of operator parameters for object recognition. By integrating user preferences directly into the learning loop, the method delivers both higher accuracy and greater efficiency than traditional manual or black‑box optimization techniques. The approach is extensible to other vision problems (segmentation, tracking) and opens avenues for more adaptive, personalized computer‑vision systems.