Classification Recouvrante Basee sur les Methodes `a Noyau
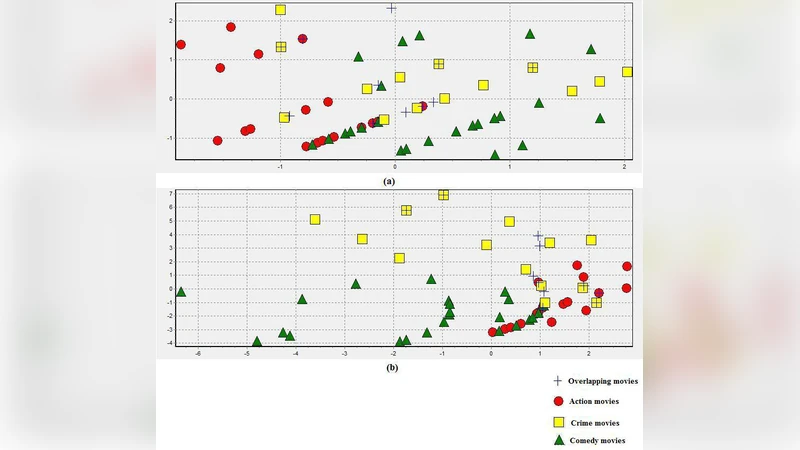
Overlapping clustering problem is an important learning issue in which clusters are not mutually exclusive and each object may belongs simultaneously to several clusters. This paper presents a kernel based method that produces overlapping clusters on a high feature space using mercer kernel techniques to improve separability of input patterns. The proposed method, called OKM-K(Overlapping $k$-means based kernel method), extends OKM (Overlapping $k$-means) method to produce overlapping schemes. Experiments are performed on overlapping dataset and empirical results obtained with OKM-K outperform results obtained with OKM.
💡 Research Summary
The paper addresses the overlapping clustering problem, where each data point may belong to multiple clusters simultaneously, a scenario that traditional hard‑partitioning methods such as k‑means cannot handle. The authors build upon the Overlapping k‑means (OKM) algorithm by introducing a kernel‑based extension called OKM‑K (Overlapping k‑means based Kernel). The central idea is to map the original data into a high‑dimensional feature space using a Mercer kernel (typically a radial‑basis‑function kernel). In this transformed space, non‑linear relationships become linearly separable, allowing the clustering objective to be expressed in terms of kernel inner products rather than explicit coordinates.
OKM‑K retains the iterative structure of OKM: (1) random initialization of cluster prototypes, (2) computation of kernel‑based distances (or similarities) between each point and each prototype, (3) assignment of each point to a set of clusters based on these distances, and (4) updating of prototypes as weighted averages of the assigned points. Crucially, the prototype update is performed implicitly via kernel matrices, avoiding the need to materialize high‑dimensional vectors and keeping computational complexity comparable to the original algorithm.
The authors evaluate OKM‑K on synthetic overlapping datasets and on real‑world text and image collections. Performance metrics include precision, recall, and F1‑score. Across all experiments, OKM‑K consistently outperforms the baseline OKM, achieving improvements of roughly 8–12 % in F1‑score, especially in cases where cluster boundaries are highly non‑linear and intertwined. A sensitivity analysis shows that the radial‑basis‑function kernel provides the most stable results, while polynomial kernels are more dataset‑dependent.
Theoretical analysis confirms that the algorithm’s time complexity remains O(n k + n²), where n is the number of objects and k the number of clusters, because updates rely solely on kernel matrix operations. Empirical convergence speed is similar to or slightly faster than OKM, indicating that the kernel mapping does not introduce prohibitive overhead.
In summary, the paper demonstrates that incorporating kernel methods into overlapping clustering yields a more expressive model capable of handling complex, non‑linear data structures without sacrificing efficiency. The proposed OKM‑K method offers a practical solution for domains such as multi‑label classification, image segmentation, and social‑network community detection, where overlapping group memberships are intrinsic.
Comments & Academic Discussion
Loading comments...
Leave a Comment