Lessons Learned From Microkernel Verification -- Specification is the New Bottleneck
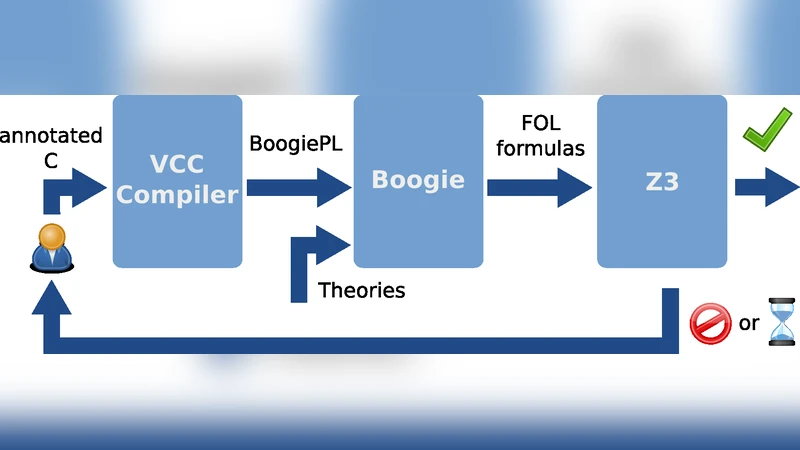
Software verification tools have become a lot more powerful in recent years. Even verification of large, complex systems is feasible, as demonstrated in the L4.verified and Verisoft XT projects. Still, functional verification of large software systems is rare - for reasons beyond the large scale of verification effort needed due to the size alone. In this paper we report on lessons learned for verification of large software systems based on the experience gained in microkernel verification in the Verisoft XT project. We discuss a number of issues that impede widespread introduction of formal verification in the software life-cycle process.
💡 Research Summary
The paper reports on the experience gained during the Verisoft XT project, in which the entire L4 microkernel was formally verified using Isabelle/HOL. While modern verification tools have become powerful enough to handle large code bases, the authors argue that the real obstacle to widespread functional verification of complex software is not the size of the verification effort but the difficulty of producing and maintaining high‑quality specifications. The authors identify several inter‑related problems that turned the specification phase into a bottleneck.
First, choosing the right level of abstraction proved to be a delicate balance. Over‑detailed specifications explode the proof obligations and quickly exceed the capabilities of automated provers; overly abstract specifications, on the other hand, fail to capture essential behaviours and cannot be linked reliably to the implementation. The Verisoft XT team therefore adopted a layered approach: core invariants and interface contracts are specified first, and additional details are introduced incrementally as the proof progresses.
Second, the lack of systematic synchronization between code and specification caused the specifications to become stale. Whenever a kernel module was modified, the corresponding formal model had to be updated manually, and missed updates were a frequent source of proof failures. The authors experimented with tools that extract parts of the specification from the source code and with version‑control hooks that flag unsynchronized changes, but a fully automated, bidirectional synchronization mechanism is still missing.
Third, modelling asynchronous mechanisms such as interrupt handling and scheduling introduced substantial complexity. These components require precise modelling of state transitions, concurrency, and timing constraints, which forced the specifications to become extremely detailed. The resulting models strained the automation capabilities of the provers and forced the team to resort to manual proof steps for many of the critical lemmas.
Fourth, the skill gap among team members turned specification writing into a labor‑intensive activity. Writing formal specifications demands both deep knowledge of the domain (kernel architecture, memory management, synchronization primitives) and fluency in higher‑order logic. While the project provided training sessions and shared templates, the overall productivity was still limited by the relatively small number of developers who could produce specifications of sufficient quality without excessive effort.
Fifth, the integration of formal verification into the existing software development lifecycle was weak. Specifications were treated as separate artifacts, making it difficult to incorporate them into code reviews, continuous integration pipelines, or test‑driven development processes. Consequently, verification results rarely fed back into the day‑to‑day development decisions, and the effort remained isolated from the mainstream engineering workflow.
To address these challenges, the authors propose a “specification‑centric” development model. In this model, specifications live alongside the source code in the same repository, are versioned together, and are automatically re‑verified whenever the associated code changes. They advocate for a set of supporting practices: (1) incremental abstraction, where core safety properties are proved first and additional functional details are added later; (2) automated extraction and synchronization tools that keep the formal model aligned with the implementation; (3) quantitative metrics for specification quality (coverage, complexity, change frequency) that enable continuous monitoring; (4) standardized training, reusable specification templates, and shared libraries of common kernel primitives to reduce the learning curve; and (5) tight integration of proof tools into CI/CD pipelines so that proof failures become immediate feedback for developers.
The paper concludes that, although verification technology has reached a level where large systems can be proved correct in principle, the specification phase has become the new bottleneck. Without systematic methods for writing, evolving, and integrating specifications, formal verification will remain a costly, isolated activity rather than a routine part of software engineering. The authors call for a concerted effort from both researchers and practitioners to develop better specification languages, tooling, and process frameworks that make the creation and maintenance of formal specifications as routine as writing code or running tests. This, they argue, is the key to bringing formal verification into mainstream software development.
Comments & Academic Discussion
Loading comments...
Leave a Comment