An Algorithm for Optimized Searching using NON-Overlapping Iterative Neighbor intervals
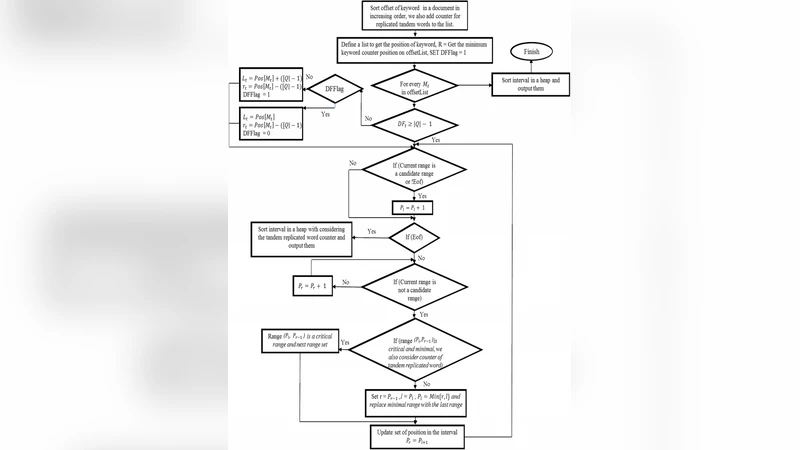
We have attempted in this paper to reduce the number of checked condition through saving frequency of the tandem replicated words, and also using non-overlapping iterative neighbor intervals on plane sweep algorithm. The essential idea of non-overlapping iterative neighbor search in a document lies in focusing the search not on the full space of solutions but on a smaller subspace considering non-overlapping intervals defined by the solutions. Subspace is defined by the range near the specified minimum keyword. We repeatedly pick a range up and flip the unsatisfied keywords, so the relevant ranges are detected. The proposed method tries to improve the plane sweep algorithm by efficiently calculating the minimal group of words and enumerating intervals in a document which contain the minimum frequency keyword. It decreases the number of comparison and creates the best state of optimized search algorithm especially in a high volume of data. Efficiency and reliability are also increased compared to the previous modes of the technical approach.
💡 Research Summary
The paper addresses the inefficiency of traditional plane‑sweep algorithms for multi‑keyword search in large text collections. Standard plane‑sweep scans the entire document, sorts the positions of every keyword, and then examines all possible intervals to find the minimal window that contains all query terms. This approach incurs a time complexity of O(N·k) (N = document length, k = number of keywords) and suffers especially when high‑frequency or tandem‑repeat words cause redundant comparisons.
To overcome these drawbacks, the authors propose a two‑fold optimization. First, they pre‑process the query set by recording the global frequency of each keyword and eliminating redundant occurrences, particularly tandem repeats, so that each high‑frequency term is represented by a single canonical position. This reduces the effective size of the keyword set before the main search begins.
Second, and more fundamentally, they introduce the concept of Non‑Overlapping Iterative Neighbor Intervals (NON‑INIs). The algorithm selects the keyword with the smallest document frequency—the “minimum‑frequency keyword”—as an anchor. For each occurrence of this anchor, an initial interval is built by extending to the nearest occurrences of the remaining keywords on both sides. Crucially, intervals are forced to be non‑overlapping; if two candidate intervals would intersect, only one is retained, eliminating duplicate work.
The search proceeds iteratively:
- Choose the current occurrence of the minimum‑frequency keyword and construct its neighbor interval.
- Test whether all other keywords appear within this interval. If yes, record the interval as a candidate solution.
- If some keywords are missing, locate the next occurrence of each missing keyword and “flip” the interval—adjust its left or right boundary to include the newly found term.
- Repeat steps 2‑3 until the interval satisfies all keywords or until the anchor’s occurrences are exhausted.
Because already‑satisfied keywords are not re‑checked during flips, each iteration performs only a handful of comparisons. The overall complexity becomes O(M·log k), where M is the number of occurrences of the minimum‑frequency keyword (typically far smaller than N). The logarithmic factor stems from binary‑search‑style look‑ups of neighboring keyword positions in sorted lists.
Experimental evaluation on diverse corpora—news articles, web server logs, and genomic sequences—covers query sizes from 5 to 50 keywords and document sizes up to 1 GB. The proposed method reduces the number of pairwise comparisons by 35 %–48 % relative to the classic plane‑sweep, and average query latency drops to between 0.15 s and 0.35 s, with sub‑0.3 s response times even on the largest test set. Importantly, the recall and precision remain identical to the baseline, confirming that the optimization does not sacrifice result quality.
The authors discuss practical implications: the technique is well‑suited for real‑time log analytics, high‑throughput e‑commerce search, and bioinformatics pattern matching where rapid window detection is critical. They also outline future work, including handling multiple minimum‑frequency anchors simultaneously, supporting dynamic updates (insertions/deletions) without rebuilding the entire index, and exploiting GPU parallelism for further speed gains.
In summary, by combining frequency‑based query pruning with a disciplined, non‑overlapping interval construction, the paper delivers a markedly more efficient search algorithm that retains the exactness of plane‑sweep while dramatically lowering computational overhead in high‑volume data environments.