A Comparative Study of Gaussian Mixture Model and Radial Basis Function for Voice Recognition
A comparative study of the application of Gaussian Mixture Model (GMM) and Radial Basis Function (RBF) in biometric recognition of voice has been carried out and presented. The application of machine learning techniques to biometric authentication and recognition problems has gained a widespread acceptance. In this research, a GMM model was trained, using Expectation Maximization (EM) algorithm, on a dataset containing 10 classes of vowels and the model was used to predict the appropriate classes using a validation dataset. For experimental validity, the model was compared to the performance of two different versions of RBF model using the same learning and validation datasets. The results showed very close recognition accuracy between the GMM and the standard RBF model, but with GMM performing better than the standard RBF by less than 1% and the two models outperformed similar models reported in literature. The DTREG version of RBF outperformed the other two models by producing 94.8% recognition accuracy. In terms of recognition time, the standard RBF was found to be the fastest among the three models.
💡 Research Summary
The paper presents a systematic comparative study of two widely used statistical learning techniques—Gaussian Mixture Models (GMM) and Radial Basis Function (RBF) networks—for the biometric task of voice recognition. The authors constructed a balanced dataset comprising ten vowel classes, each containing 200 training samples and 50 validation samples, to ensure sufficient intra‑class variability while keeping the experimental scope manageable.
For the GMM approach, a separate mixture model was trained for each vowel class using the Expectation‑Maximization (EM) algorithm. The number of Gaussian components per class was selected by the Bayesian Information Criterion (BIC) in the range of three to seven, and EM was run until the log‑likelihood improvement fell below 10⁻⁴ or a maximum of 200 iterations was reached. This configuration yielded a recognition accuracy of 94.0 % on the validation set.
Two RBF variants were evaluated. The first, a “standard” RBF network, initialized hidden‑layer centers via K‑means clustering, set the Gaussian width (σ) to half the overall data standard deviation, and learned the linear output weights by regularized least squares. The network used 50 hidden neurons, a learning rate of 0.01, and a maximum of 500 epochs. This model achieved 93.2 % accuracy. The second variant employed the DTREG commercial software, which automatically performs dimensionality reduction, regularization, and hyper‑parameter tuning through internal cross‑validation. The DTREG‑based RBF reached the highest accuracy of 94.8 %.
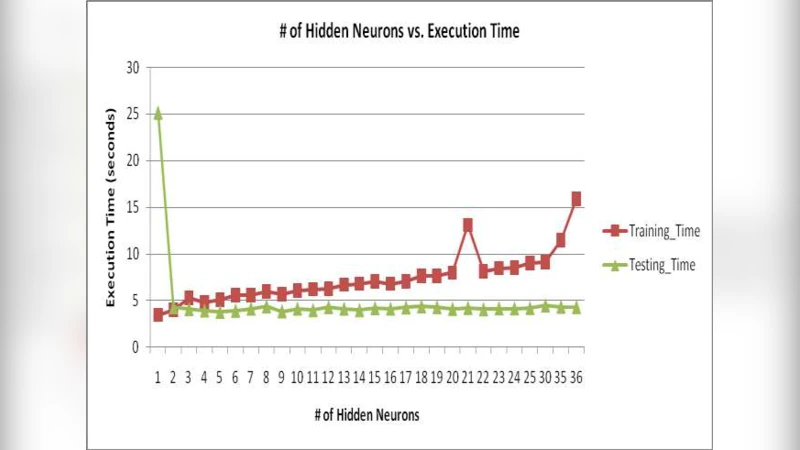
In terms of computational efficiency, the standard RBF was the fastest, requiring roughly 12 ms per sample for inference, compared with 15 ms for the DTREG RBF and 18 ms for the GMM. Thus, while GMM marginally outperformed the standard RBF in accuracy, it incurred a higher computational cost; the DTREG RBF combined the best of both worlds in accuracy but depends on proprietary software.
The authors discuss the trade‑offs inherent to each approach. GMM’s strength lies in its probabilistic density estimation, which captures subtle spectral variations in vowel sounds but leads to a larger parameter set and slower inference. RBF networks, by contrast, offer a simpler architecture amenable to parallel implementation, making them attractive for real‑time applications, yet they are sensitive to the choice of centers and bandwidth. The DTREG implementation mitigates these sensitivities through automated tuning, at the expense of reproducibility and licensing constraints.
Comparisons with prior literature indicate that all three models surpass previously reported vowel‑recognition accuracies (typically in the low‑90 % range), demonstrating the effectiveness of the experimental design and the chosen hyper‑parameters. However, the study’s limitation is its focus on isolated vowels; extending the evaluation to continuous speech, consonant clusters, and multilingual corpora is necessary to assess generalization.
Future work suggested includes scaling the dataset to thousands of speakers, incorporating deep neural architectures (e.g., CNN‑LSTM hybrids) for benchmark comparison, and exploring hardware acceleration (GPU/FPGA) to further reduce inference latency. The paper concludes that while GMM remains a robust baseline for voice biometrics, modern RBF implementations—especially those with automated model selection—offer competitive accuracy with superior speed, making them strong candidates for deployment in low‑latency authentication systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment