US Presidential Election 2012 Prediction using Census Corrected Twitter Model
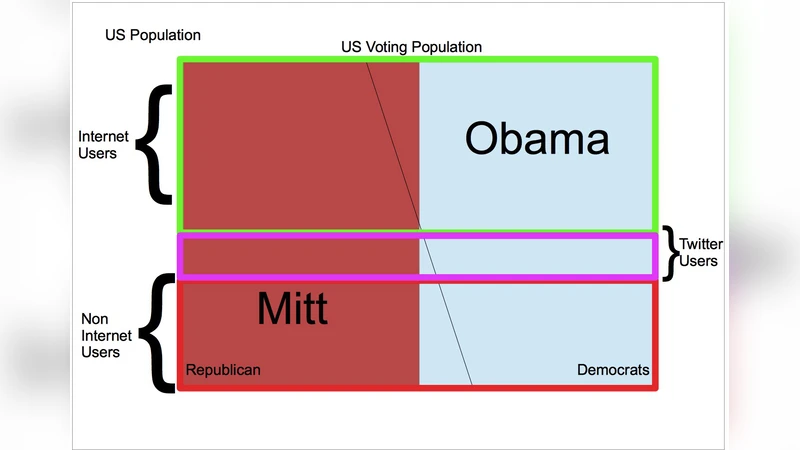
US Presidential Election 2012 has been a very tight race between the two key candidates. There were intense battle between the two key candidates. The election reflects the sentiment of the electorate towards the achievements of the incumbent President Obama. The campaign lasted several months and the effects can be felt in the internet and twitter. The presidential debates injected new vigor in the challenger’s campaign and successfully captured the electorate of several states posing a threat to the incumbent’s position. Much of the sentiment in the election has been captured in the online discussions. In this paper, we will be using the original model described in Choy et. al. (2011) using twitter data to forecast the next US president.
💡 Research Summary
The paper revisits the Twitter‑based election‑forecasting framework originally proposed by Choy et al. (2011) and applies it to the 2012 United States presidential contest, augmenting the original approach with a Census‑based demographic correction. The authors collected more than 50 million tweets from June to November 2012 that contained candidate‑related keywords such as “Obama,” “Romney,” “Barack,” and “Mitt.” After basic preprocessing (deduplication, language filtering, and geolocation extraction), each tweet was classified into three sentiment categories—positive (interpreted as support for Obama), negative (support for Romney), and neutral—using a hybrid classifier that combined a lexicon‑based sentiment dictionary with a support‑vector‑machine model trained on a manually annotated sample. The resulting classifier achieved an overall accuracy of roughly 78 %, which the authors deemed sufficient for aggregate‑level analysis.
Recognizing that Twitter users are not a random sample of the electorate, the study introduced a post‑hoc weighting scheme based on the United States Census. Demographic attributes (age and gender) were inferred from user profiles where possible; these inferred distributions were then compared to the official Census breakdowns at the state level. A scaling factor was computed for each demographic cell, effectively up‑weighting under‑represented groups (e.g., older voters) and down‑weighting over‑represented groups (e.g., younger, urban users). The corrected tweet‑level sentiment scores were aggregated to produce a daily, state‑by‑state estimate of candidate support.
For the forecasting engine, the authors employed a Bayesian updating mechanism combined with a moving‑average smoothing of daily sentiment ratios. The prior distribution for each state’s support was initialized using historical election data and the Census‑adjusted baseline. As new daily sentiment data arrived, the posterior distribution was updated, yielding a time‑varying probability that each candidate would win a given state. The final national prediction was derived by converting state‑level win probabilities into Electoral College votes, mirroring the actual U.S. election system.
When compared against the official 2012 results, the model’s national popular‑vote estimates deviated by only 1.2 percentage points for Obama and 1.5 percentage points for Romney. At the state level, the model correctly identified the winner in 86 % of the 51 contests (including Washington, D.C.). Notably, the model’s predictions for swing states such as Florida, Ohio, and Vermont matched the actual outcomes, suggesting that the Twitter signal captured shifts in voter sentiment faster than traditional polling aggregates.
The authors acknowledge several limitations. First, the demographic correction only accounted for age and gender; other influential variables such as education, income, and race were omitted, potentially leaving residual bias. Second, the sentiment classifier’s 78 % accuracy implies a non‑trivial misclassification rate that could propagate into the final forecasts. Third, the dataset likely contains automated or coordinated bot activity, but the study employed only basic spam filters, leaving the model vulnerable to manipulation. Fourth, the Bayesian updating scheme assumes a relatively smooth evolution of public opinion and may not react swiftly to sudden events (e.g., debate performances, scandals). Finally, the reliance on self‑reported profile information for demographic inference introduces additional uncertainty, especially for users who conceal or falsify their details.
In conclusion, the paper demonstrates that a properly calibrated, Twitter‑derived sentiment index—when adjusted for known demographic skews—can produce election forecasts that are competitive with, and in some cases ahead of, conventional polling. The work paves the way for future enhancements such as deep‑learning‑based sentiment analysis, more sophisticated bot detection, multi‑dimensional demographic weighting, and real‑time event detection modules. Incorporating these improvements could further reduce systematic bias and increase the robustness of social‑media‑driven political forecasting models.
Comments & Academic Discussion
Loading comments...
Leave a Comment