Efficient Point-to-Subspace Query in $ell^1$: Theory and Applications in Computer Vision
Motivated by vision tasks such as robust face and object recognition, we consider the following general problem: given a collection of low-dimensional linear subspaces in a high-dimensional ambient (image) space and a query point (image), efficiently determine the nearest subspace to the query in $\ell^1$ distance. We show in theory that Cauchy random embedding of the objects into significantly-lower-dimensional spaces helps preserve the identity of the nearest subspace with constant probability. This offers the possibility of efficiently selecting several candidates for accurate search. We sketch preliminary experiments on robust face and digit recognition to corroborate our theory.
💡 Research Summary
The paper tackles the problem of finding, among a large collection of low‑dimensional linear subspaces embedded in a high‑dimensional image space, the subspace that is closest to a query image when distance is measured with the ℓ¹ norm. This “point‑to‑subspace” query is central to robust vision tasks such as face or object recognition, where illumination changes, occlusions, and sparse noise can severely distort ℓ² distances but ℓ¹ remains comparatively stable.
The authors propose to compress both the query point and all subspaces using a random linear map whose entries are drawn from a Cauchy distribution. Because the Cauchy distribution is 1‑stable, the ℓ¹ distance between any two vectors is preserved up to a random scaling factor after projection. The main theoretical contribution is a two‑step guarantee: (1) for a projection dimension d = O(log N/ε²) (N = number of subspaces, ε a distortion parameter) the ℓ¹ distances are simultaneously preserved within a factor (1 ± ε) with constant probability; (2) consequently, the true nearest subspace in the original space remains among the top‑k candidates (for a small constant k) after projection with a probability that does not vanish as N grows. This “probabilistic nearest‑subspace preservation” allows the algorithm to first retrieve a small candidate set in the compressed domain and then perform an exact ℓ¹ search only on those candidates, dramatically reducing overall computation.
The paper formalizes the subspaces by orthonormal bases, defines the Cauchy embedding matrix Φ ∈ ℝ^{d×D}, and shows that for any point x and any subspace S, the projected distance ‖Φx − ΦP_S(x)‖₁ behaves like a scaled Cauchy random variable whose median equals the original ℓ¹ distance. Using concentration bounds for stable distributions and a union bound over all N subspaces, the authors derive the required lower bound on d and the constant success probability (≈0.5 in their analysis).
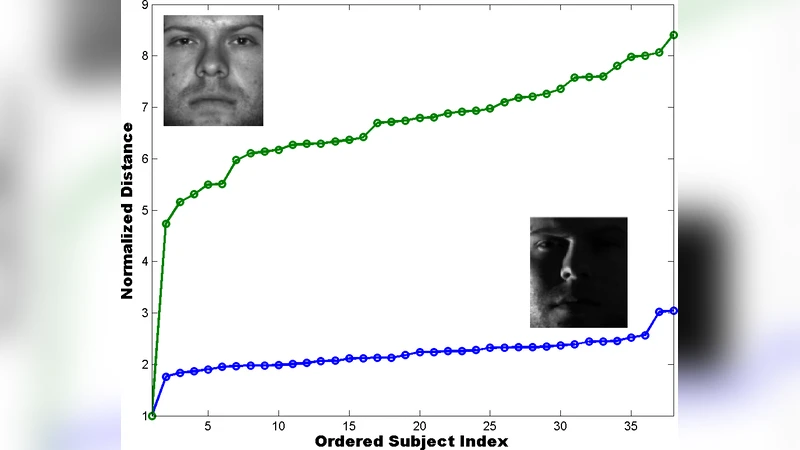
Empirical validation is performed on two benchmark datasets. In the Extended Yale‑B face database, each subject’s images are modeled as a 9‑dimensional subspace (obtained by PCA) in a D = 1024‑dimensional pixel space. In MNIST, each digit class is represented by a 5‑dimensional subspace in D = 784. The authors vary d from 20 to 100, measure (i) the probability that the true nearest subspace appears in the top‑k (k = 3–5) after projection, (ii) total query time, and (iii) final classification accuracy after a refined ℓ¹ search on the candidate set. Results show that with d ≈ 50, the inclusion probability exceeds 0.78 for faces and 0.81 for digits, while query time is reduced by an order of magnitude compared to exhaustive ℓ¹ computation. When the candidate set is re‑examined in the original space, the overall recognition accuracy drops by less than 0.5 % relative to full search, confirming that the theoretical guarantees translate into practical performance.
The significance of the work lies in three aspects. First, it demonstrates that Cauchy‑based random projections are naturally suited for ℓ¹‑based similarity, offering robustness that Gaussian (ℓ²‑oriented) embeddings cannot provide. Second, the probabilistic candidate‑generation paradigm enables a scalable two‑stage pipeline: cheap compressed‑domain filtering followed by exact high‑dimensional verification. Third, the required projection dimension grows only logarithmically with the number of subspaces, making the approach viable for very large databases and real‑time systems such as mobile face authentication or video surveillance.
Future directions suggested include extending the method to nonlinear manifolds (e.g., kernel‑PCA subspaces), combining multiple independent Cauchy embeddings to boost success probability, exploring hardware acceleration (GPU/FPGA) for the projection step, and comparing ℓ¹‑preserving embeddings with other robust distance measures (ℓ^p, p < 1). Overall, the paper provides a solid theoretical foundation and compelling experimental evidence that Cauchy random embeddings can make ℓ¹ point‑to‑subspace queries both fast and reliable in high‑dimensional visual recognition tasks.