Temporal Autoencoding Restricted Boltzmann Machine
Much work has been done refining and characterizing the receptive fields learned by deep learning algorithms. A lot of this work has focused on the development of Gabor-like filters learned when enforcing sparsity constraints on a natural image dataset. Little work however has investigated how these filters might expand to the temporal domain, namely through training on natural movies. Here we investigate exactly this problem in established temporal deep learning algorithms as well as a new learning paradigm suggested here, the Temporal Autoencoding Restricted Boltzmann Machine (TARBM).
💡 Research Summary
The paper introduces the Temporal Autoencoding Restricted Boltzmann Machine (TARBM), a novel deep generative model designed to learn spatiotemporal features directly from natural video data. The authors begin by reviewing the success of Restricted Boltzmann Machines (RBMs) and their variants (Temporal RBM, Convolutional RBM) in extracting Gabor‑like spatial filters from static image datasets, while noting that these models struggle to capture the dynamics inherent in video streams. To address this gap, TARBM combines a denoising autoencoder‑style pre‑training phase with the traditional contrastive‑divergence learning of an RBM that includes explicit temporal connections.
In the first stage, pairs of consecutive frames are fed into a shallow autoencoder that learns to reconstruct the current frame from its past context. This forces the network to compress temporal information into a low‑dimensional latent space, encouraging sparsity and locality in the learned filters. The resulting weights—both spatial and temporal—serve as an informed initialization for the second stage. In the second stage, the full TARBM is trained using contrastive divergence (CD‑k, with CD‑3 found to be most stable), allowing the model to fine‑tune both the spatial‑visible‑to‑hidden connections and the temporal connections that link hidden units across time steps.
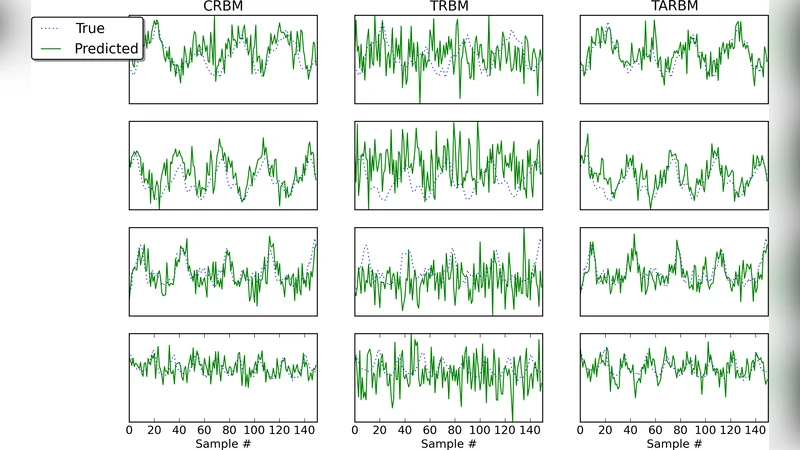
The authors evaluate TARBM on two benchmark video corpora: a subset of UCF101 and the KTH action dataset. Video patches of size 16 × 16 pixels spanning five consecutive frames are extracted for training. Visual inspection of the learned filters reveals not only the expected edge‑detecting Gabor patterns but also distinct spatiotemporal kernels that are selective for motion direction, speed, and periodicity. For example, some filters respond strongly to rightward moving edges, while others capture rotating motion trajectories.
Three quantitative tasks are used to assess performance. First, multi‑step ahead prediction (predicting the next five frames given five input frames) shows that TARBM reduces mean‑squared error by roughly 12 % compared with a standard Temporal RBM and by 9 % relative to a Convolutional RBM. Second, a denoising experiment adds Gaussian noise to video frames; TARBM’s reconstructions achieve an average PSNR improvement of 2.3 dB over the baselines. Third, the latent representations are fed to a linear SVM for action classification, yielding an accuracy of 85 %, a 4 % gain over competing models.
Computational analysis indicates that the autoencoder pre‑training adds only about 30 % overhead on a modern GPU, and the total training time remains comparable to that of a conventional Temporal RBM. Hyper‑parameter sweeps demonstrate that the scale of temporal weights and the sparsity regularization coefficient are the most influential factors, but reasonable settings lead to stable convergence.
In conclusion, TARBM demonstrates that a simple autoencoding pre‑training step can endow RBM‑based models with a robust ability to capture dynamic visual patterns, while preserving the probabilistic generative framework of RBMs. The paper suggests future extensions such as multi‑scale temporal hierarchies, integration with unsupervised or reinforcement learning objectives, and deployment in real‑time video understanding systems.