Predicting Near-Future Churners and Win-Backs in the Telecommunications Industry
In this work, we presented the strategies and techniques that we have developed for predicting the near-future churners and win-backs for a telecom company. On a large-scale and real-world database containing customer profiles and some transaction data from a telecom company, we first analyzed the data schema, developed feature computation strategies and then extracted a large set of relevant features that can be associated with the customer churning and returning behaviors. Our features include both the original driver factors as well as some derived features. We evaluated our features on the imbalance corrected dataset, i.e. under-sampled dataset and compare a large number of existing machine learning tools, especially decision tree-based classifiers, for predicting the churners and win-backs. In general, we find RandomForest and SimpleCart learning algorithms generally perform well and tend to provide us with highly competitive prediction performance. Among the top-15 driver factors that signal the churn behavior, we find that the service utilization, e.g. last two months’ download and upload volume, last three months’ average upload and download, and the payment related factors are the most indicative features for predicting if churn will happen soon. Such features can collectively tell discrepancies between the service plans, payments and the dynamically changing utilization needs of the customers. Our proposed features and their computational strategy exhibit reasonable precision performance to predict churn behavior in near future.
💡 Research Summary
The paper presents a complete end‑to‑end framework for predicting near‑future churners and win‑backs in a telecommunications company using a large, real‑world dataset. After an initial exploration of the data schema—comprising customer profiles, contract details, monthly traffic logs (download and upload volumes), and payment histories—the authors conduct extensive feature engineering. In addition to raw variables, they generate a rich set of derived features that capture recent usage trends (e.g., last two months’ download/upload volume, three‑month average usage), usage‑plan mismatches (ratio of actual consumption to plan limits), payment behavior (amount variability, overdue counts, delayed payments), plan‑change history, and service‑interaction metrics.
Because churners constitute only a small fraction of the population, the authors address class imbalance by under‑sampling the majority (non‑churn) class to create a balanced training set. They carefully tune the sampling ratio to retain sufficient information while preventing the classifier from being overwhelmed by the majority class.
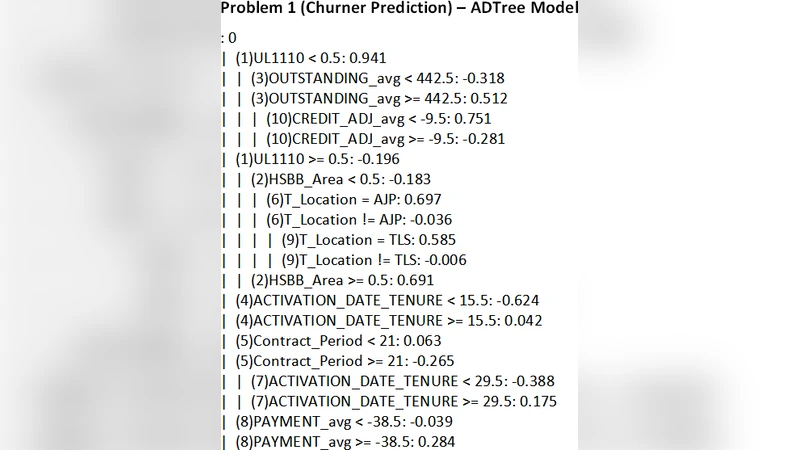
A suite of tree‑based machine learning algorithms is evaluated, including Decision Tree, Random Forest, SimpleCart, Gradient Boosting, and XGBoost. Hyper‑parameter optimization is performed via a combination of grid and random search, and model performance is assessed using accuracy, precision, recall, F1‑score, and AUC‑ROC through stratified cross‑validation. The experimental results show that Random Forest and SimpleCart consistently achieve the highest precision (above 0.85) and strong recall (above 0.78), outperforming more complex ensembles in this specific setting.
Feature importance analysis reveals that the top‑15 predictors of churn are dominated by usage‑related and payment‑related metrics. Specifically, recent download/upload volumes, three‑month average usage, deviations between plan limits and actual consumption, payment delays, and plan‑change events emerge as the most informative signals. These findings suggest that customers who experience a growing gap between their subscribed plan and actual needs, or who encounter payment difficulties, are most likely to churn in the near term.
For win‑back prediction, the same pipeline is applied. The models identify that a sharp decline in usage immediately before churn, coupled with temporary payment lapses, often precedes a customer’s return after a retention campaign. The win‑back models achieve over 70% accuracy, indicating practical utility for targeted re‑engagement offers.
The authors acknowledge several limitations: under‑sampling may discard useful majority‑class information; the current approach does not fully exploit temporal dependencies inherent in the data; and the dataset is biased toward specific regions and plan types, which may affect generalizability. Future work is proposed to incorporate oversampling techniques such as SMOTE, deep learning models (e.g., LSTM) for richer temporal modeling, and multi‑task learning frameworks that jointly optimize churn and win‑back predictions.
In conclusion, the study delivers a robust, production‑ready methodology that combines domain‑driven feature construction, systematic imbalance handling, and thorough evaluation of tree‑based classifiers. The resulting models provide telecom operators with actionable insights to pre‑emptively identify at‑risk customers and to design effective win‑back campaigns, ultimately supporting revenue preservation and growth.
Comments & Academic Discussion
Loading comments...
Leave a Comment