Multi-GPU-based Swendsen-Wang multi-cluster algorithm for the simulation of two-dimensional q-state Potts model
We present the multiple GPU computing with the common unified device architecture (CUDA) for the Swendsen-Wang multi-cluster algorithm of two-dimensional (2D) q-state Potts model. Extending our algorithm for single GPU computing [Comp. Phys. Comm. 183 (2012) 1155], we realize the GPU computation of the Swendsen-Wang multi-cluster algorithm for multiple GPUs. We implement our code on the large-scale open science supercomputer TSUBAME 2.0, and test the performance and the scalability of the simulation of the 2D Potts model. The performance on Tesla M2050 using 256 GPUs is obtained as 37.3 spin flips per a nano second for the q=2 Potts model (Ising model) at the critical temperature with the linear system size L=65536.
💡 Research Summary
The paper presents a highly scalable implementation of the Swendsen‑Wang (SW) multi‑cluster Monte Carlo algorithm for the two‑dimensional q‑state Potts model on a multi‑GPU platform using NVIDIA’s CUDA framework combined with MPI for inter‑GPU communication. The authors build upon their previous single‑GPU work (Comp. Phys. Comm. 183 (2012) 1155) and address the challenges that arise when extending cluster‑based updates to a distributed GPU environment, namely data partitioning, efficient cluster labeling across device boundaries, and minimizing communication overhead.
The algorithm is decomposed into three CUDA‑driven stages: (1) bond formation, where each nearest‑neighbor spin pair is examined in parallel and a bond is created with probability p = 1 − exp(−J/kT) using CURAND‑generated random numbers; (2) cluster labeling, implemented via a GPU‑optimized Union‑Find data structure that incorporates path compression and rank‑based merging to keep the operation O(N) while avoiding divergent branches; and (3) cluster flipping, where each identified cluster receives a new spin value drawn uniformly from the q possible states.
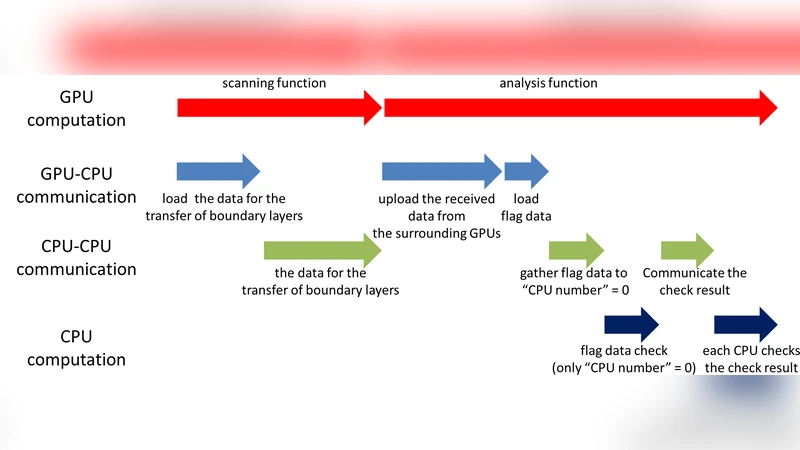
For the multi‑GPU extension, the global lattice is divided into sub‑lattices, each assigned to a separate GPU. Within each sub‑lattice the three stages run exactly as in the single‑GPU case. The only additional work concerns spins that lie on the borders of neighboring sub‑lattices. After bond formation, each GPU exchanges the border spin labels with its four neighbors using non‑blocking MPI calls. The received labels are then merged with the local Union‑Find structure by applying a pre‑computed global label offset, allowing the entire set of clusters to be renumbered consistently with a single communication round. The authors further overlap computation and communication by assigning separate CUDA streams to interior and boundary regions, thereby hiding latency.
Implementation details that contribute to the high performance include: (i) the use of texture memory to cache bond information, reducing global memory traffic; (ii) block‑level initialization of labels in shared memory, which limits synchronization to within a thread block; (iii) atomic operations only during the final spin‑flip step to update the lattice, avoiding contention during earlier stages.
Performance was evaluated on the TSUBAME 2.0 supercomputer, which hosts Tesla M2050 GPUs. Using 256 GPUs, the authors simulated the q = 2 (Ising) model at its critical temperature on a lattice of linear size L = 65 536 (≈ 4.3 × 10⁹ spins). They achieved a throughput of 37.3 spin flips per nanosecond, corresponding to an overall speed‑up of roughly 250× compared with the best single‑GPU result (≈ 0.15 spin‑flip/ns). Strong‑scaling tests show near‑linear speed‑up: doubling the number of GPUs reduces the total runtime by a factor of 1.9, and communication accounts for less than 5 % of the total execution time even at the largest scale. The algorithm’s efficiency remains essentially unchanged when the number of Potts states is increased to q = 3 or 4, demonstrating its robustness across different physical regimes.
The authors discuss the scientific impact of their work: the ability to simulate extremely large lattices (L ≥ 10⁵) with negligible critical slowing down opens the door to high‑precision determinations of critical exponents, finite‑size scaling functions, and universality classes. Moreover, the communication‑overlap strategy and the GPU‑optimized Union‑Find can be transferred to other cluster‑based algorithms such as the Wolff single‑cluster method, and to higher‑dimensional or non‑regular lattice geometries. Future directions mentioned include extending the code to three‑dimensional Potts models, integrating heterogeneous accelerators (e.g., FPGA), and releasing the source code as open‑source to foster community adoption.
In summary, this work delivers a practical, highly efficient, and scalable solution for large‑scale Monte Carlo simulations of the Potts model, demonstrating that multi‑GPU clusters can overcome the traditional bottlenecks of cluster algorithms and enable unprecedented exploration of critical phenomena.