Disentangling Factors of Variation via Generative Entangling
Here we propose a novel model family with the objective of learning to disentangle the factors of variation in data. Our approach is based on the spike-and-slab restricted Boltzmann machine which we generalize to include higher-order interactions amo…
Authors: Guillaume Desjardins, Aaron Courville, Yoshua Bengio
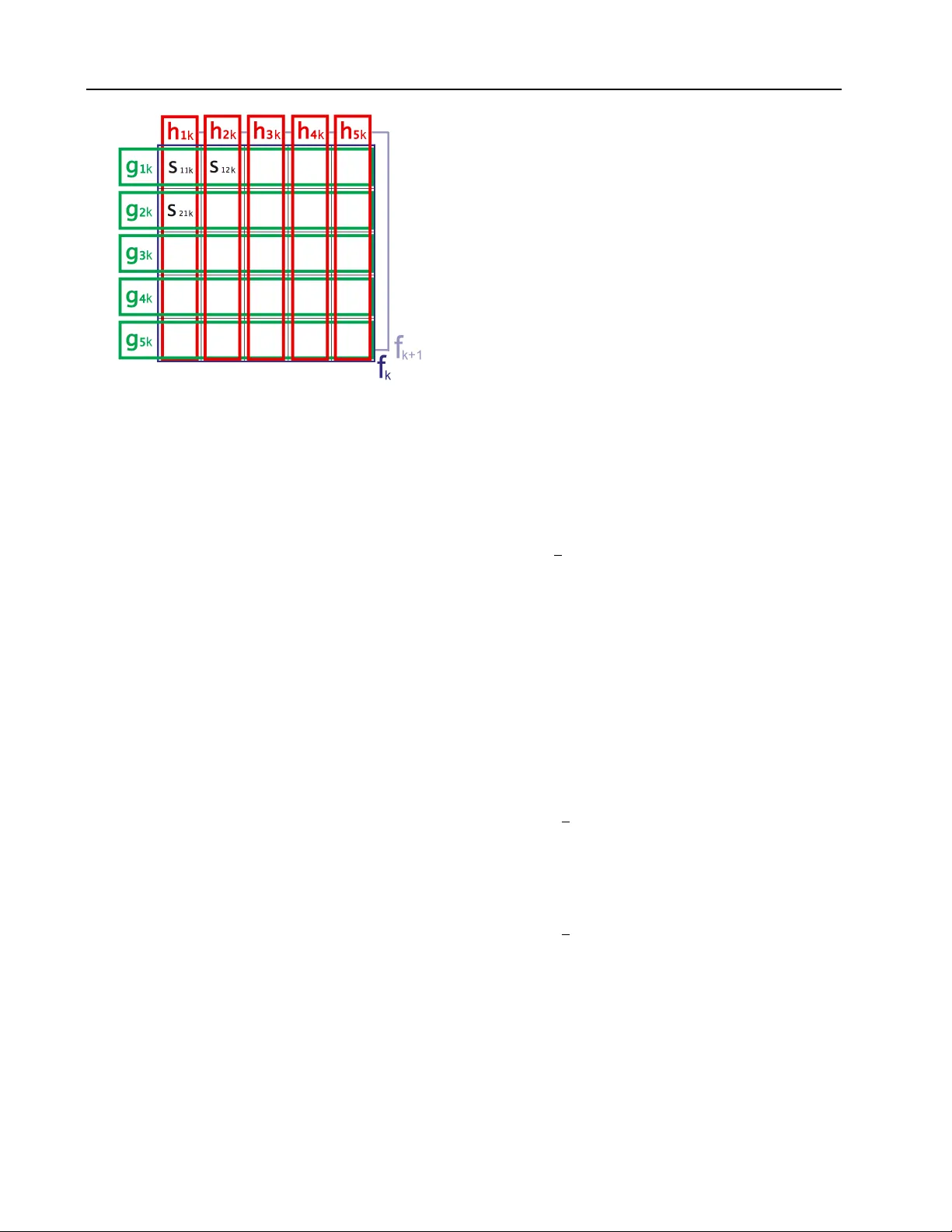
Disen tangling F actors of V ariation via Generativ e En tangling Guillaume Desjardins desjagui@ir o.umontreal.ca Aaron Courville cour vila@iro.umontreal.ca Y osh ua Bengio bengioy@ir o.umontreal.ca D ´ epartemen t d’informatique et de recherc he op., Universit ´ e de Montr ´ eal Montr ´ eal, QC H3C 3J7 CANADA Abstract Here w e prop ose a no vel mo del family with the ob jective of learning to disentangle the factors of v ariation in data. Our approach is based on the spik e-and-slab restricted Boltz- mann mac hine whic h w e generalize to include higher-order interactions among multiple la- ten t v ariables. Seen from a generative p er- sp ectiv e, the multiplicativ e interactions em- ulates the entangling of factors of v ariation. Inference in the mo del can b e seen as dis- en tangling these generative factors. Unlik e previous attempts at disentangling laten t fac- tors, the prop osed mo del is trained using no sup ervised information regarding the laten t factors. W e apply our mo del to the task of facial expression classification. 1. In tro duction In man y machi ne learning tasks, data originates from a generative pro cess inv olving complex in teraction of m ultiple factors. Alone eac h factor accounts for a source of v ariabilit y in the data. T ogether their inter- action gives rise to the rich structure c haracteristic of man y of the most challenging domains of application. Consider, for example, the task of facial expression recognition. Two images of differen t individuals with the same facial expression may result in images that are w ell separated in pixel space. On the other hand, t wo images of the same individuals showing different expressions may w ell be positioned v ery close together in pixel space. In this simplified scenario, there are t wo factors at play: (1) the iden tity of the individual, and (2) the facial expression. One of these factors, the iden tity , is irrelev an t to the task of facial expres- sion recognition and yet of the tw o factors it could w ell dominate the represen tation of the image in pixel space. As a result, pixel space-based facial expression recognition systems seem likely to suffer p oor p erfor- mance due to the v ariation in appearance of individual faces. Imp ortan tly , these interacting factors frequently do not com bine as simple sup erpositions that can b e eas- ily separated by c ho osing an appropriate affine pro jec- tion of the data. Rather, these factors often appear tigh tly entangle d in the ra w data. Our challenge is to construct representations of the data that cope with the reality of entangled factors of v ariation and pro- vide features that may b e appropriate to a wide v ariet y of possible tasks. In the con text of our face data exam- ple, a representation capable of disentangling identit y and expression would b e an effective representation for either the facial recognition or facial expression classi- fication. In an effort to cop e with these factors of v ariation, there has been a broad-based mo vemen t in mac hine learning and in application domains such as computer vision to ward hand-engineering feature sets that are invariant to common sources of v ariation in data. This is the motiv ation be hind b oth the inclusion of fea- ture po oling stages in the conv olutional net work ar- c hitecture ( LeCun et al. , 1989 ) and the recent trend to ward representations based on large scale p ooling of lo w-level features ( W ang et al. , 2009 ; Coates et al. , 2011 ). These approaches all stem from the p o werful idea that inv ariant features of the data can b e induced through the po oling together of a set of simple filter re- sp onses. P otentially even more p ow erful is the notion that one can actually le arn which filters to b e p ooled together from purely unsupervised data, and thereb y extract directions of v ariance ov er whic h the po oling features b ecome in v arian t ( Kohonen et al. , 1979 ; Ko- honen , 1996 ; Hyv¨ arinen and Hoy er , 2000 ; Le et al. , 2010 ; Kavuk cuoglu et al. , 2009 ; Ranzato and Hinton , 2010 ; Courville et al. , 2011b ). Ho wev er, in situations where there are m ultiple relev ant but en tangled fac- tors of v ariation that give rise to the data, we require a means of feature extraction that disentangles these factors in the data rather than simply learn to repre- sen t some of these factors at the expense of those that Disen tangling F actors of V ariation via Generative Entangling are lost in the filter p o oling op eration. Here we prop ose a nov el model family with the ob- jectiv e of le arning to disentangle the factors of v aria- tion eviden t in the data. Our approac h is based on the spike-and-slab restricted Boltzmann mac hine (ss- RBM) ( Courville et al. , 2011a ) which has recently been sho wn to b e a promising model of natural image data. W e generalize the ssRBM to include higher-order inter- actions among multiple binary latent v ariables. Seen from a generative persp ective, the multiplicativ e in- teractions of the binary latent v ariables emulates the en tangling of the factors that give rise to the data. Con versely , inference in the mo del can b e seen as an attempt to assign credit to the v arious interacting fac- tors for their com bined accoun t of the data – in effect, to disentangle the generative factors. Our approac h re- lies only on unsupervised approximate maxim um like- liho od learning of the mo del parameters, and as suc h w e do not require the use of an y lab el information in defining the factors to b e disentangled. W e b eliev e this to b e a research direction of critical imp ortance, as it is almost never the case that lab el information exists for all factors resp onsible for v ariations in the data distribution. 2. Learning In v arian t F eatures V ersus Learning to Disen tangle F eatures The principle that in v ariant features can actually emer ge , using only unsupervised learning, from the or- ganization of features in to subspaces was first estab- lished in the ASSOM mo del ( Kohonen , 1996 ). Since then, the same basic strategy has reappeared in a n umber of different mo dels and learning paradigms, including top ological indep enden t comp onen t analy- sis ( Hyv¨ arinen and Hoy er , 2000 ; Le et al. , 2010 ), in v ariant predictive sparse decomp osition (IPSD) ( Ka vukcuoglu et al. , 2009 ), as well as in Boltzmann mac hine-based approaches ( Ranzato and Hin ton , 2010 ; Courville et al. , 2011b ). In each case, the basic strat- egy is to group filters together b y , for example, using a v ariable (the p ooling feature) that gates the activ ation for all elements of the group. This gated activ ation mec hanism causes the filters within the group to share a common window on the dataset, whic h in turn leads to filter groups composed of m utually complemen tary filters. In the end, the span of the filter vectors defines a subspace which sp ecifies the directions in which the p ooling feature is inv ariant. Somewhat surprisingly , this basic strategy has rep eatedly demonstrated that useful in v arian t features can b e learned in a strictly unsup ervised fashion, using only the statistical struc- ture inherent in the data. While remark able, one im- p ortan t problem with using this learning strategy is that the inv ariant represen tation formed b y the p o ol- ing features offers a somewhat incomplete view on the data as the detailed representation of the lo wer-lev el features is abstracted aw a y in the p o oling pro cedure. While we would lik e higher level features to b e more abstract and exhibit greater in v ariance, w e ha ve little con trol ov er what information is lost through feature subspace p o oling. In v ariant features, b y definition, ha v e reduced sensi- tivit y in the direction of inv ariance. This is the goal of building inv arian t features and fully desirable if the directions of inv ariance all reflect sources of v ariance in the data that are uninformativ e to the task at hand. Ho wev er, it is often the case that the goal of feature extraction is the disentangling or separation of man y distinct but informativ e factors in the data. In this sit- uation, the metho ds of generating inv ariant features – namely , the feature subspace metho d – may be inade- quate. Returning to our facial expression classification example from the in tro duction, consider a p ooling fea- ture made inv ariant to the expression of a sub ject by forming a subspace of low-lev el filters that represen t the sub ject with v arious facial expressions (forming a basis for the subspace). If this is the only p ooling feature that is asso ciated with the app earance of this sub ject, then the facial expression information is lost to the model represen tation formed by the set of p ool- ing features. As illustrated in our h yp othetical facial expression classification task, this loss of information b ecomes a problem when the information that is lost is necessary to successfully complete the task at hand. Ob viously , what w e really would lik e is for a particu- lar feature set to be inv ariant to the irrelev an t features and disen tangle the relev ant features. Unfortunately , it is often difficult to determine a priori whic h set of features will ultimately be relev ant to the task at hand. F urther, as is often the case in the context of deep learning metho ds ( Collob ert and W eston , 2008 ), the feature set b eing trained ma y b e destined to be used in multiple tasks that may ha ve distinct subsets of relev ant features. Considerations such as these lead us to the conclusion that the most robust approach to feature learning is to disen tangle as man y factors as p ossible, discarding as little information ab out the data as is practical. This is the motiv ation b ehind our prop osed higher-order spike-and-slab Boltzmann ma- c hine. Disen tangling F actors of V ariation via Generative Entangling E ( v , s, f , g , h ) = 1 2 v T Λ v − X k e k f k + X i,k c ik g ik + X j,k d j k h j k + 1 2 X i,j,k α ij k s 2 ij k + X i,j,k − v T W · ,ij k s ij k − α ij k µ ij k s ij k + 1 2 α ij k µ 2 ij k g ik h j k f k , Figure 1. Energy function of our higher-order spik e & slab RBM (ssRBM), used to disentangle (multiplicativ e) factors of v ariation in the data. Two groups of latent spike v ariables, g and h , interact to explain the data v , through the weigh t tensor W . While the ssRBM instantiates a slab v ariable s j for each hidden unit h j , our higher-order mo del emplo ys a slab s ij for eac h pair of spike v ariables ( g i , h j ). µ ij and α ij are respectively the mean and precision parameters of s ij . An additional set of spik e v ariables f are used to gate groups of latent v ariables h , g and serve to promote group sparsity . Most parameters are thus indexed by an extra subscript k . Finally , e , c and d are standard bias terms for v ariables f , g and h , while Λ is a diagonal precision matrix on the visible vector. 3. Higher-order Spik e-and-Slab Boltzmann Mac hines In this section, we introduce a mo del which makes some progress tow ard the am bitious goal of disentan- gling factors of v ariation. The mo del is based on the Boltzmann mac hine, an undirected graphical model. In particular we build on the spike-and-slab restricted Boltzmann Machine (ssRBM) ( Courville et al. , 2011b ), a mo del family that has previously shown promise as a means of learning inv arian t features via subspace p ooling. The original ssRBM mo del p ossessed a lim- ited form of higher-order interaction of tw o laten t ran- dom v ariables: the spike and the slab Our extension adds higher-order in teractions b et w een four distinct laten t random v ariables. These include one set of slab v ariables and three in teracting binary spike v ari- ables. Unlike the ssRBM, the interactions b et w een the latent v ariables violate the conditional indep en- dence constraint of the restricted Boltzmann machine and therefore do es not b elong to this class of models. As a consequence, exact inference in the mo del is not tractable and we resort to a mean-field approximation. Our strategy in promoting this mo del is that w e in- tend to disen tangle factors of v ariation via inference (reco vering the posterior distribution o ver our latent v ariables) in a generative mo del. In the context of generativ e models, inference can roughly be though t of as running the generative pro cess in reverse. Thus if we wish our inference process to disentangle factors of v ariation, our generativ e pro cess should describ e a means of factor entangling. The generative model w e prop ose here represents one possible means of factor en tangling. Let v ∈ R D b e the random visible v ector that rep- resen ts our observ ations with its mean zero ed. W e build a laten t representation of this data with binary laten t v ariables f ∈ { 0 , 1 } K , g ∈ { 0 , 1 } M × K and h ∈ { 0 , 1 } N × K . In the spike-and-slab context, we can think of f , g and h as a factored representation of the “spik e” v ariables. W e also include a set of real v al- ued “slab” v ariables s ∈ R M × N × K , with element s ij k asso ciated with hidden units f k , g ik and h j k . The in- teraction b et ween these v ariables is defined through the energy function of Fig. 1 . The parameters are defined as follows. W ∈ R D × M × N × K is a weigh t 4-tensor connecting visible units to the interacting latent v ariables, these can b e in terpreted as forming a basis in image space; µ ∈ R M × N × K and α ∈ R M × N × K are tensors describ- ing the mean and precision of each s ij k ; Λ ∈ R D × D is a diagonal precision matrix on the visible vector; and finally c ∈ R M × K , d ∈ R N × K and e ∈ R K are bi- ases on the matrices g , h and v ector f respectively . The energy function fully sp ecifies the joint proba- bilit y distribution ov er the v ariables v , s , f , g and h : p ( v, s, f , g , h ) = 1 Z exp {− E ( v , s, f , g , h ) } where Z is the partition function which ensures that the joint distribution is normalized. As sp ecified ab o v e, the energy function is similar to the ssRBM energy function ( Courville et al. , 2011b ; a ), but includes a factored representation of the standard ss- RBM spik e v ariable. Y et, clearly the prop erties of the mo del are highly dep endent on the top ology of the in- teractions b et w een the real-v alued slab v ariables s ij k , and three binary spike v ariables f k , g ik and h j k . W e adopt a strategy that permits lo cal in teractions within small groups of f , g and h in a blo c k-lik e organizational pattern as sp ecified in Fig. 2 . The local blo c k struc- ture allows the mo del to work incrementally to wards disen tangling the features b y fo cusing on manageable subparts of the problem. Similar to the standard spik e-and-slab restricted Boltzmann mac hine ( Courville et al. , 2011b ; a ), the en- ergy function in Eq. 1 gives rise to a Gaussian condi- Disen tangling F actors of V ariation via Generative Entangling Figure 2. Block-sparse connectivit y pattern with dense in- teractions b et ween g and h within each block (only sho wn for k -th blo c k). Each blo c k is gated by a separate f k v ari- able. tional ov er the visible v ariables: p ( v | s, f , g , h ) = N X i,j,k Λ − 1 W · ij k s ij k g ik h j k f k , Λ − 1 Here we hav e a four-wa y m ultiplicative in teraction in the latent v ariables s , f , g and h . The real-v alued slab v ariable s ij k acts to scale the contribution of the w eight vector W · ij k . As a consequence, after marginal- izing out s , the factors f , g and h can also b e seen as con tributing b oth to the conditional mean and condi- tional v ariance of p ( v | f , g , h ): p ( v | f , g , h ) = N X i,j,k Λ − 1 W · ij k µ ij k g ik h j k f k , C v | f ,g ,h C v | f ,g ,h = Λ − X i,j,k W · ij k W T · ij k α − 1 ij k g ik h j k f k − 1 This is an imp ortan t prop ert y of the spike-and-slab framew ork that is also shared by other laten t v ari- able mo dels of real-v alued data such as the mean- co v ariance restricted Boltzmann machine (mcRBM) ( Ranzato and Hin ton , 2010 ) and the mean Pro duct of T-distributions mo del (mP oT) ( Ranzato et al. , 2010 ). F rom a gener ative p erspective, the mo del can b e though t of as consisting of a set of K factor blo c ks whose activity is gated by the f v ariables. Within eac h blo c k, the v ariables g · k and h · k can b e thought of as lo cal latent factors whose in teraction gives rise to the active blo ck’s contribution to the visible v ec- tor. Crucially , the multiplicativ e in teraction b etw een the g · k and h · k for a given block k is mediated by the w eight tensor W · , · , · ,k and the corresponding slab v ari- ables s · , · ,k . Con trary to more standard probabilistic factor models whose factors simply sum to give rise to the visible v ector, the individual con tributions of the elements of g · k and h · k are not easily isolated from one another. W e can think of the generative pro cess as entangling the lo cal blo c k factor activ ations. F rom an enc o ding p erspective, w e are interested in us- ing the p osterior distribution o ver the laten t v ariables as a represen tation or encoding of the data. Unlike in RBMs, in the case of the prop osed mo del where w e hav e higher-order interactions o ver the laten t v ari- ables, the p osterior ov er the latent v ariables does not factorize cleanly . By marginalizing ov er the slab v ari- ables s , we can recov er a set of conditionals describing ho w the binary latent v ariables f , g and h in teract. The conditional P ( f | v , g , h ) is given b elo w. P ( f k = 1 | v , g, h ) = sigm c ik + X i,j v T W · ij k µ ij k g ik h j k + 1 2 X i,j α − 1 ij k v T W · ij k 2 g ik h j k It illustrates that with the factor configuration given in Fig. 2 , the factors f k are activ ated (assume v alue 1) through the sum-po oled response of all the weigh t v ec- tors W · ij k ( ∀ 1 ≤ i ≤ M and 1 ≤ j ≤ N ) differentially gated by the v alues of g ik and h j k , whose conditionals are resp ectiv ely giv en b y: P ( g ik = 1 | v , f , h ) = sigm c ik + N X j v T W · ij k µ ij k h j k f k + 1 2 N X j α − 1 ij k v T W · ij k 2 h j k f k P ( h j k = 1 | v , f , g ) = sigm d j k + M X i v T W · ij k µ ij k g ik f k + 1 2 M X i α − 1 ij k v T W · ij k 2 g ik f k ! F or completeness, we also include the Gaussian condi- tional distribution o ver the slab v ariables s p ( s ij k | v , f , g , h ) = N h α − 1 ij k v T W · ij k · + µ ij k i f k g ik h j k , α − 1 ij k F rom an enco ding persp ective, the gating pattern on the g and h v ariables, evident from Fig. 2 and from Disen tangling F actors of V ariation via Generative Entangling the conditionals distributions, defines a form of lo cal bilinear interaction ( T enenbaum and F reeman , 2000 ). W e can interpret the v alues of g ik and h j k within block k acting as basis indicators, in dimensions i and j , for the linear subspace in the visible space defined by W · ij k s ij k . F rom this p ersp ectiv e, we can think of [ g · k , h · K ] as defining a blo c k-lo cal binary co ordination enco ding of the data. Consider the case illustrated b y Fig. 2 , where w e ha ve M = 5, N = 5 and the n umber of blo c ks ( K ) is 4. F or eac h blo c k, we hav e M × N = 25 filters whic h w e enco de using M + N = 10 binary latent v ariables, where each g ik (alternately h j k ) effectively p ools o ver the subspace characterized by the v ariables h j k , 1 ≤ j ≤ N (alternately g ik , 1 ≤ i ≤ M ) through their relativ e interaction with W · ij k s ij k . As a concrete example, imagine that the structure of the weigh t ten- sor w as such that, along the dimension indexed b y i , the w eigh t v ectors W · ij k form orien ted Gab or-like edge detectors of differen t orientations. Y et along the di- mension indexed by j , the weigh t vectors W · ij k form orien ted Gab or-lik e edge detectors of different colors. In this h yp othetical example, g ik enco des orientation information while being inv ariance to the color of the edge, while h j k enco des color information while b eing in v ariant to orien tation. Hence we could sa y that we ha ve disentangle d the latent factors. 3.1. Higher-order In teractions as a Multi-W ay P o oling Strategy As alluded to ab o v e, one interpretation of the role of g and h is as distinct and complementary sum-p o oled feature sets. Returning to Fig. 2 , we can see that, for eac h blo c k, the g ik p ool across the columns of the k th blo c k, along the i th ro w, while the h · k p ool across ro ws, along the j th column. The f v ariables are also in terpretable as p o oling across all elements of the blo c k. One wa y to in terpret the complemen tary p ooling structures of the g and h is as a multi-w a y p ooling strategy . This particular po oling structure w as c hosen to study the p oten tial of learning the kind of bilinear interaction that exists betw een the g · k and h · k within a block. The f k are present to promote blo c k cohesion by gating the interaction of b et ween g · k and h · k and the visible v ector v . This higher-order structure is of course just one choice of man y p ossible higher-order in teraction architec- tures. One can easily imagine defining arbitrary ov er- lapping p ooling regions, with the num b er of ov erlap- ping p ooling regions sp ecifying the order of the latent v ariable interaction. W e b eliev e that explorations of o verlapping p ooling regions of this type is a promising direction of future inquiry . One potentially in teresting direction is to consider ov erlapping blocks (suc h as our f blo cks). The ov erlap will define a topology o ver the features as they will share lo wer-lev el features (i.e. the slab v ariables). A top ology thus defined could poten- tially b e exploited to build higher-lev el data represen- tations that p ossess local receptiv e fields. These kind of local receptive fields hav e b een sho wn to b e useful in building large and deep mo dels that p erform well in ob ject classification tasks in natural images ( Coates et al. , 2011 ). 3.2. V ariational inference and unsup ervised learning Due to the m ultiplicative in teraction b etw een the la- ten t v ariables f , g and h , computation of P ( f | v ), P ( g | v ) and P ( h | v ) is in tractable. While the slab v ari- ables also in teract multiplicativ ely , w e are able to an- alytically marginalize ov er them. Consequen tly we re- sort to a v ariational approximation of the joint condi- tional P ( f , g , h | v ) with the standard mean-field struc- ture. i.e. we c ho ose Q v ( f , g , h ) = Q v ( f ) Q v ( g ) Q v ( h ) suc h that the KL divergence KL( Q v ( f , g , h ) k P ( f , g , h | v )) is minimized, or equiv alently , that the v ariational low er b ound L ( Q v ) on the log likelihoo d of the data is max- imized: max Q v L ( Q v ) = max Q v X f ,g,h Q v ( f ) Q v ( g ) Q v ( h ) log p ( f , g , h | v ) Q v ( f ) Q v ( g ) Q v ( h ) , where the sums are taken o ver all v alues of the el- emen ts of f , g and h resp ectiv ely . Maximizing this lo wer b ound with resp ect to the v ariational param- eters ˆ f k ≡ Q v ( f k = 1), ˆ g ik ≡ Q v ( g ik = 1) and ˆ h j k ≡ Q v ( h j k = 1), results in the set of approximating factored distributions: ˆ f k = sigm c ik + X i,j v T W · ij k µ ij k ˆ g ik ˆ h j k + 1 2 X i,j α − 1 ij k v T W · ij k 2 ˆ g ik ˆ h j k , ˆ g ik = sigm c ik + N X j v T W · ij k µ ij k ˆ h j k ˆ f k + 1 2 N X j α − 1 ij k v T W · ij k 2 ˆ h j k ˆ f k , Disen tangling F actors of V ariation via Generative Entangling ˆ h j k = sigm d j k + M X i v T W · ij k µ ij k ˆ g ik ˆ f k + 1 2 M X i α − 1 ij k v T W · ij k 2 ˆ g ik ˆ f k ! . The ab o ve equations form a set of fixed p oin t equations whic h we iterate un til the v alues of all Q v ( f k ), Q v ( g ik ) and Q v ( h j k ) conv erge. Since the expression for ˆ f k do es not dep end on ˆ f k 0 , ∀ k 0 , ˆ g ik do es not dep end on ˆ g i 0 k 0 , ∀ i 0 , k 0 , and ˆ h j k do es not dep end on ˆ h j 0 k 0 , ∀ i 0 , k 0 , w e can define a three stage up date strategy where we up date the v alues of all K v alues of ˆ f in parallel, then update all K × M v alues of ˆ g in parallel and finally up date all K × N v alues of ˆ h in parallel. F ollowing the v ariational EM training approac h ( Saul et al. , 1996 ), we alternately maximize the low er b ound L ( Q v ) with resp ect to the v ariational parameters ˆ f , ˆ g and ˆ h (E-step) and maximizing L ( Q v ) with re- sp ect to the mo del parameters (M-step). The gra- dien t of L ( Q v ) with resp ect to the mo del parameters θ = { W, µ, α, Λ , b, c, d, e } is given by: ∂ L ( Q v ) ∂ θ = X f ,g,h Q v ( f ) Q v ( g ) Q v ( h ) E p ( s | v ,f ,g ,h ) − ∂ E ∂ θ + E p ( v ,s,g ,h ) ∂ E ∂ θ , where E is the energy function given in Eq. 1 . As is eviden t from Eq. ?? , the gradien t of L ( Q v ) with re- sp ect to the mo del parameters contains tw o terms: a p ositiv e phase that dep ends on the data v and a neg- ativ e phase, deriv ed from the partition function of the join t p ( v , s, f , g , h ) that do es not. W e adopt a training strategy similar to that of ( Salakhutdino v and Hinton , 2009 ), in that we com bine a v ariational appro ximation of the p ositiv e phase of the gradien t with a blo c k Gibbs sampling-based sto c hastic appro ximation of the nega- tiv e phase. Our Gibbs sampler alternately samples, in parallel, each set of random v ariables, sampling from p ( f | v , g , h ), p ( g | v , f , h ), p ( h | v , f , g ), p ( s | v , f , g , h ), and finally sampling from p ( v | f , g , h, s ). 3.3. The Challenge of Unsup ervised Learning to Disen tangle Ab o v e we hav e briefly outline our pro cedure for train- ing the unsup ervised learning. The web of interac- tions b et ween the laten t random v ariables, particularly those b et ween g and h , mak es the unsupervised learn- ing of the mo del parameters a particularly c halleng- ing learning problem. It is the difficultly of learning that motiv ates our blo c k-wise organization of the in- teractions b et ween the g and h v ariables. The blo c k structure allo ws the interactions b et ween g and h to remain local, with eac h g interacting with relatively few h and each h interacting with relatively few g . This lo cal neigh b orhoo d structure allows the inference and learning pro cedures to b etter manage the com- plexities of teasing apart the laten t v ariable in terac- tions and adapting the model parameters to (approx- imately) maximize lik eliho o d. By using many of these blo c ks of lo cal in teractions we can leverage the known tractable learning prop erties of mo dels suc h as the RBM. Sp ecifically , if w e con- sider each block as a kind of sup er hidden unit gated b y f , then with no in teractions across blo c ks (apart from those mediated by the mutual connections to the visible units) the mo del assumes the form of an RBM. While our c hosen in teraction structure allows our higher-order mo del to b e able to learn, one conse- quence is that the mo del is only capable of disentan- gling relatively local factors that appear within a single blo c k. W e suggest that one promising av enue to ac- complish more extensive disen tangling is to consider stac king multiple version of the prop osed mo del and consider lay er-b y-lay er disentangling of the factors of v ariation presen t in the data. The idea is to start with lo cal disen tangling and mov e gradually to ward disen- tangling non lo cal and more abstract factors. 4. Related W ork The mo del prop osed here w as strongly influenced by previous attempts to disen tangle factors of v ariation in data using latent v ariable mo dels. One of the earlier efforts in this direction also used higher-order interac- tions of latent v ariables, specifically bilinear ( T enen- baum and F reeman , 2000 ; Grimes and Rao , 2005 ) and m ultilinear ( V asilescu and T erzop oulos , 2005 ) mo d- els. One critical difference b et w een these previous attempts to disen tangle factors of v ariation and our metho d is that unlik e these previous metho ds, w e are attempting to learn to disentangle from entirely unsu- p ervised information. In this wa y , one can in terpret our approac h as an attempt to extend the subspace feature po oling approac h to the problem of disentan- gling factors of v ariation. Bilinear models are essentially linear models where the higher-lev el state is factored into the pro duct of t wo v ariables. F ormally , the elements of observ ation x are giv en by x k = P i P j W ij k y i z j , ∀ k , where y i and z j are elemen ts of the tw o factors ( y and z ) representing the observ ation and W ij k is an elemen t of the tensor of mo del parameters ( T enen baum and F reeman , 2000 ). Disen tangling F actors of V ariation via Generative Entangling The tensor W can b e thought of as a generalization of the typical weigh t matrix found in most unsup er- vised mo dels we ha ve considered ab o ve. ( T enenbaum and F reeman , 2000 ) developed an EM-based algorithm to learn the mo del parameters and demonstrated, us- ing images of letters from a set of distinct fonts, that the mo del could disen tangle the st yle (fon t characteris- tics) from con tent (letter iden tity). ( Grimes and Rao , 2005 ) later developed a bilinear sparse co ding mo del of a similar form as describ ed ab o ve but included ad- ditional terms to the ob jective function to render the elemen ts of both y and z sparse. They also require observ ation of the factors in order to train the mo del, and used the mo del to dev elop transformation inv ari- an t features of natural images. Multilinear mo dels are simply a generalization of the bilinear mo del where the n umber of factors that can be comp osed together is 2 or more. ( V asilescu and T erzop oulos , 2005 ) dev elop a m ultilinear ICA mo del, which they use to mo del im- ages of faces, to disentangle factors of v ariation such as illumination, views (orien tation of the image plane relativ e to the face) and iden tities of the p eople. Hin ton et al. ( 2011 ) also propose to disen tangle factors of v ariation by learning to extract features asso ciated with pose parameters, where the changes in p ose pa- rameters (but not the feature v alues) are known at training time. The prop osed mo del is also closely re- lated to recen t work ( Memisevic and Hinton , 2010 ), where higher-order Boltzmann Machines are used as mo dels of spatial transformations in images. While there are a num ber of differences betw een this model and ours, the most significant difference is our use of multiplicativ e interactions b et w een latent v ariables. While they included higher-order interactions within the Boltzmann energy function, they were used exclu- siv ely betw een observed v ariables, dramatically simpli- fying the inference and learning pro cedures. Another ma jor p oin t of departure is that instead of relying on lo w-rank appro ximations to the weigh t tensor, our ap- proac h employs highly structured and sparse connec- tions betw een laten t v ariables (e.g. g ik is not inter- act with or h j k 0 for k 0 6 = k ), reminiscent of recent w ork on structured sparse co ding ( Gregor et al. , 2011 ) and structured l 1-norms ( Bach et al. , 2011 ). As dis- cussed ab ov e, our use of a sparse connection structure allo ws us to isolate groups of interacting latent v ari- ables. Keeping the in teractions lo cal in this wa y , is a k ey comp onen t of our ability to successfully learn using only unsup ervised data. g 1 g 2 h 1 h 2 h 3 h 4 h 5 g 3 Figure 3. (top) Samples from our syn thetic dataset (b efore noise). In each image, a figure “X” can app ear at fiv e differen t positions, in one of eigh t basic colors. Ob jects in a given image must all b e of the same color. (bottom) Filters learnt by a bilinear ssRBM with M = 3, N = 5, whic h succesfully show disen tangling of color information (ro ws) from p osition (columns). 5. Exp erimen ts 5.1. T o y Exp erimen t W e sho wcase the ability of our mo del to disentan- gle factors of v ariation, b y training it on a syn thetic dataset, a subset of whic h is shown in Fig. 3 (top). Eac h color image, of size 3 × 20 is comp osed of one basic ob ject of v arying color, which can app ear at five differen t positions. The constrain t is that all ob jects in a giv en image must b e of the same color. Additive gaussian noise is sup er-imposed on the resulting im- ages to facilitate mixing of the RBM negative phase. A bilinear ssRBM with M = 3 and N = 5 should in theory ha v e the capacit y to disentangle the tw o factors of v ariation present in the data, as there are 2 3 p os- sible colors and 2 5 configurations of ob ject placement. The resulting filters are shown in Fig. 3 (b ottom): the mo del has succesfully learn t a binary encoding of color along g -units (ro ws) and positions along h (columns). Note that this would hav e b een extremely difficult to p erform without multiplicativ e in teractions of latent v ariables: an RBM with 15 hidden units technically has the capacit y to learn similar filters, how ever it w ould b e incapable of enforcing m utual exclusivit y b e- t ween hidden units of different color. The bilinear ss- RBM mo del on the other hand generates near-p erfect samples (not shown), while factoring the representa- tion for use in deep er la yers. 5.2. T oron to F ace Dataset W e ev aluate our model on the recen tly in tro duced T oronto F ace Dataset (TFD) ( Susskind et al. , 2010 ), whic h con tains a large n umber of black & white 48 × 48 prepro cessed facial images. These span a wide range of identities and emotions and as suc h, the dataset Disen tangling F actors of V ariation via Generative Entangling is well suited to study the problem of disen tangling: mo dels whic h can successfully separate identit y from emotion should p erform well at the supervised learn- ing task, which inv olves classifying images in to one of seven categories: { anger, disgust, fear, happy , sad, surprise, neutral } . The dataset is divided in to tw o parts: a large unlabeled set (mean t for unsup ervised feature learning) and a smaller lab eled set. Note that emotions app ear m uc h more prominently in the latter, since these are acted out and thus prone to exaggera- tion. In con trast, most of the unlab eled set contains natural expressions o ver a wider range of individuals. In the course of this w ork, we hav e made several key refinemen ts to the original spike-and-slab formulation. Notably , since the slab v ariables { s ij k ; ∀ j } can b e in- terpreted as coordinates in the subspace of the spike v ariable g ik (whic h spans the set of filters { W · ,ij k , ∀ j } ), it is natural for these filters to be unit-norm. Eac h maxim um likelihoo d gradient up date is thus follow ed b y a pro jection of the filters onto the unit-norm ball. Similarly , there exists an ov er-parametrization in the direction of W · ,ij k and the sign of µ ij k , the parame- ter con trolling the mean of s ij k . W e th us constrain µ ij k to b e p ositiv e, in our case greater than 1. Sim- ilar constraints are applied on B and α to ensure that the v ariances on the visible and slab v ariables re- main b ounded. While previous work ( Courville et al. , 2011a ) used the exp ected v alue of the spike v ariables as the input to classifiers, or higher-lay ers in deep net- w orks, we found that the ab o ve re-parametrization consisten tly lead to b etter results when using the prod- uct of exp ectations of h and s . F or po oled mo dels, we simply take the pro duct of each binary spike, with the norm of its asso ciated slab v ector. Disen tangling Emotion from Identit y . W e b e- gin with a qualitative ev aluation of our mo del, by vi- sualizing the learned filters (inner-most dimension of the matrix W ) and po oling structures. W e trained a mo del with K = 100 and M = N = 5 (that is to sa y 100 blo c ks of 5 × 5 in teracting g and h units) on a weigh ted com bination of the labeled and unlab eled training sets. Doing so (as opposed to training on the unlab eled set only) allo ws for greater in terpretability of the results, as emotion is a more prominent factor of v ariation in the lab eled set). The results, sho wn in Figure 4 , clearly sho w global cohesion within blocks p ooled b y f k , with ro w and column structure corre- lating with v ariances in app earance/identit y and emo- tions. Disen tangling via Unsup ervised F eature Learn- ing. W e now ev aluate the representation learn t by our disen tangling RBM, by measuring its usefulness for Figure 4. Example blocks obtained with K = 100, M = N = 5. The filters (inner-most dimension of tensor W ) in eac h blo c k exhibit global cohesion, sp ecializing themselves to a subset of identities and emotions: { happiness, fear, neutral } in (left) and { happiness, anger } in (righ t). In both cases, g -units (which p ool ov er columns) encode emotions, while h -units (which p ool ov er rows) are more closely tied to identit y . the task of emotion recognition. Our main ob jective here is to ev aluate the usefulness of disentangling, o ver traditional approaches of p o oling, as w ell as the use of larger, unp o oled mo dels. W e thus consider ssRBMs with 3000 and 5000 features, with either (i) no p ool- ing (i.e. K = 5000 spik es with N = 1 slabs p er spike), (ii) p o oling along a single dimension (i.e. K = 1000 spik e v ariables, p o oling N = 5 slabs) or (iii) disen tan- gled through our higher-order ssRBM (i.e. K = 200, with g and h units arranged in a M × N grid, with M = N = 5). W e follow ed the standard TFD training proto col of p erforming unsupervised training on the unlabeled set, and then using the learn t representation as input to a linear SVM, trained and cross-v alidated on the lab eled set. T able 1 sho ws the test accuracy obtained b y v ar- ious spike-and-slab mo dels, av eraged ov er the 5-folds. W e rep ort tw o sets of n umbers for mo dels with p ool- ing or disen tangling: one where we use the “factored represen tation”, whic h is the elemen t-wise pro duct of spike v ariables with the norm of their asso ciated slab vector, and the “unfactored representation”: the higher-dimensional represen tation formed b y consider- ing all slab v ariables, each m ultiplied b y their asso ci- ated spikes. W e can see that the higher-order ssRBM ac hieves the b est result: 77 . 4%, using the factored representation. The fact that that our mo del outp erforms the “un- factored” one, confirms our disentangling hypothesis: our mo del has successfully learn t a low er-dimensional (factored) representation of the data, useful for clas- sification. F or reference, a linear SVM classifier on the pixels achiev es 71 . 5% ( Susskind et al. , 2010 ), an Disen tangling F actors of V ariation via Generative Entangling F actored Unfactored Mo del K M N v alid test v alid test ssRBM 3000 1 n/a n/a 76.0% 75.7% ssRBM 999 3 72.9% 74.4% 74.9% 73.5% hossRBM 330 3 3 76.0% 75.7% 75.3% 75.2% hossRBM 120 5 5 71.4% 70.7% 74.5% 74.2% ss-RBM 5000 1 n/a n/a 76.7% 76.3% ss-RBM 1000 5 74.2% 74.0% 75.9% 74.6% hossRBM 555 3 3 77.6% 77.4% 76.2% 75.9% hossRBM 200 5 5 73.3% 73.3% 75.6% 75.3% T able 1. Classification accuracy for T oron to F ace Dataset. W e compare our higher-order ssRBM for v arious blo c k sizes K and p ooling regions M × N . The comparison is against first-order ssRBMs, which thus p o ol in a single dimension of size N . First four mo dels contain approximately 3 , 000 filters, while b ottom four contain 5 , 000. In b oth cases, we compare the effect of using the factored representation, to the unfactored representation. MLP trained with sup ervised backprop 72 . 72% 1 , while a deep mP oT mo del ( Ranzato et al. , 2011 ), whic h ex- ploits lo cal receptive fields ac hieves 82 . 4%. 6. Conclusion W e hav e presented a higher-order extension of the spik e-and-slab restricted Boltzmann machine that fac- tors the standard binary spike v ariable into three in- teracting factors. F rom a generative p ersp ectiv e, these in teractions act to entangle the factors represented by the laten t binary v ariables. Inference is in terpreted as a pro cess of disen tangling the factors of v ariation in the data. As previously mentioned, we b eliev e an imp or- tan t direction of future researc h to b e the exploration of methods to gradually disen tangle the factors of v ari- ation by stacking m ultiple instantiations of prop osed mo del in to a deep arc hitecture. References F. Bach, R. Jenatton, J. Mairal, and G. Ob ozinski. Struc- tured sparsity through con vex optimization. CoRR , abs/1109.2397, 2011. A. Coates, H. Lee, and A. Y. Ng. An analysis of single-la yer net works in unsup ervised feature learning. In Pr o c e e d- ings of the Thirte enth International Confer enc e on Arti- ficial Intel ligenc e and Statistics (AIST A TS 2011) , 2011. R. Collobert and J. W eston. A unified architecture for natural language processing: Deep neural netw orks with m ultitask learning. In W. W. Cohen, A. McCallum, and S. T. Ro w eis, editors, ICML 2008 , pages 160–167. A CM, 2008. A. Courville, J. Bergstra, and Y. Bengio. Unsup er- vised mo dels of images by spike-and-slab RBMs. In ICML’2011 , 2011a. A. Courville, J. Bergstra, and Y. Bengio. A Spik e and 1 Salah Rifai, p ersonal communication. Slab Restricted Boltzmann Mac hine. In AIST A TS’2011 , 2011b. K. Gregor, A. Szlam, and Y. LeCun. Structured sparse co ding via lateral inhibition. In A dvanc es in Neur al In- formation Pro c essing Systems (NIPS 2011) , volume 24, 2011. D. B. Grimes and R. P . Rao. Bilinear sparse co ding for in v ariant vision. Neur al c omputation , 17(1):47–73, Jan- uary 2005. G. Hin ton, A. Krizhevsky , and S. W ang. T ransforming auto-enco ders. In ICANN’2011: International Confer- enc e on A rtificial Neur al Networks , 2011. A. Hyv¨ arinen and P . Hoy er. Emergence of phase and shift in v ariant features by decomp osition of natural images in to indep enden t feature subspaces. Neur al Computa- tion , 12(7):1705–1720, 2000. K. Ka vukcuoglu, M. Ranzato, R. F ergus, and Y. LeCun. Learning inv ariant features through topographic filter maps. In Pr o c e e dings of the Computer Vision and Pat- tern R e c o gnition Confer enc e (CVPR’09) , pages 1605– 1612. IEEE, 2009. T. Kohonen. Emergence of inv arian t-feature detectors in the adaptive-subspace self-organizing map. Biolo gic al Cyb ernetics , 75:281–291, 1996. ISSN 0340-1200. T. Kohonen, G. Nemeth, K.-J. Bry , M. Jalank o, and H. Ri- ittinen. Spectral classification of phonemes by learning subspaces. In ICASSP ’79. , volume 4, pages 97 – 100, 1979. Q. Le, J. Ngiam, Z. Chen, D. J. hao Chia, P . W. Koh, and A. Ng. Tiled conv olutional neural netw orks. In NIPS’2010 , 2010. Y. LeCun, L. D. Jack el, B. Boser, J. S. Denker, H. P . Graf, I. Guyon, D. Henderson, R. E. Ho ward, and W. Hub- bard. Handwritten digit recognition: Applications of neural netw ork chips and automatic learning. IEEE Communic ations Magazine , 27(11):41–46, No v. 1989. Disen tangling F actors of V ariation via Generative Entangling R. Memisevic and G. E. Hinton. Learning to represen t spatial transformations with factored higher-order b oltz- mann machines. Neur al Computation , 22(6):1473–1492, June 2010. M. Ranzato and G. H. Hin ton. Mo deling pixel means and co v ariances using factorized third-order Boltzmann ma- c hines. In CVPR’2010 , pages 2551–2558, 2010. M. Ranzato, V. Mnih, and G. Hinton. Generating more realistic images using gated MRF’s. In NIPS’2010 , 2010. M. Ranzato, J. Susskind, V. Mnih, and G. Hin ton. On deep generativ e mo dels with applications to recognition. In CVPR’2011 , 2011. R. Salakhutdino v and G. Hinton. Deep Boltzmann ma- c hines. In AIST A TS’2009 , v olume 5, pages 448–455, 2009. L. K. Saul, T. Jaakkola, and M. I. Jordan. Mean field theory for sigmoid b elief netw orks. Journal of Artificial Intel ligenc e R ese ar ch , 4:61–76, 1996. J. Susskind, A. Anderson, and G. E. Hinton. The Toronto face dataset. T echnical Rep ort UTML TR 2010-001, U. T oronto, 2010. J. B. T enenbaum and W. T. F reeman. Separating style and conten t with bilinear mo dels. Neur al Computation , 12(6):1247–1283, 2000. M. A. O. V asilescu and D. T erzop oulos. Multilinear inde- p enden t components analysis. In CVPR’2005 , v olume 1, pages 547–553, 2005. H. W ang, M. M. Ullah, A. Kl¨ aser, I. Laptev, and C. Schmid. Ev aluation of local spatio-temp oral features for action recognition. In British Machine Vision Con- fer enc e (BMVC) , pages 127–127, London, UK, Septem- b er 2009.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment