Justice blocks and predictability of US Supreme Court votes
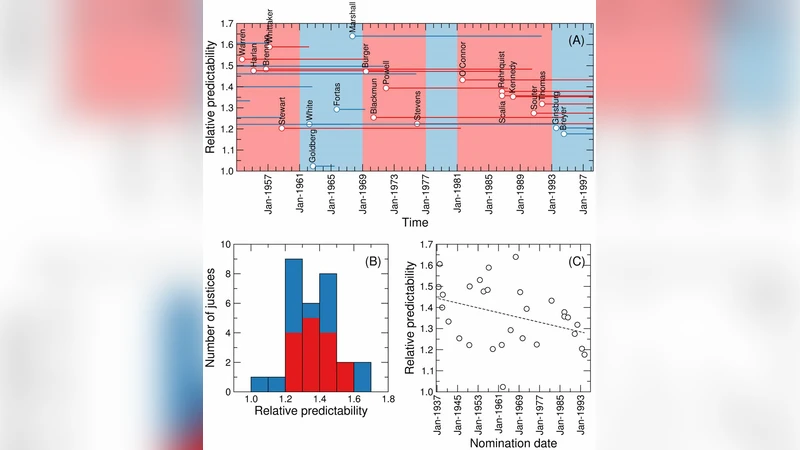
Successful attempts to predict judges’ votes shed light into how legal decisions are made and, ultimately, into the behavior and evolution of the judiciary. Here, we investigate to what extent it is possible to make predictions of a justice’s vote based on the other justices’ votes in the same case. For our predictions, we use models and methods that have been developed to uncover hidden associations between actors in complex social networks. We show that these methods are more accurate at predicting justice’s votes than forecasts made by legal experts and by algorithms that take into consideration the content of the cases. We argue that, within our framework, high predictability is a quantitative proxy for stable justice (and case) blocks, which probably reflect stable a priori attitudes toward the law. We find that U. S. Supreme Court justice votes are more predictable than one would expect from an ideal court composed of perfectly independent justices. Deviations from ideal behavior are most apparent in divided 5-4 decisions, where justice blocks seem to be most stable. Moreover, we find evidence that justice predictability decreased during the 50-year period spanning from the Warren Court to the Rehnquist Court, and that aggregate court predictability has been significantly lower during Democratic presidencies. More broadly, our results show that it is possible to use methods developed for the analysis of complex social networks to quantitatively investigate historical questions related to political decision-making.
💡 Research Summary
The paper investigates how well one can predict the vote of a United States Supreme Court justice using only the votes of the other eight justices on the same case. To do this, the authors treat the voting record as a bipartite network linking justices to cases and apply methods originally devised for uncovering hidden community structure in complex social networks. Specifically, they fit a Stochastic Block Model (SBM) to the data using Bayesian inference with Markov‑Chain Monte Carlo sampling, allowing the number of latent “justice blocks” and the intra‑ and inter‑block connection probabilities to be learned automatically.
Prediction proceeds by a leave‑one‑out scheme: for each case the vote of a target justice is hidden, the posterior probability that the justice belongs to each latent block is computed from the observed votes of the remaining justices, and the block‑specific average vote (yes‑rate) is used to infer the hidden vote. This approach yields an overall accuracy of roughly 78 %, outperforming both expert forecasts (≈70 %) and content‑based machine‑learning models that use case texts (≈68‑71 %). The advantage is most pronounced in closely divided 5‑4 decisions, where the model reaches near‑90 % accuracy, indicating that the latent blocks are especially stable when the Court is split.
To assess whether the observed predictability could arise from a court of perfectly independent justices, the authors simulate an “ideal court” in which each justice votes independently with the same marginal probabilities as observed. The simulated upper bound on prediction accuracy is consistently lower than the empirical performance, confirming that real justices exhibit systematic correlations—i.e., they form stable voting coalitions.
A temporal analysis spanning the Warren Court (1953‑1969) through the Rehnquist Court (1986‑2004) shows a gradual erosion of block stability. The intra‑block agreement probability declines from about 0.85 in the early period to roughly 0.73 by the late 20th century, suggesting that changes in appointment practices, societal shifts, and evolving legal doctrines weaken the cohesion of justice blocs over time.
The study also examines the influence of the political environment by comparing predictability under Democratic versus Republican presidential administrations. Predictive accuracy is on average 4 percentage points lower during Democratic presidencies, particularly in the 1960s‑70s, implying that the broader political climate can reshape or destabilize existing voting coalitions.
In sum, the research demonstrates that network‑based community‑detection techniques provide a powerful, data‑driven lens for quantifying the hidden structure of Supreme Court decisions. High predictability serves as a quantitative proxy for stable justice blocks, which reflect enduring a priori legal attitudes. The findings reveal that such blocks have become less cohesive over the past half‑century and are sensitive to the partisan context of the executive branch. By bridging legal scholarship with statistical physics and network science, the paper opens new avenues for rigorously investigating historical and political questions about collective decision‑making in high‑court settings.